







 本文深入介绍了SIMD256技术,特别是AVX2指令集如何提升C++代码的执行效率。通过immintrin库,展示了如何使用_mm256系列API进行并行计算,例如计算π的例子,将传统逐个累加的方法优化为SIMD256操作,显著减少了计算时间。同时,详细解析了如_mm256_set1_pd等函数的用途,并提供了针对不同基本数据类型的API使用示例,如uint8_t和uint16_t。
本文深入介绍了SIMD256技术,特别是AVX2指令集如何提升C++代码的执行效率。通过immintrin库,展示了如何使用_mm256系列API进行并行计算,例如计算π的例子,将传统逐个累加的方法优化为SIMD256操作,显著减少了计算时间。同时,详细解析了如_mm256_set1_pd等函数的用途,并提供了针对不同基本数据类型的API使用示例,如uint8_t和uint16_t。
目录
SIMD256技术 & AVX2指令集
什么是SIMD,Single Instruction Multiple Data,单指令多数据。
什么是SIMD256技术,就是CPU同时对256bit的数据进行读写或者运算。
256 bit = 32 Bytes,一般的,double占8个字节,float和int占4个字节,char占1个字节
那么 256 bit = 4 double = 8 float = 8 int = 32 char
那么就是说可以同时读写操作4个double,或者8个float,或者8个int,或者32个char
C++的immintrin库

这就有点像烤面包,我们不是一个面包一个面包的进行烤制,而是同时烤十几个,这样的效率肯定是会更高。

关于immintrin的api使用,可以查看官方文档:
使用immintrin的api和数据结构
举个例子:计算pi
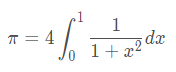
正常的写法是逐个累加计算:
//正常的逐个累加运算
double compute_pi_naive(size_t dt) {
double pi = 0.0;
double delta = 1.0 / dt;
for (size_t i = 0; i < dt; i++) {
double x = (double)i / dt;
pi += delta / (1 + x * x);
}
return pi * 4.0;
}其中,dt 是指 [ 0 , 1 ] 被分为多少份。我们可以设置 dt 尽可能大,已逼近连续积分的结果,比如dt = 134217728
那么,如果我们使用immintrin,则
#include<immintrin.h>
double compute_pi_sim256(size_t dt) {
double pi = 0.0;
double delta = 1.0 / dt;
__m256d ymm0, ymm1, ymm2, ymm3, ymm4;
ymm0 = _mm256_set1_pd(1.0);
ymm1 = _mm256_set1_pd(delta);
ymm2 = _mm256_set_pd(0.0, delta, delta * 2, delta * 3);
ymm4 = _mm256_setzero_pd();
for (int i = 0; i < dt - 4; i += 4) {
ymm3 = _mm256_set1_pd(i*delta);
ymm3 = _mm256_add_pd(ymm3, ymm2);// 构造 x
ymm3 = _mm256_mul_pd(ymm3, ymm3);// 构造 x^2
ymm3 = _mm256_add_pd(ymm0, ymm3);// 构造 1 + x^2
ymm3 = _mm256_div_pd(ymm1, ymm3);// 构造 delta / ( 1 + x^2 )
ymm4 = _mm256_add_pd(ymm4, ymm3);// 叠加结果
}
double tmp[4];
_mm256_store_pd(tmp, ymm4);
pi += tmp[0] + tmp[1] + tmp[2] + tmp[3];
return pi * 4.0;
}这是一段针对double数据的simd256代码,
用到的数据结构是`__m256d`,这意味着这256bit是装着4个double数据。
结果对比:
#include <iostream>
#include <ctime>
#include<immintrin.h>
int main() {//test_cal_pi
clock_t start, end;
size_t dt = 134217728;
double result1, result2;
//普通函数计时
start = clock();
result1 = compute_pi_naive(dt);
end = clock();
cout << "naive: " << result1 << " use time: " << end - start << endl;
//simd256计时
start = clock();
result2 = compute_pi_sim256(dt);
end = clock();
cout << "simd256: " << result2 << " use time: " << end - start << endl;
return 0;
}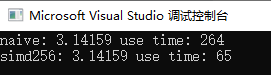
同样的结果,simd256将时间减少了75.3%
接下来,我们对每一个api进行解析:
这里我能找到的就是_mm系列的,这个系列只能支持simd128,而不是simd256,但是其实整体的思路都差不多,因此也可以当作我们使用simd256的文档,如果又找到了我会发出来。
immintrin的api解析
_mm256_set1_pd

设置一个`double`数据给一个`__m256d`,那么会自动复制为4份
_mm256_set_pd

准确地给出每一个double的值。
假设是simd128,则设置2个double;如果是simd256,则设置4个double。
_mm256_setzero_pd
_mm_setzero_pd | Microsoft Docs

设置值为0
_mm256_add_pd

两个数相加
_mm256_mul_pd
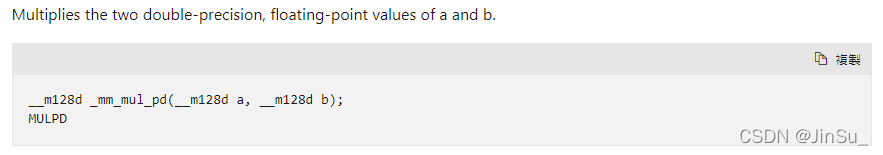
两个数相乘
_mm256_div_pd
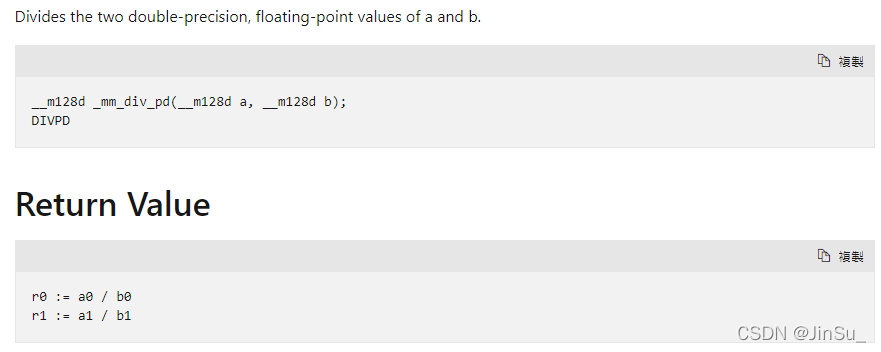
两个数相除,a除以b,value = a / b
_mm256_store_pd

将一个`__m256d`存放在指定double指针指向的地址
提示:这里的double指针指向的地址必须是对齐32位的
_mm256_load_pd

从double指针指向的地址读取256bit数据,存放在`__m256d`中。
以上是对于基本类型double的基本操作了,对于float类型来说,只要把pd改为sd就可以。
基本数据类型(uint8_t, uint16_t 等)
而对于其他的基本数据类型(uint8_t, uint16_t 等),immintrin提供不同的数据结构和api接口:
对于`uint8_t`类型
typedef uint8_t pixeltype; // 无符号8位整数
typedef __m256i simd256type;
#define simd256_set1(_value) (_mm256_set1_epi8(_value))
#define simd256_store(_index,_value) (_mm256_storeu_si256(_index,_value))
#define simd256_load(_index) (_mm256_loadu_si256(_index))
#define simd256_min(_value1,_value2) (_mm256_min_epu8(_value1,_value2))
#define simd256_add(_value1,_value2) (_mm256_add_epi8(_value1,_value2))
#define simd256_sub(_value1,_value2) (_mm256_sub_epi8(_value1,_value2))
#define MAX_VALUE UINT8_MAX这里使用的数据结构是 `__mm256i`,不论是有符号还是无符号,都是用这一个 。
对于store,load,或者其他算术运算则会用是否带 `u` 进行区分。
_mm256_storeu_si256
_mm_storeu_si128 | Microsoft Docs

将一个`__m256i`存放在指定__m256i*指针指向的地址。
这里我们一般不会创建__m256i[]数组,而是char[]或者uint8_t[]数组。
然后在存放的时候进行强制类型转换,比如:
uint8_t index[32];
__m256i c0;
_mm256_storeu_si256((__m256i*)index, c0);如果是操作有符号的int8_t,则得用_mm256_store_si256
_mm256_loadu_si256
_mm_loadu_si128 | Microsoft Docs

加载一个`__m256i`,同样地对地址进行强制类型转换。
uint8_t index[32];
__m256i c0;
c0 = _mm256_loadu_si256((__m256i*)index);如果是操作有符号的int8_t,则得用_mm256_load_si256
对于`uint16_t`类型
typedef uint16_t pixeltype; // 无符号8位整数
typedef __m256i simd256type;
#define simd256_set1(_value) (_mm256_set1_epi16(_value))
#define simd256_store(_index,_value) (_mm256_storeu_si256(_index,_value))
#define simd256_load(_index) (_mm256_loadu_si256(_index))
#define simd256_min(_value1,_value2) (_mm256_min_epu16(_value1,_value2))
#define simd256_add(_value1,_value2) (_mm256_add_epi16(_value1,_value2))
#define simd256_sub(_value1,_value2) (_mm256_sub_epi16(_value1,_value2))
#define MAX_VALUE UINT16_MAX
















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









