






1.问题描述
给定一个数据集![]() ,假设其满足样本间独立同分布。本质上,我们希望得到关于该数据集的真实的概率分布p(x),虽然有一些方法能够直接估计p(x)中某一点的概率(例如核密度估计、近邻方法),但这些方法一方面准确性较差,并且随着样本维度的升高,对样本数量的需求也是指数增加的。简单来说,我们多数情况下无法知道p(x)。
,假设其满足样本间独立同分布。本质上,我们希望得到关于该数据集的真实的概率分布p(x),虽然有一些方法能够直接估计p(x)中某一点的概率(例如核密度估计、近邻方法),但这些方法一方面准确性较差,并且随着样本维度的升高,对样本数量的需求也是指数增加的。简单来说,我们多数情况下无法知道p(x)。
那么换一个思路,假设每个样本是由一组潜在的因素决定,这些因素我们很难明确他们的含义,但他们确确实实地决定这些样本的分布,令这些隐变量为z。需要说明的是,有些时候,隐变量是一个确定的值,但在贝叶斯理论下,这些隐变量是一组随机变量,他们也存在着各自对应的概率分布。
通过上边的描述,我们可知,隐变量z决定这随机变量x的概率分布,其概率图模型如下:
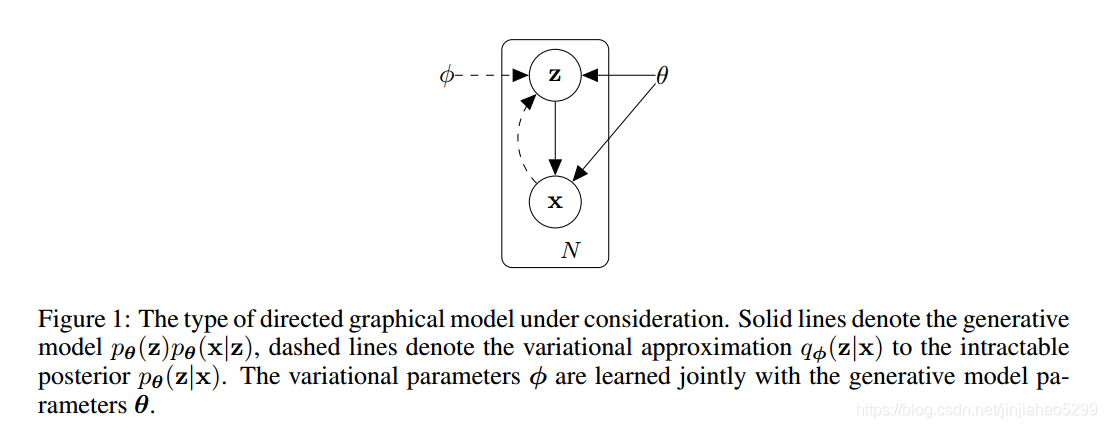
当我们只关注上图中的z,x和他们之间的实线箭头,可知:
![]()
上式中,p(z)表示隐变量z的概率分布,可知,对任意一个x的概率,都需要遍历所有z的取值,这一复杂度随z的维度指数上升,并且,我们也不知道z的真实分布是什么样子的。
这里,就可以利用贝叶斯的方法对z的分布进行估计,即VAE首先令z的先验分布p(z)为标准高斯分布,之后,基于观测到的X,计算其后验分布p(z|x)来估计z的真实分布。而对后验分布![]() 的估计,也正是VAE的核心。注:原文中通过最大化p(X)对数似然,推导得出等价于优化变分下界,角度不同,本质一样。
的估计,也正是VAE的核心。注:原文中通过最大化p(X)对数似然,推导得出等价于优化变分下界,角度不同,本质一样。
2.问题建模
为了估计![]() ,VAE假设存在一个分布
,VAE假设存在一个分布![]() ,令q不断近似p,即最小化
,令q不断近似p,即最小化![]() ,从而将一个估计问题转化为一个优化问题,这一过程本质上是一个变分推断的过程,所以VAE不叫AE。接下来,具体来看如何优化
,从而将一个估计问题转化为一个优化问题,这一过程本质上是一个变分推断的过程,所以VAE不叫AE。接下来,具体来看如何优化![]() .
.

基于上述推导,将p(z)=N(0,I)带入上式,并变换一下可得:
![]()

3.求解优化目标1——![]()
首先,需要明确VAE中直接认为![]() 服从各分量相互独立的多元高斯分布,所以
服从各分量相互独立的多元高斯分布,所以
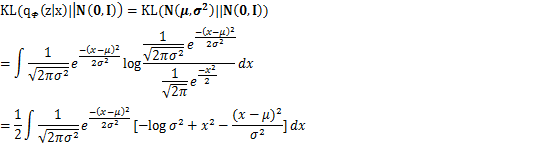
上述积分可拆成三个积分,其中,第一项是概率密度乘一个和x无关的常数![]() ,即对概率密度积分,结果为1,
,即对概率密度积分,结果为1,

第二项是正态分布的二阶矩,

第三项
-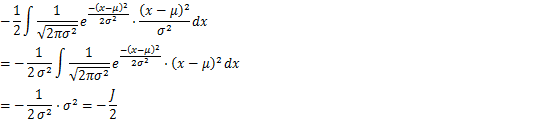
其中J为因变量z的维数综上所述,
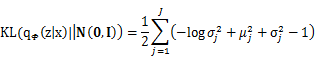
4.求解优化目标2——![]()
而另一项,也就是![]() ,理论上来说,对它的计算也是要计算如下积分的
,理论上来说,对它的计算也是要计算如下积分的
![]()
但通过一种叫重参数的技巧(reparameterization trick),可以构造一个简单的式子作为![]() 的近似值。
的近似值。

![]()
这样一来,得到了如下形式
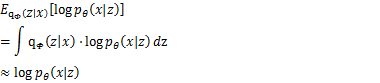

- Bernouli分布建模x
将x看做一组服从Bernouli分布的随机变量,pθx|z![]() 输出的是一组Bernouli分布的参数,假设为y,对于x中的某个分量xi
输出的是一组Bernouli分布的参数,假设为y,对于x中的某个分量xi![]() ,存在着y中的一个分量yi
,存在着y中的一个分量yi![]() 与之对应。可知,
与之对应。可知,
![]()
![]()
同一表达在一个式子中,就是
![]()
所以,有

其中,D为数据的分量个数。
- Gaussian分布建模x
将x看做一组服从Gaussian分布的随机变量,![]() 输出的是多元高斯分布的均值与方差,假设分别为μ和σ,则
输出的是多元高斯分布的均值与方差,假设分别为μ和σ,则
![]()
5.一些实现细节
按照论文中的模型,模型![]() 均为包含一个隐层的神经网络,其中模型
均为包含一个隐层的神经网络,其中模型![]() 以x为输入,输出一组μ和
以x为输入,输出一组μ和![]() ,这里之所以输出
,这里之所以输出![]() 而不是
而不是![]() ,是因为
,是因为![]() 是非负的,这就需要对网络加一些限制,为了方便,改为
是非负的,这就需要对网络加一些限制,为了方便,改为![]() ,从而正负都可以变换为方差。
,从而正负都可以变换为方差。
参考:
https://www.zhihu.com/question/41765860
https://blog.csdn.net/u012356619/article/details/102588314
https://github.com/wiseodd/generative-models/tree/master/VAE/vanilla_vae















 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









