







 本文详细介绍了多元线性回归的参数估计方法,包括梯度下降法和正规方程。阐述了代价函数的概念及其在梯度下降法中的应用,探讨了规范化在解决过度拟合和稀疏矩阵问题中的作用,并展示了规范化后的梯度下降过程和正规方程。内容涵盖线性回归模型的构建、误差项的正态分布假设以及极大似然估计。
本文详细介绍了多元线性回归的参数估计方法,包括梯度下降法和正规方程。阐述了代价函数的概念及其在梯度下降法中的应用,探讨了规范化在解决过度拟合和稀疏矩阵问题中的作用,并展示了规范化后的梯度下降过程和正规方程。内容涵盖线性回归模型的构建、误差项的正态分布假设以及极大似然估计。
多元线性回归的表现形式是 (1) h θ ( x ) = y = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_\theta(x)=y=\theta_0 + \theta_1x_1 + \theta_2x_2+...+\theta_nx_n \tag{1} hθ(x)=y=θ0+θ1x1+θ2x2+...+θnxn(1)
其中 x 1 . . . x n x_1...x_n x1...xn是 n n n个变量, θ 0 . . . θ n \theta_0...\theta_n θ0...θn是 n + 1 n+1 n+1个参数。 h h h是hypothesis的简称。如果定义 x 0 = 1 x_0 = 1 x0=1,(1)式可以变为(2)式:
(2) h θ ( x ) = y = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_\theta(x)=y=\theta_0x_0 + \theta_1x_1 + \theta_2x_2+...+\theta_nx_n \tag{2} hθ(x)=y=θ0x0+θ1x1+θ2x2+...+θnxn(2)
其中 x 0 = 1 x_0 = 1 x0=1.
令: X = [ x 0 x 1 ⋮ x n ] , Θ = [ θ 0 θ 1 ⋮ θ n ] X = \begin{bmatrix} x_0 \\ x_1 \\ \vdots \\ x_n \end{bmatrix}, \Theta = \begin{bmatrix} \theta_0 \\ \theta_1 \\ \vdots \\ \theta_n \end{bmatrix} X=⎣⎢⎢⎢⎡x0x1⋮xn⎦⎥⎥⎥⎤,Θ=⎣⎢⎢⎢⎡θ0θ1⋮θn⎦⎥⎥⎥⎤
(2)式可简记为(3)式:
(3) h θ ( x ) = Θ T X h_\theta(x) = \Theta^{\rm T}X \tag{3} hθ(x)=ΘTX(3)
例如下表,我们要根据房屋属性预测房屋价格。那么在该例中,一共有4个属性,分别是Size, Number of bedrooms, Number of floors, Age of home,表示为 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4. Price是要预测的值,即 y y y,这里表示为 h θ ( x ) h_\theta(x) hθ(x).
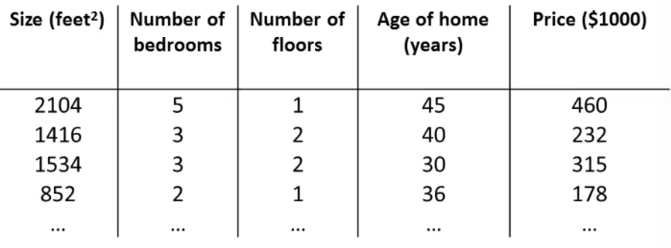
上表中有很多行,每一行称为一个训练样本(training example/sample). 为方便描述,定义以下符号:
n n n: 属性数量
m m m: 训练样本数量
x ( i ) x^{(i)} x(i): 第 i i i个训练样本的属性
x j ( i ) x^{(i)}_j xj(i): 第 i i i个训练样本的第 j j j个属性
从(3)式可知,如果我们知道了参数矩阵 Θ T \Theta^{\rm T} ΘT的每一个值,就可以用方程(3)来预测未知样本的值。如何求得 Θ T \Theta^{\rm T} ΘT?机器学习中的一个重要任务就是估计 Θ T \Theta^{\rm T} ΘT. 足够好的 Θ T \Theta^{\rm T} ΘT必定会使得预测值无限接近于真实值,如果设计一个关于 Θ T \Theta^{\rm T} ΘT的函数用来表示预测值与真实值之间的差异,那么求得一个足够小的差异,就可以解出 Θ T \Theta^{\rm T} ΘT,这个函数通常成为代价函数(cost function),简记为 J ( θ ) J(\boldsymbol{\theta}) J(θ).
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1838
1838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









