







Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
Agent调优的数据设计和方法
论文摘要
在将代理能力整合到目前通用的LLM中,存在以下3个问题:
(1)目前的Agent训练语料库既包含了格式遵循又包含了一般推理,这显著偏离了其预训练数据的分布。比如迅速拟合特定格式,未能充分学习训练数据中嵌入的推理能力,从而导致性能不佳
(2)LLM在不同Agent任务的学习速度不同:难度从易到难依次是 指令遵循<检索/理解<推理
(3)现有方法在改善Agent能力时引入了幻觉问题:a.响应时忽略了用户生成的查询,刻板的遵循训练形式 b.面对诱导性问题,容易乱答
本文贡献:
(1)通过对训练预料的分析和重构,Agent-FLAN方法使得Llama2-7B提高了3.5%的性能
(2)通过构建负样本,Agent-FLAN方法缓解了幻觉问题
(3)此方法同样适用于更大规模的模型,且增强了LLM的通用能力
核心思想:将Agent训练数据中的格式遵循和通用推理分离,使得微调过程更贴近模型原始的预训练领域——自然对话。
Agent-FLAN通过将代理任务进一步分解为LLM的基本能力的不同方面,如指令遵循、推理、检索和理解,提供了根据各能力不同学习速率的训练灵活性。此外,为了全面解决代理任务中的幻觉问题,Agent-FLAN构建了Agent-H基准测试,并精心策划了多样化的“负面”训练样本以有效缓解这一问题。
具体方法
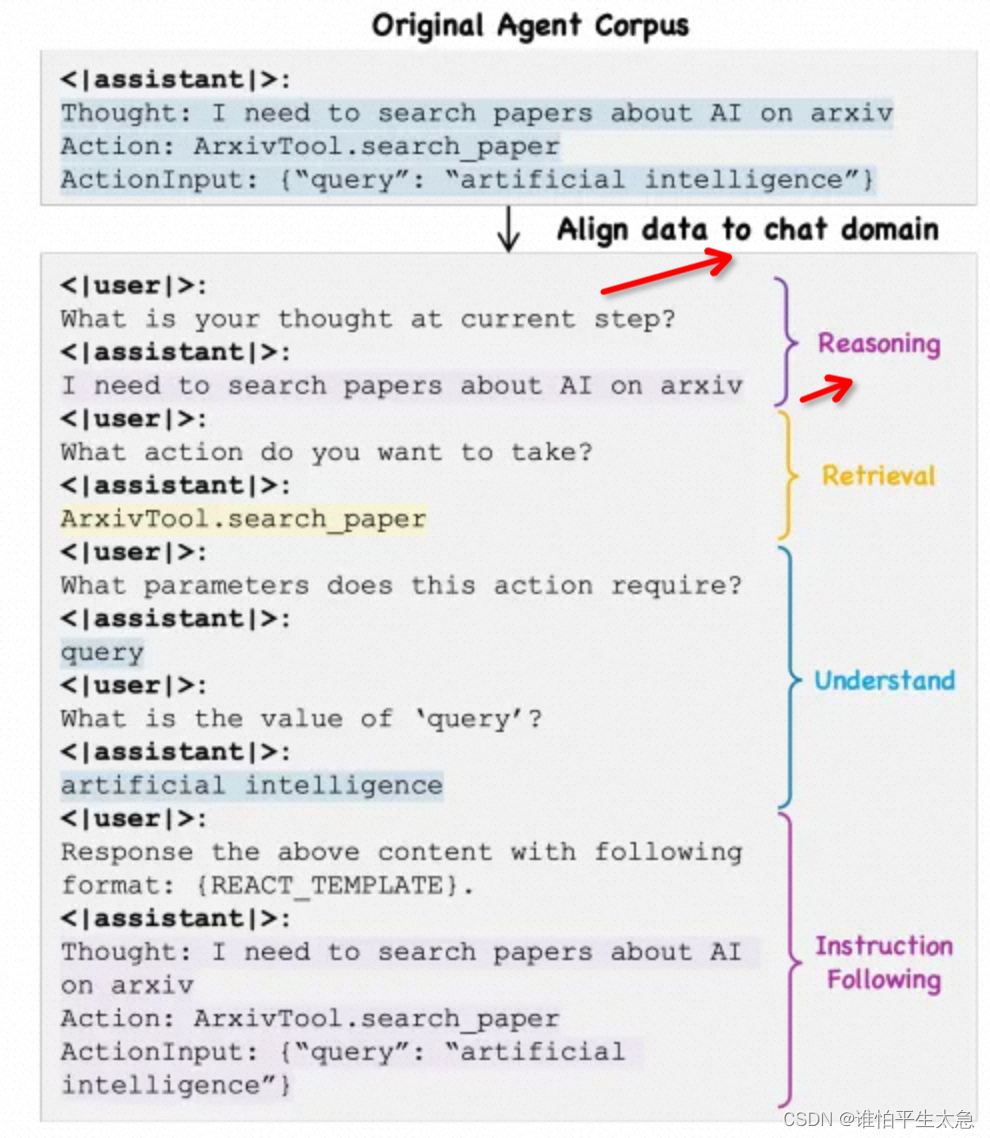
1、将格式化的数据转换为自然对话形式,然后将JSON参数通过插入多个引导语句进行分解(重点!)。
通过这种形式,可以明确地将Agent语料库与聊天领域对齐,从而充分提升对纯粹Agent能力的学习,而不会过渡关注严格的格式协议。
2、构建了指令遵循对,要求模型以ReAct和JSON格式响应。
3、将Agent代理数据沿着每个任务所需的能力显式分解,包括推理、检索、理解和指令遵循,并根据模型不同能力的学习速度来平衡这些数据源。示例:减少检索和指令遵循的数据量对性能的影响很小,甚至有所提升。
4、Agent-H基准测试——从两个方面评估LLM的幻觉问题(格式层面和行动层面)。首先清洗AgentInstruct和ToolBench数据集,然后混合了10%的ReAct格式数据和90%的对话格式数据。
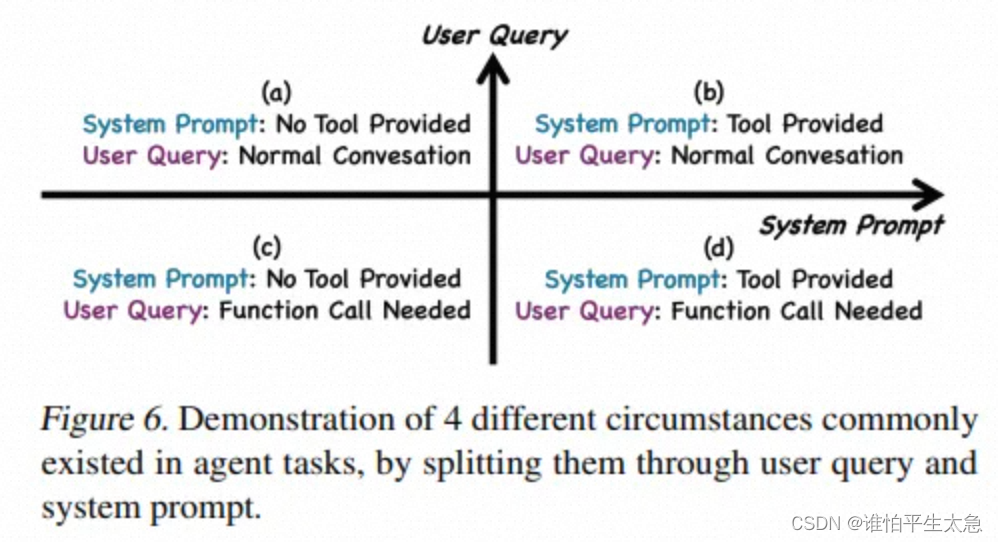
5、通过负样本学习策略减少幻觉。引入两种类型的负样本:一种是没有提供工具时用户查询请求工具的情况,另一种是提供了工具时用户查询请求正常对话的情况。
最终效果:
Agent任务的性能提升;
Agent-H基准上的表现。
6、规模化法则:
(1)数据规模化:通过将Agent-FLAN数据均匀分为25%、50%、75%和100%四个部分,研究发现仅使用25%的训练样本时,代理能力获得了最大的提升。这表明原始的Llama-2模型在代理能力方面较弱,需要特定的训练。当进一步增加数据量时,性能仍然有所提升,但速度放缓,这表明简单地增加代理训练语料库的规模并不会显著提升模型能力。因此,丰富训练语料库的多样性或提高其质量可能是提升语言代理性能的必要途径。
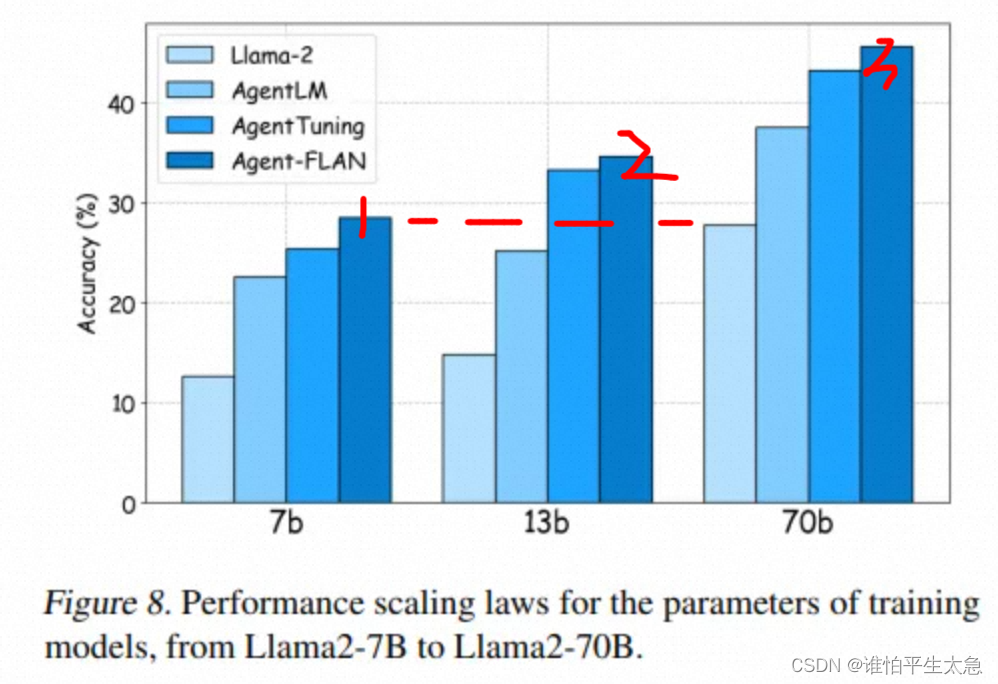
(2)模型规模化:这证明了更大的模型规模确实能够保证更好的性能。随着模型规模的增加,特定的代理调整相较于传统的ReAct调整带来了稳定的性能提升。
7、一般能力和Agent能力的关系
一般能力:LLMs在广泛的NLP任务中表现的能力(语言理解、生成和推理等)
Agent能力:LLMs在执行特定Agent任务时的能力,例如环境感知、决策指定和行动执行。
4种Agent tasks环境:
总结:
(1)通过将代理训练数据与自然对话对齐,Agent-FLAN能够在不过分专注于严格的格式协议的情况下,充分提升LLMs的纯粹代理能力。
(2)此外,通过对代理任务进行不同能力的分解和数据平衡,Agent-FLAN根据模型各自能力的不同学习速度提供了训练的灵活性。
(3)最后,通过负面样本学习策略,Agent-FLAN有效地减轻了幻觉问题,同时保持了在代理评估基准上的高性能。















 88
88

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









