







《OS-ATLAS: A FOUNDATION ACTION MODEL FOR GENERALIST GUI AGENTS》
SeeClick的作者 Zhiyong Wu
摘要
从业者通常不愿使用开源VLM,因为它们在与闭源版本相比时,在GUI定位和Out-Of-Distribution(OOD)场景中存在显著的性能差距。
为了促进该领域的未来研究,我们开发了OS-Atlas——一个基础的GUI动作模型,它通过数据和建模方面的创新,在GUI定位和OOD代理任务中表现出色。
OOD:Out-Of-Distribution 没见过的界面
我们投入了大量工程精力开发了一个开源工具包,用于跨多个平台(包括Windows、Linux、MacOS、Android和Web)合成GUI grounding 数据。
利用这个工具包,我们发布了迄今为止最大的开源跨平台GUI语义理解数据集,其中包含超过1300万个GUI元素。
该数据集结合了模型训练的创新,为OS-Atlas理解GUI截图和泛化到未见过的界面提供了坚实的基础。
通过在涵盖三个不同平台(移动、桌面和Web)的六个基准测试中的广泛评估,OS-Atlas显示出了相比之前最先进的模型的显著性能提升。
我们的评估还揭示了关于不断改进和扩展开源VLMs的代理能力的宝贵见解。
贡献
这项工作的目标是建立一个强大的基础行为模型,以促进未来通用GUI代理的发展。为此,我们做出了以下贡献:
(1)我们已经开发并发布了首个多平台图形用户界面(GUI)语义理解数据合成工具包。这个工具包能够自动化地跨多个平台(包括Windows、macOS、Linux、Android和Web)合成GUI语义理解数据。这样做大大减少了未来研究中数据整理所需的工程努力。
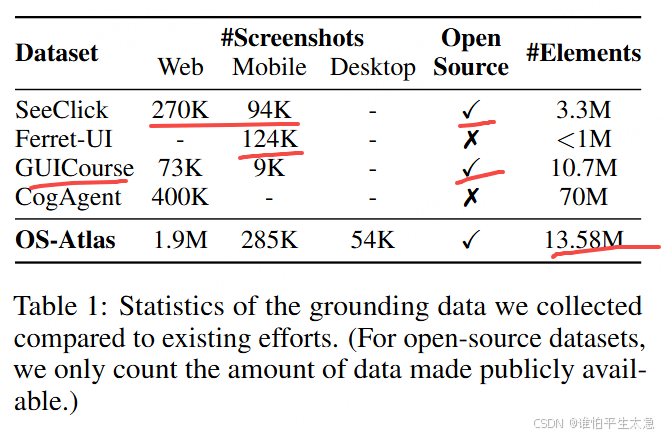
(2)利用这个数据工具包,我们整理并开源了迄今为止最大的多平台GUI定位语料库,其中包含超过230万个独特的屏幕截图和超过1300万个GUI元素。值得注意的是,我们的语料库包括了以前工作中未出现过的桌面定位数据。为了促进GUI定位的评估,我们识别并重新注解了流行基准ScreenSpot (Cheng et al., 2024)中11.32%的错误样本,并发布了ScreenSpot-V2。
(3)通过上述数据创新和解决训练中动作命名冲突的方法,我们开发了OS-Atlas,这是一个高度准确的通用基础动作模型,可应用于所有GUI。
(4)我们展示了至今为止对GUI(图形用户界面)代理的最全面评估,涵盖了三个不同平台(桌面、移动和网络)上的六个基准。如图1所示,OS-Atlas在先前的SOTA(State-Of-The-Art,最先进的)模型上表现出显著的性能提升。这一强大的性能表明,OS-Atlas可以作为一个开源的替代方案,用于开发未来的GUI代理,与GPT-4o等强大的商业VLM(Visual Language Model,视觉语言模型)相媲美。
正文
图1
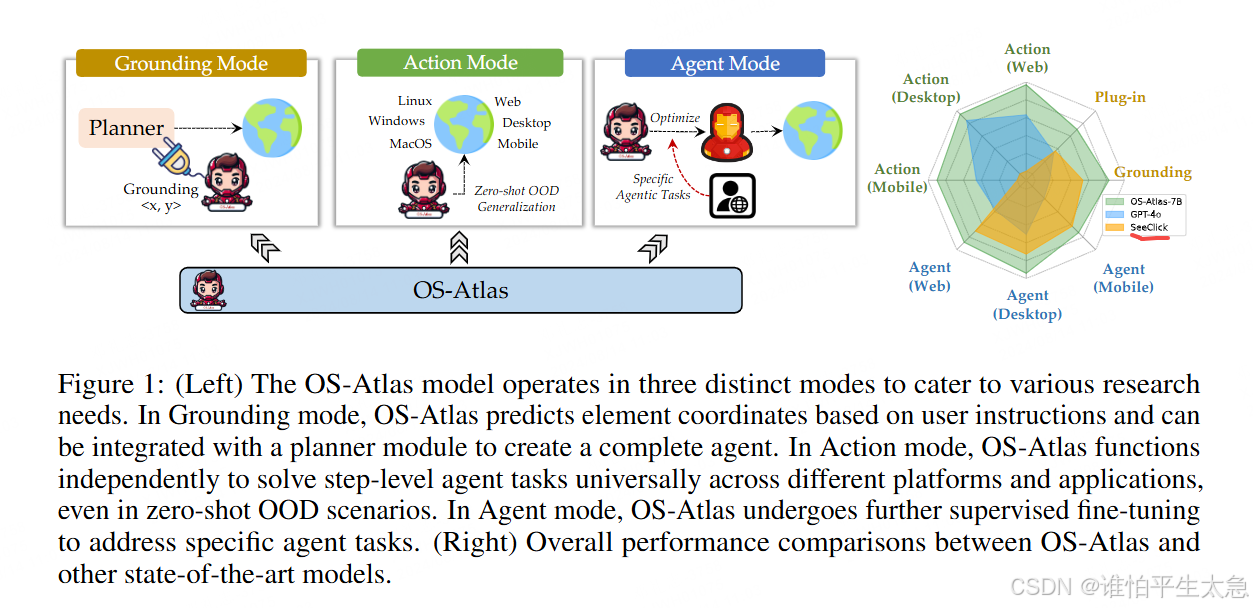
OS-Atlas模型有三种不同的运行模式,以满足各种研究需求。
在Grounding模式下,OS-Atlas根据用户指令预测元素坐标,并可以与规划模块集成,以创建一个完整的智能体。
在Action模式下,OS-Atlas能够独立地在不同平台和应用中普遍解决步骤级代理任务,即使在零样本OOD场景中也是如此。
在代理模式下,OS-Atlas会进行进一步的监督微调,以处理特定的代理任务。
3 OS-ATLAS
改进措施:我们从数据(第3.2节)和方法论(第3.3节)两个角度提出改进措施。
我们的训练过程包括两个连续的阶段:
(1) GUI Grounding 预训练,使 VLM 具备理解 GUI 截图和识别屏幕元素的知识;在此基础上,
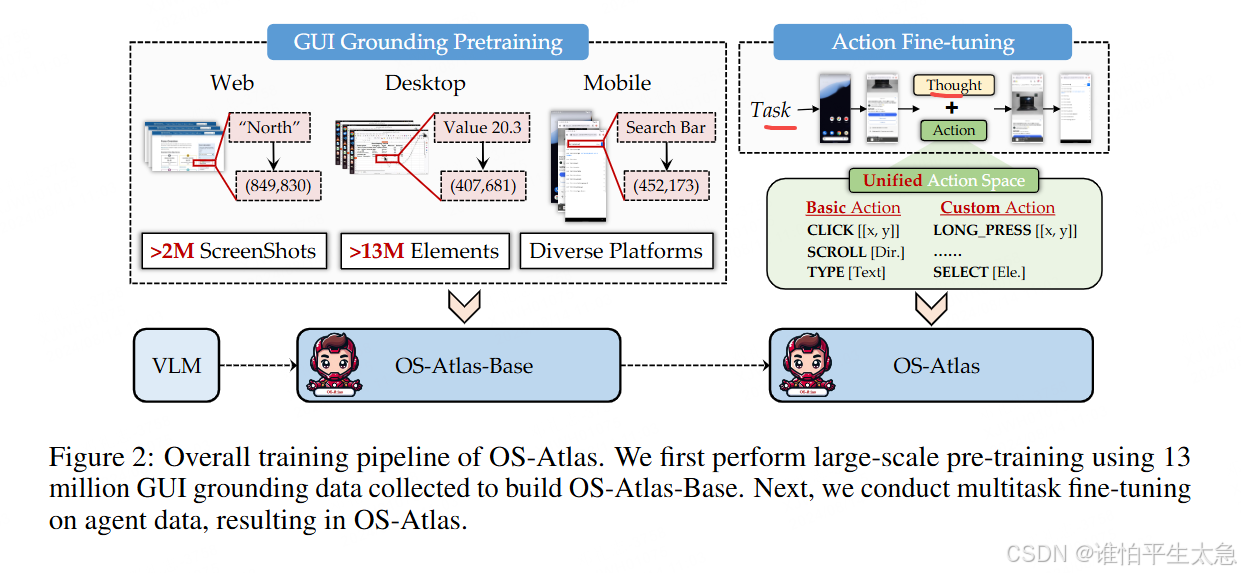
(2) Action Fine-tuning,将指令转化为可执行的 GUI 操作。框架概述如图所示。
我们首先使用1300万个用于构建OS-Atlas-Base的GUI接地数据进行大规模预训练。接下来,我们在代理数据上进行多任务微调,由此生成OS-Atlas。
任务一:GUI grounding 预训练
这一阶段需要大量、高质量、多样的<screenshot, 元素指代表达式或指令, 元素坐标>三元组,其中坐标可以表示为点或边界框。模型使用截图和指代表达式或指令来预测相应的元素坐标。为了促进大规模的预训练,我们已经收集了迄今为止最大的多平台GUI参考语料库,并使用VLMs合成了一组指令关联数据,具体细节见第3.2节。如表1所示,我们的预训练语料库涵盖了5个不同的平台,包含超过230万个独特的截图,其中包含超过1300万个元素。我们把预训练模型称为OS-Atlas-Base。
指令 grounding 数据收集:
除了大规模自动化收集指代表达数据之外,我们还使用GPT-4o对现有轨迹数据集进行了注解,以获取指令关联数据。
给定一个高级任务指令以及动作前后界面的截图,我们指示GPT-4o仔细分析界面的变化,以推导出针对当前动作的子指令。
具体来说,我们使用Set-of-Mark提示(Yang et al., 2023)来指示操作元素的位置,这有助于GPT-4o更好地理解屏幕截图。
我们标注了 来自网络和移动平台的四个轨迹数据集的训练集,分别是Mind2Web(Deng et al., 2023b)、AMEX(Chai et al., 2024)和AITZ(Zhang et al., 2024d)。
我们还利用了两个公开可用的数据集——AndroidControl(Li et al., 2024)和Wave-UI——提供的指令接地数据。
【1】注解:分析界面的变化,得到当前动作的 子指令
3.3 统一的动作空间
包括 基础操作和自定义操作
system prompt如下:
You are a foundational action model capable of automating tasks across various digital environ-
ments, including desktop systems like Windows, macOS, and Linux, as well as mobile platforms
such as Android and iOS. You also excel in web browser environments. You will interact with
digital devices in a human-like manner: by reading screenshots, analyzing them, and taking
appropriate actions.
Your expertise covers two types of digital tasks:
- Grounding: Given a screenshot and a description, you assist users in locating elements
mentioned. Sometimes, you must infer which elements best fit the description when they aren’t
explicitly stated.
- Executable Language Grounding: With a screenshot and task instruction, your goal is
to determine the executable actions needed to complete the task. You should only respond with
the Python code in the format as described below:
You are now operating in Executable Language Grounding mode. Your goal is to help users
accomplish tasks by suggesting executable actions that best fit their needs. Your skill set includes
both basic and custom actions:
1. Basic Actions
Basic actions are standardized and available across all platforms. They provide essential function-
ality and are defined with a specific format, ensuring consistency and reliability.
Basic Action 1: CLICK
- purpose: Click at the specified position.
- format: CLICK <point>[[x-axis, y-axis]]</point>
- example usage: CLICK <point>[[101, 872]]</point>
Basic Action 2: TYPE
- purpose: Enter specified text at the designated location. [在指定的位置输入指定的文本。]
- format: TYPE [input text]
- example usage: TYPE [Shanghai shopping mall]
Basic Action 3: SCROLL
- purpose: SCROLL in the specified direction.
- format: SCROLL [direction (UP/DOWN/LEFT/RIGHT)]
- example usage: SCROLL [UP]
2.Custom Actions
Custom actions are unique to each user’s platform and environment. They allow for flexibility
and adaptability, enabling the model to support new and unseen actions defined by users. These
actions extend the functionality of the basic set, making the model more versatile and capable of
handling specific tasks.
模型
模型。我们考虑了两种不同的后端模型:Qwen2-VL(Wang et al., 2024),它使用GUI数据进行专门训练,以及InternVL-2(Chen et al., 2024d),它在没有GUI数据的情况下训练。
这些模型在处理图像分辨率方面也有所不同。InternVL-2-4B利用AnyRes(Liu et al., 2024; You et al., 2024)调整图像大小并将较大的图像分割成较小的补丁,然后使用视觉编码器独立编码这些补丁。
相比之下,Qwen2-VL-7B通过直接将图像映射到动态数量的视觉令牌来支持任意图像分辨率。
(1)OS-Atlas-Base and OS-Atlas (7B)
Qwen2-VL通过将图像映射到动态数量的视觉令牌,能够处理任意的图像分辨率,提供更接近人类的视觉处理体验。通过实验,我们发现,在训练和推理过程中,将图像输入的最大像素设置为1024x1024对于GUI定位任务可以得到优秀的效果,同时也优化了模型的训练和推理成本。同样,为了保持与Qwen2-VL原始定位训练格式的一致性,我们将框数据转换为格式<|box start|>(x1,y1),(x2,y2)<|box end|>,其中<|box start|>和<|box end|>被视为特殊令牌。
任务名称
现有的GUI建模训练数据可以分为两类:指称表达建模(REG:referring expression grounding)(Liu et al., 2023)和指令建模(IG: instruction grounding)(Li et al., 2020)。REG专注于根据语言指令中的明确参考定位屏幕上的特定元素,例如“点击打开按钮”。通过爬取和解析(Cheng et al., 2024; Chen et al., 2024b),从网页中收集REG数据相对直接。
开源节奏
Code and models will be coming soon~
Set-of-Mark
我们提出了一种新的视觉提示方法,称为Set-of-Mark (SoM),用于释放大型多模态模型(如GPT-4V)的视觉定位能力。
如图1(右)所示,我们利用现成的交互式分割模型,如SEEM/SAM,将图像划分为不同粒度的区域,并在这些区域上叠加一组标记,例如字母数字、掩模、框。使用带标记的图像作为输入,GPT-4V可以回答需要视觉支撑的问题。
我们进行了一项全面的实证研究,以验证SoM在各种细粒度视觉和多模态任务中的有效性。例如,我们的实验表明,在零样本设置下,使用SoM的GPT-4V在RefCOCOg上超越了最先进的全微调的引用表达理解与分割模型。SoM提示代码已在此公开:https://github.com/microsoft/SoM。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









