







准备知识
准确率
精确率
召回率
F1值
问题提出:
不同模型好坏的对比

关心的问题1:分类器到底分对了多少?准确率:预测正确的正负样本/总样本数——当样本类别不均衡时,准确率和错误率可能不再适用,因为样本不均衡问题中主要关心少的那一类能否被分类正确,如果分类器将所有样例都划分为数目多的那一类,能轻松达到很高的准确率,但实际上该分类器没有任何效果。
关心的问题2:返回的图片中正确的有多少?精确率:返回的某一类的图片的个数/返回的所有个数
关心的问题3:有多少张应该返回的标签但没有找到?召回率:返回的某一类的数目/样本中所有该类别的数目
类别不均衡问题:各种评估指标
类别不平衡问题:ROC和PR曲线

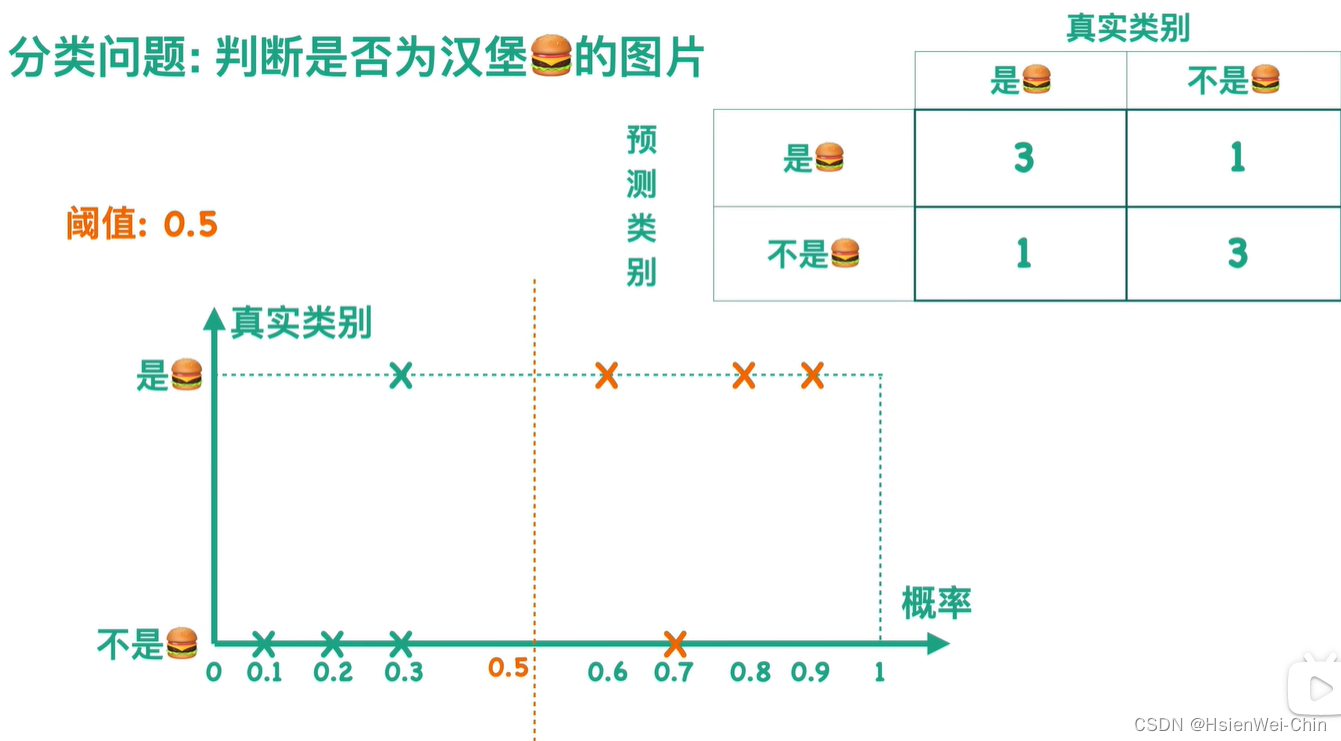
混淆矩阵的左边表示预测的类别,上边表示真实的类别的话
准确率=对角线的和/总和
精确率=(0,0)/第一行的和
召回率=(0,0)/第一列的和
精确率和召回率在某种程度上是相反的,不能仅仅依靠精确率或召回率的高低判断模型的好坏
F1_score = 精确率和召回率的调和平均

F1_score是Fβ值的特殊情况

F1_score认为精确率和召回率同等重要
在某些问题上,可能需要召回率更重要,比如在医疗领域,不希望遗漏掉任何一位患者,所以认为recall更重要,此时可以把β取2,如果认为精确率更重要,则将β值设为0~1之间
二分类问题

多分类问题

准确率=混淆矩阵对角线的和/矩阵的和
某一类的精确率 = 该类别对角线上值/行的和
某一类的召回率=该类别对角线上的值/列的和
某一类的F1值=该类的精确率和召回率的调和平均
该模型对所有类别的分类好坏可以用带权重的平均F1值:权重可以按数据集中每一类的样本数目占比决定
macro宏观的精确率、召回率和F1_score为对所有类别的精确率、召回率和F1值做某种平均
micro微观的精确率、召回率和F1_score
把每一类的混淆矩阵加一起,而不是并在一起(如上图),得到整个模型的混淆矩阵,然后计算混合类别的精确率和召回率和F1值
注:如果每一个输入,都只输出一个类别的话,那么微观的精确率、召回率和F1值都是相等的,且等于精确率accuracy
ROC曲线和AUC值
对不同的阈值,有且仅有一个混淆矩阵与之对应
对某一个混淆矩阵,可以求出TPR和FPR值,TPR=召回率=TP/该列的和,FPR=特异率=FP/该列的和
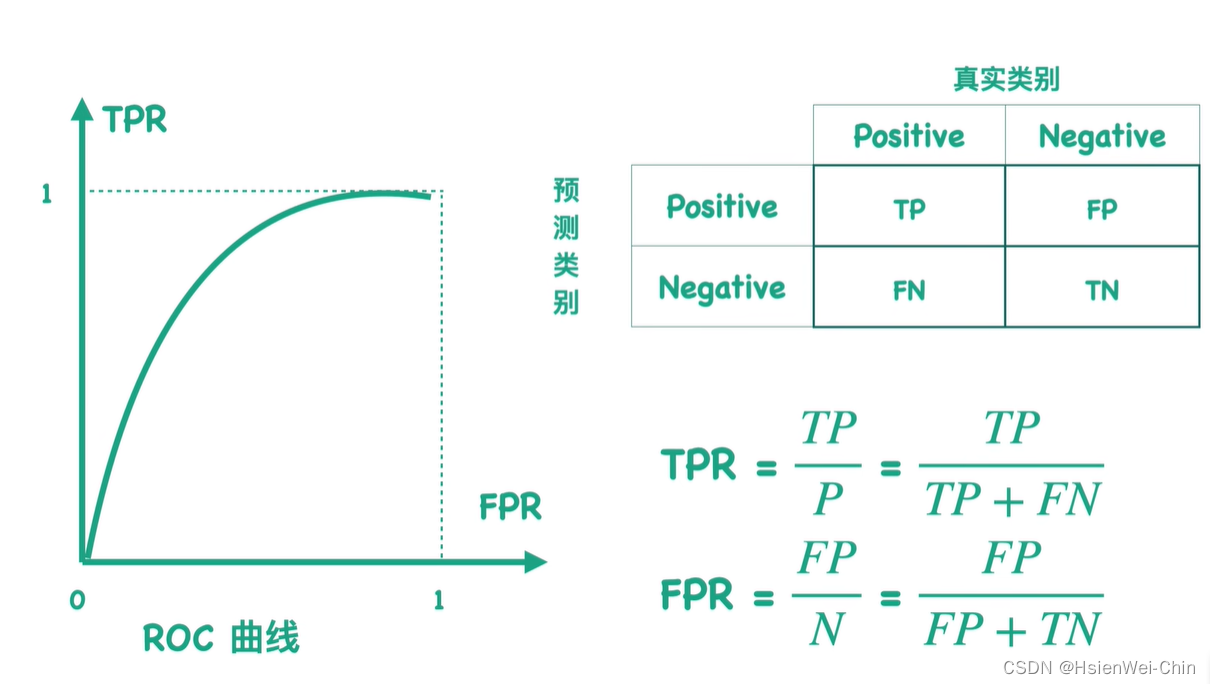
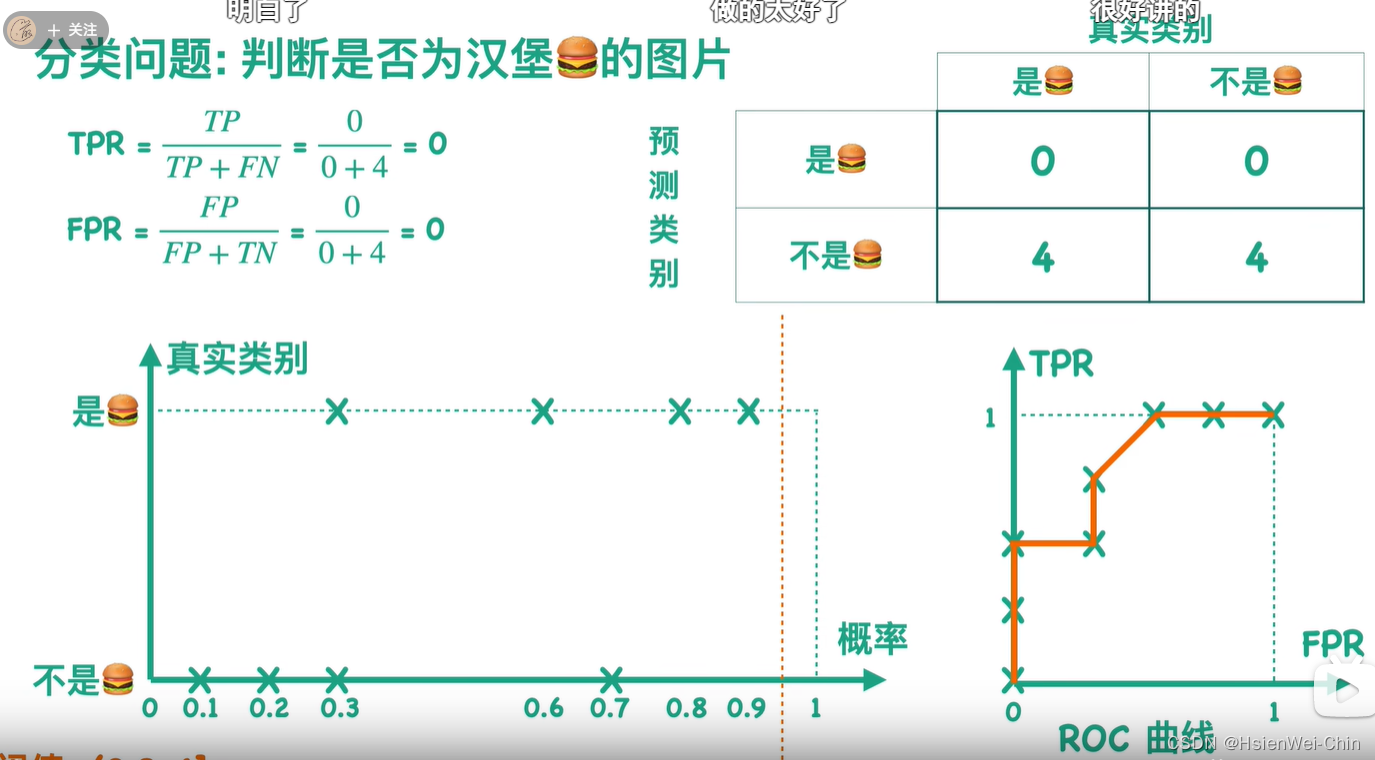
对不同的分类阈值,会得到与之对应的混淆矩阵,就会得到每个混淆矩阵与之对应的TPR和FPR的值,将所有混淆矩阵的点连起来的曲线,为ROC曲线
对不同的模型得到的ROC曲线,TPR和FPR的分母分别为样本中的正负样本数,故两者数值大小仅与分子有关,TP表示正样本被预测为正性的个数,FP表示本应预测为负样本却被错误预测为正样本的个数,所以TPR越大,FPR越小越好,所以ROC曲线面积越大越好
ROC曲线面积——AUC值(area under cure,0~1之间,越大越好)

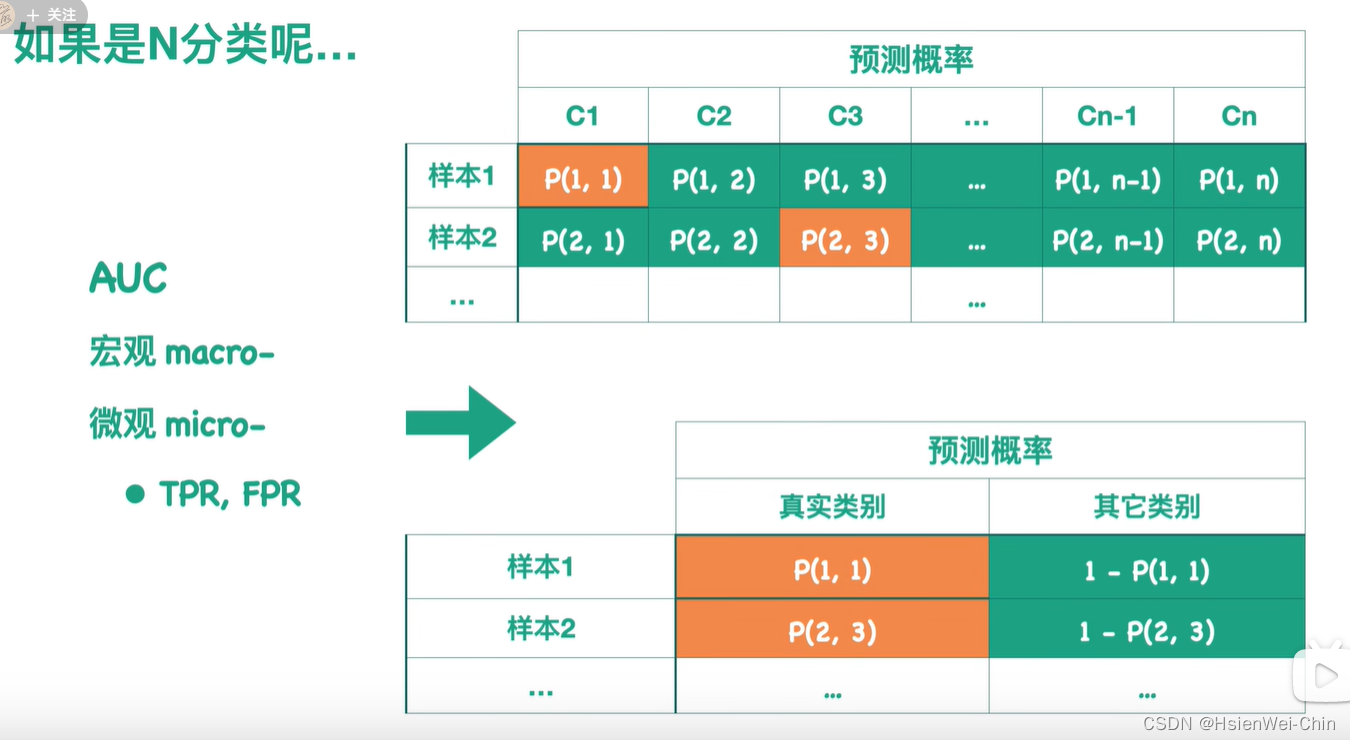
多分类问题
计算AUC
宏观AUC macro:针对每一个类别,画出ROC曲线,求出对应的AUC值,最后对所有的AUC值求某种平均,作为整个模型对所有类别的宏观AUC值
微观AUC micro:针对下图转化后的表,得到针对每个模型的ROC曲线和对应的AUC值
mmcls代码
mmcls中的datasets中的base_dataset.py中包含了可以使用的分类评估指标
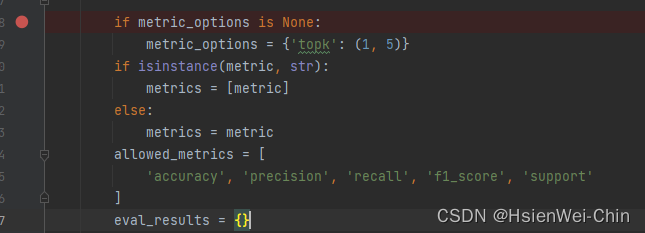
可供调整的评估metrics有:准确率accuracy,精确率precision,召回率recall,f1score
accuracy
某一阈值下的(top 1)accuracy的计算

概率的阈值可以设置为元组的形式

某一阈值下的所有类别的precision, recall, f1_score的计算,list的形式
某一阈值的宏观macro类别平均的precision,recall,f1_score,均值的形式
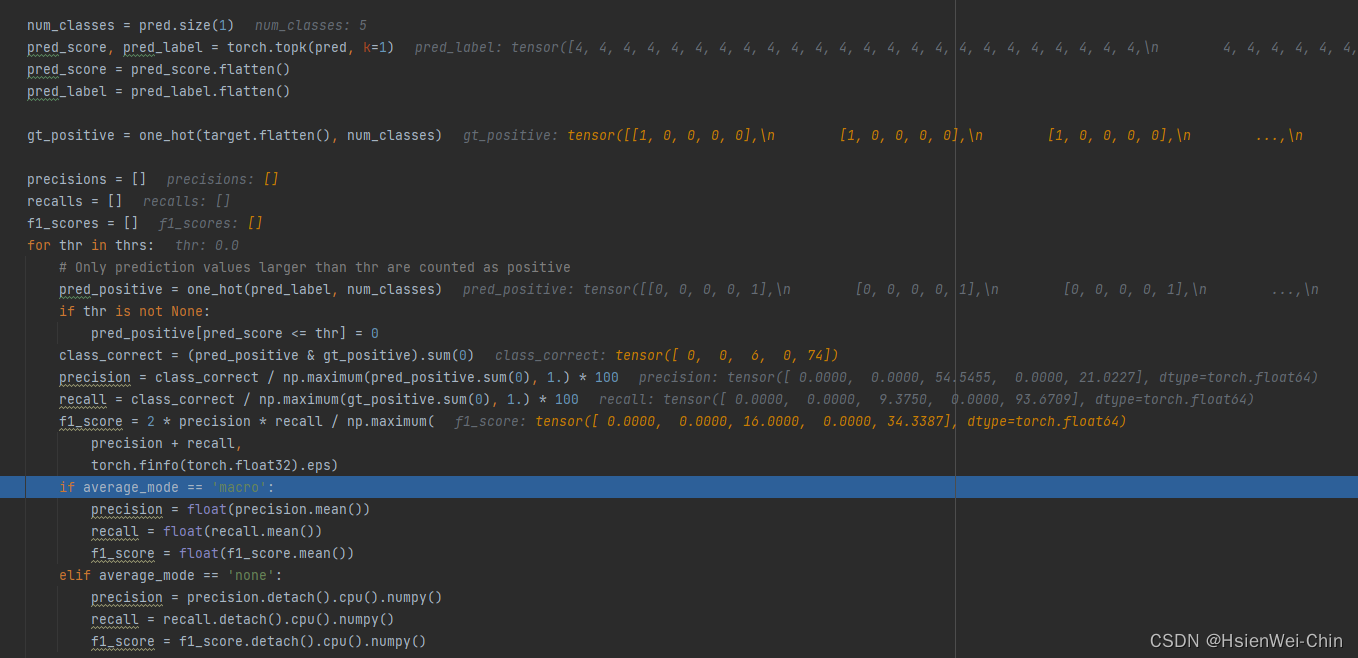
当将topk设置为元组,thre也设置为元组后

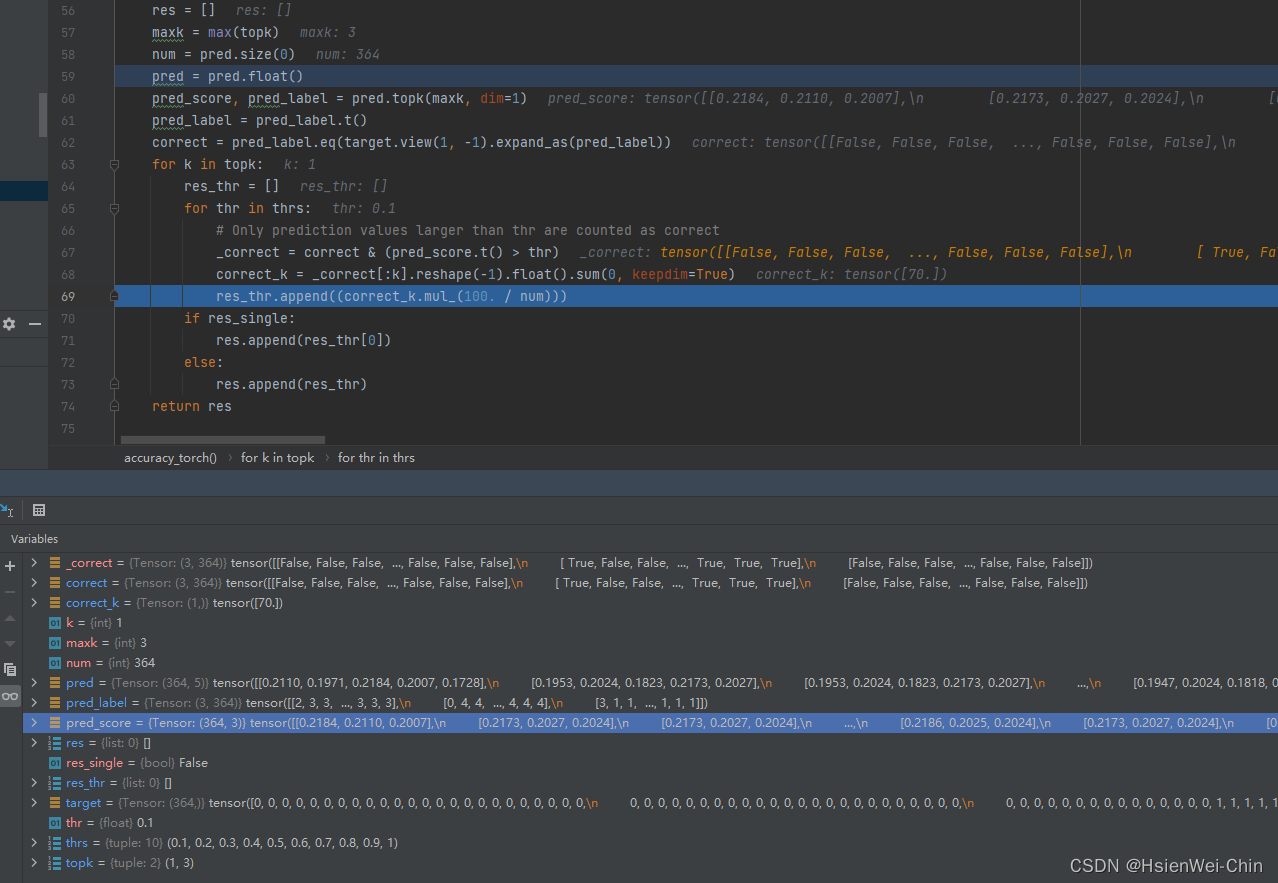
pre_score和pred_label与top几有关,top1,就1行,top3,就三行

for top in topk:
for thre in thres
accuracy与topk和thre都有关,而precision、recall、f1_score只与thre有关

这里限制了pred_score和pred_label的维度为1x数据个数
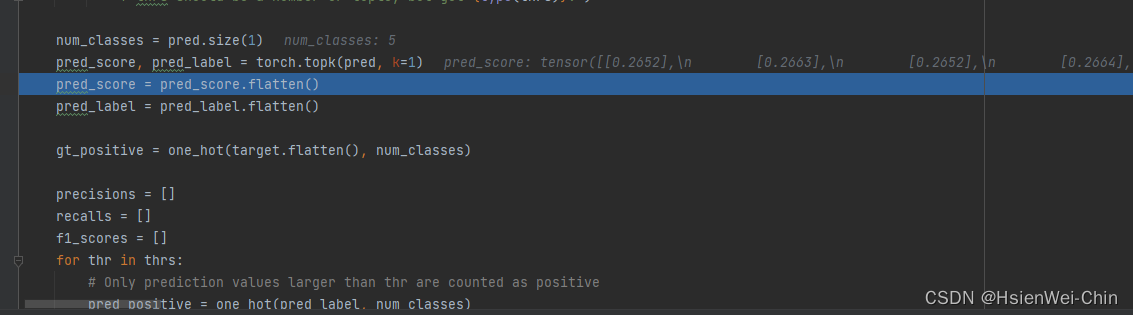
对不同的thre,如果pred_score小于thre,那么将pred_positive中对应点设置为0,pred_positive
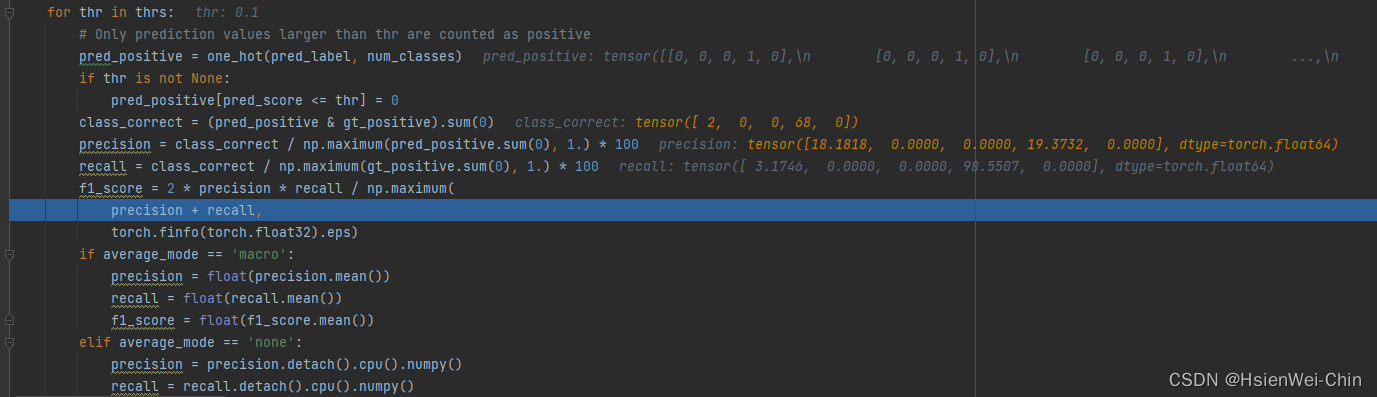
模型训练完成后,才利用模型和测试集合进行不同阈值的precision,recall,PR曲线绘制,AP值的求取,mAP值的求取;不同阈值的TPR,FPR,ROC曲线的绘制,AUC值的求取
使用mmcls中的test.py和sklearn库计算每种类别的mAP和AUC值,绘制所有类别的PR和ROC曲线,计算模型对所有类别的mAP和AUC平均值(加权也行)
分类评估指标的选择
当正负样本不均衡时:
1)正样本很少(1很少)(垃圾右键检测,信用卡欺诈)
交叉熵损失不敏感
需要同时考虑ROC曲线和PR曲线,需要同时考虑AUC值和f1_score
2)负样本很少(0很少)
交叉熵损失和f1都不适用
ROC曲线(AUC值)适用
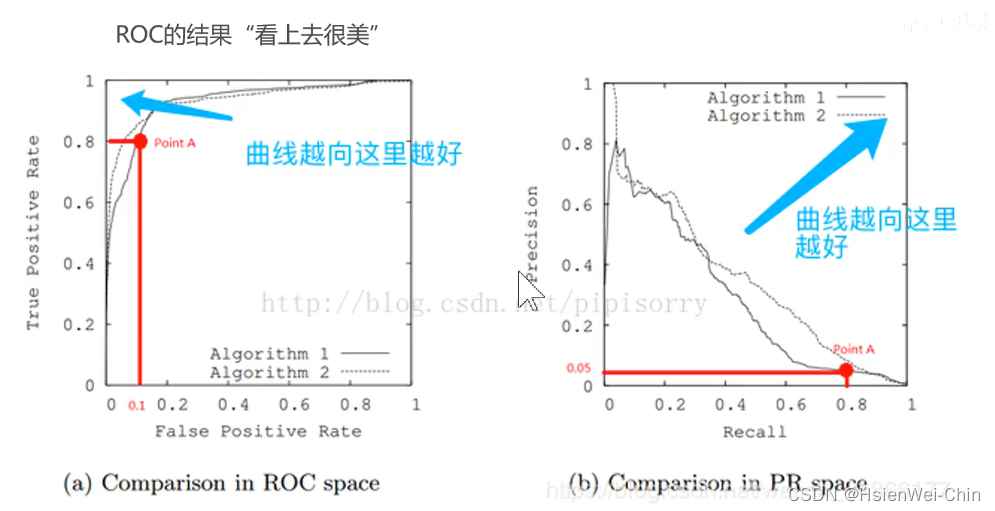
结论
- 在任何时刻都不要看交叉熵损失来评估不同的模型,交叉熵一般用做训练模型时的损失函数,用来梯度下降反向传播,训练神经网络
- ROC曲线和AUC值可以在正负样本不均衡的时候,用做分类模型的评估指标,但需要同时看PR曲线和f1score
- 不同的阈值,有不同的混淆矩阵,一个混淆矩阵对应一个tpr和fpr,遍历所有阈值,得到整个roc曲线
数据完全可分时,ROC曲线呈现直角状态——ROC曲线的越接近左上角,则分类器的分类性能越好(但不绝对,如果正样本极少,ROC曲线对正负样本不均衡不敏感,需要同时看PR曲线和f1_score)

使用sklearn对roc曲线PR曲线,mAP,auc值,最佳f1scor和对应的threshold的确定
- 获得gt标签,并转为one hot矩阵
base_dataset = CustomDataset(cfg.get('data').get('test').get('data_prefix'),
cfg.get('data').get('test').get('pipeline'))
gt_label = base_dataset.get_gt_labels()
outputs = np.array([*outputs])
# 项目中的混淆矩阵(max概率)
mulcla_matrix = calculate_confusion_matrix(outputs, gt_label)
# print()
# print(mulcla_matrix.shape)
# print(mulcla_matrix)
# 计算某一种类别的混淆矩阵
num_classes = 5
gt_positive = one_hot(torch.tensor(gt_label).flatten(), torch.tensor(num_classes))
- 计算不同阈值的precision、recall,计算map,计算f1score,确定最大f1score和对应的threshold
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.grid(True)
print()
ap_list = []
best_f1_score_list = []
best_f1_thres_list = []
for i in range(num_classes):
gt_positive_1 = gt_positive[:, i]
pred_score_1 = outputs[:, i]
precision, recall, thresholds = precision_recall_curve(gt_positive_1, pred_score_1) # (真正的二进制标签,预测分数)
f1_score = (2 * precision * recall) / (precision + recall)
best_f1_score = np.max(f1_score[np.isfinite(f1_score)])
best_f1_score_index = np.argmax(f1_score[np.isfinite(f1_score)])
best_f1_score_list.append(best_f1_score)
best_thres = thresholds[best_f1_score_index]
best_f1_thres_list.append(best_thres)
AP = average_precision_score(gt_positive_1, pred_score_1, average='weighted')
plt.plot(recall, precision, label=i)
plt.legend()
ap_list.append(AP)
print('best_f1_score_list for every class: {}'.format(best_f1_score_list))
print('best_f1_thres_list for every class: {}'.format(best_f1_thres_list))
print('mAP for every class: {}'.format(ap_list))
plt.show()
- 计算不同阈值下的tpr和fpr,绘制ROC曲线,计算各类别的auc值
plt.xlabel('fpr')
plt.ylabel('tpr')
plt.grid(True)
auc_list = []
for i in range(num_classes):
gt_positive_i = gt_positive[:, i]
pred_score_i = outputs[:, i]
fpr, tpr, threshold_roc = roc_curve(gt_positive_i, pred_score_i)
auc_list.append(auc(fpr, tpr))
plt.plot(fpr, tpr, label=i)
plt.legend()
print('auc for every class: {}'.format(auc_list))
plt.show()















 2204
2204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









