







数据结构包括数组、链表、栈、二叉树、哈希表等等
| 数据结构 | 优点 | 缺点 | |
| 数组 | 插入快 | 查找慢、删除慢、大小固定 | |
| 有序数组 | 查找快 | 插入慢、删除慢、大小固定 | |
| 栈 | 后进先出 | 存取其他项很慢 | |
| 队列 | 先进先出 | 存取其他项很慢 | |
| 链表 | 插入、删除快 | 查找慢 | |
| 二叉树 | 查找、插入、删除快 | 算法复杂(删除算法) | |
| 红黑树 | 查找、插入、删除快 | 算法复杂 | |
| hash表 | 存取极快(已知关键字)、插入快 | 删除慢、不知关键字时存取很慢、对存储空间使用不充分 | |
| 堆 | 插入快、删除快、对大数据项存取快 | 对其他数据项存取慢 | |
| 图 | 依据现实世界建模 | 算法有些复杂 | |
| AVL树 | 查找、插入、删除快 | 算法复杂 |
总结:
通用数据结构:数组,链表,树,哈希表
它们被称之为通用的数据结构是因为它们通过关键字的值来存储并查找数据,这一点在通用数据库程序中常见到(栈等特殊结构正好相反,它们只允许存取一定的数据项)。
通用数据结构可以完全按照速度的快慢来分类:数组和链表是最慢的,树相对较快,哈希表是最快的。
但并不是使用最快的结构永远是最好的方案。这些最快的结构也有缺陷,首先,它们的程序在不同程度上比数组和链表的复杂;其次,哈希表要求预先知道要存储多少数据,数据对存储空间的利用率也不是非常高。普通的二叉树对顺序的数据来说,会变成缓慢的O(N)级操作;而平衡树虽然避免了上述的问题,但是它的程序编制起来却比较困难。
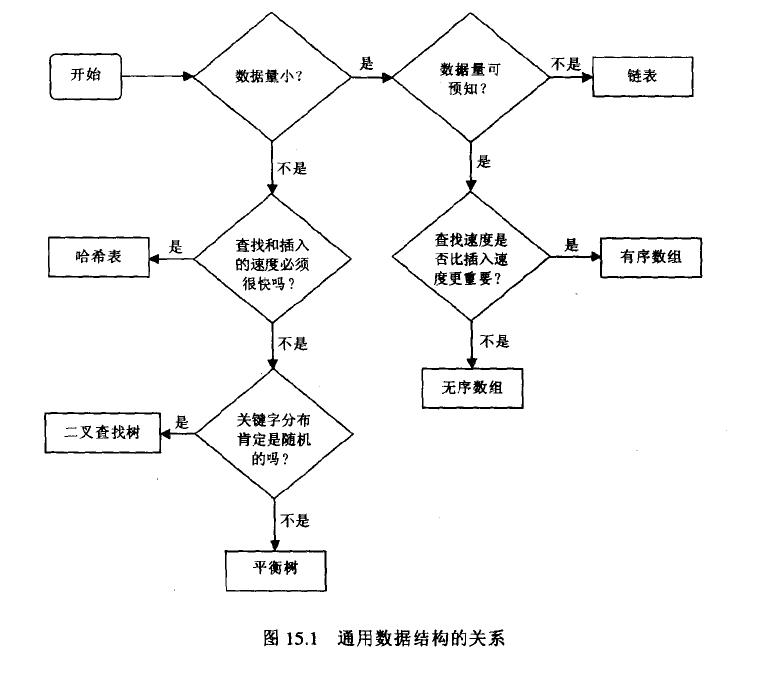
数组在下列情况下很有用:
1、数据量较小
2、数据量的大小事先可预测
3、如果存储空间足够大的话,可以放松第二条,创建一个足够大的数组来应付所有可以预见的数据输入。
如果插入速度很重要的话,使用无序数组。如果查找速度很重要的话,使用有序数组,并用二分查找。数组元素的删除总是很慢,这是由于为了填充空出来的单元,平均半数以上的数组元素要被移动。在有序数组中的遍历是很快的,而在无序的数组不支持这种功能。
如果需要存储的数据量不能预知或者需要频繁地插入删除数据元素时,考虑使用链表。当有新的元素加入时,链表就开辟新的所需要的空间,所以它甚至可以占满全部可用内存;在删除过程中没有必要像数组那样添补“空洞”。
常见的数据结构有:array,list,stack,deque,binaryTree,hashMap,heap,对于C++而言还有最常用的vector
接着分析每一种的特点:
[1] array
内存分配:在内存中分配一段连续的空间;
特点:需要再定义时就知道分配空间的大小;
使用:用于预先就已知需要的最大储存空间的情况;
[2] vector
内存分配:在内存中分配一段连续的空间;
实现:内部实际通过管理一个数组指针实现;
特点:插入的元素如果超出分配的内存空间,会自动划分一段更大的内存空间,将数据拷贝过去后,释放原空间;
使用:对于C++而言采用vector的情况比较多。对于需要随机访问元素,预先不知道需要分配的内存空间大小情况。但是vector在中间和头部插入比较麻烦,插入时间复杂度是O(N);因此vector适用于只在尾部插入和删除的情况;
[3] list
内存分配:随机分配;
实现:通过一个结构体保存指向前一个元素和后一个节点的指针(双向链表);
特点:在任何地方插入都很方便,但是随机访问时间复杂度是O(N);
[4] stack
实现:通过一个表实现很方便,也可以通过数组实现;
特点:后进先出,在编译器中得到广泛应用,例如编译器实现的函数堆栈;
[5] deque
实现:通过一个数组实现;
特点:先进先出,典型应用是多个对象需要抢占同一个资源时;
[6] binaryTree
内存分配:随机分配
实现:保存左右儿子的指针
特点:插入和访问的时间复杂度都是O(logN),内部操作函数的实现很多靠递归来实现。每个节点儿子的个数可以扩展。在操作系统的编译器中的得到广泛应用;
[7] hashMap
实现:分离链接法通过数组和链表实现,开放地址法通过数组实现;
特点:支持随机访问,可以保存到每个数据的信息,可以访问指定的元素。因此应用于需要知道数据信息的情况,比如实现一个词典,就可以将单词存入一个hash表中;
[8] heap
实现:通过数组实现一个完全二叉树,称为堆
















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









