






关注公众号【1024个为什么】,及时接收最新推送文章!
对账中心简介
我们在工作中肯定听过很多“xx 中心”,用户中心、商品中心、订单中心…… 今天要和大家聊的正如题所述--对账中心,它不像其他中心的名气那么大,甚至很多人都没有听过它,但是它的地位的确很重要,尤其是在微服务架构流行的当下。下面我们就一步步的认识并了解对账中心。
对账中心基本概念
一听到“对账”,我想大多数人脑海里浮现的是:这不是财务领域的工作吗?跟我们业务系统有什么关系?
这里我给对账下了 2 个定义,以便大家理解。
狭义:财会领域,主要是对数据的业务发生日期、金额等信息的核对。
广义:两个同类数据集合,集合内元素一致性的核对。
我们今天所讨论的就是广义上的对账,所以用一句话描述对账中心就是:具备核对两个同类数据集合内元素一致性能力的一个独立系统。 当然,这只是它最核心的一个能力,只有这个能力还远远不够。就像我们去银行开个户,只能存、取钱是远远不够的,我还需要查看明细、余额变动短信提醒…… 后面的内容也会涉及到对账中心的非核心能力。
我们通过下图来了解几个名词,参与的对账方、多账、少账、平账、错账。
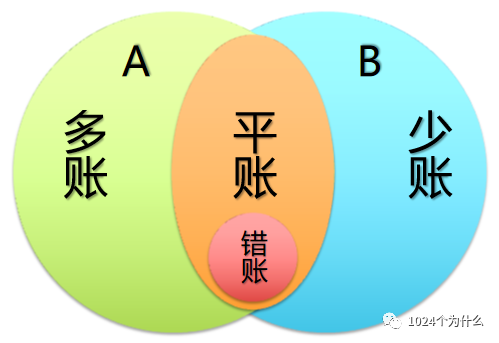
在上图中,A、B 就是参与对账方(如果是多方对账,拆分到最底层也是双方先比对,比对结果再作为一方和其他参与方比对),我们假设以A为基准,左边绿色部分是在 A 有在 B 没有,我们称作A 多账;同理,右边蓝色部分就是A 少账;中间橙色部分是 AB 双方都有的,我们称作平账;红色部分的错账是平账里的一种特殊场景,需要特殊说明一下。
例如:A 里有一条数据 orderId=10005,amount=100.00,B 里有一条数据 orderId=10005,amount=80.00
如果只核对 orderId,那么核对结果就是平账,如果 amount 也要核对,那么这两条数据就属于错账了。
对账的种类划分
•对账时效:实时对账、周期对账
实时对账就是数据只要一发生变动,就取双方的数据进行核对,一般多用来比较状态;
周期对账就是我们常说的按天(T+1,T+2...)、按月来核对。•业务场景:金额对账、流水对账、状态对账•对账模式:交易对账、资金对账
交易对账就是我们最常见的,两个系统中每一条交易记录的核对;
资金对账主要是和财务相关的。
对账中心应该具备的能力
•对账任务的管理
每个接入的场景称作一个对账任务,任务多了就需要有一个后台来管理,比如任务的开启、暂停,动态的配置每个任务的数据筛选规则、比对规则•差异结果告警、输出
差异结果需要及时告知相关的负责人,也能够对差异结果进行下载导出,便于后续的处理流程•源数据、比对结果的数据管理
数据的持久化,能够支撑不同的数据源•多场景、多模式的数据核对能力
能够支撑各个接入方的不同需求
对账中心由简到繁
对账中心 1.0
任何脱离业务的设计都是耍流氓,所以首先要交代一下业务背景,这也是我们为什么要做对账中心的原因。
业务背景:
用户在确认服务完成后,该笔订单的费用并不会实时的打到商家的账户,而是清算之后有一个冻结期(冻结期的长短根据业务而定,这也是很多公司维护商家和消费者共同权益的一种做法)。
有一个解冻的任务负责扫描需要解冻的资金流水,满足解冻条件了,就会通知账户中心某个账户某笔订单收入可以解冻了,解冻后商家就可以自由的处理这笔钱了。
我们通知账户中心采用的技术手段是发 MQ 消息,由于是异步处理,所以肯定有消息未到达,或者消费方处理失败的情况。如果是未触发系统告警的失败,是很难发现的,只能等到商家反馈才知道有解冻失败的,给用户的体验很不好。
基于这个背景,我们需要有一个系统(人工取数采用Excel比对不是长久之计)来解决这个痛点,能够暴露出系统的问题,提升用户体验。
我们先来确定一下对账的流程:

在选型时我们做了如下对照,前2种是比较靠谱的,最终根据我们的业务特点,选择了第一种,文件+内存。
| 优点 | 缺点 | |
| 文件 | 简单,易实现 | 文件拆分、文件编码、扩展性 |
| 数据库 | 避免了文件的缺点 | 与业务库解耦有一定的成本 |
| redis | 比对快 | 网络IO耗时远大于比对耗时,得不偿失 |
| 大数据 | 轻松应对海量数据,一步到位 | 成本高,小数据量有点浪费 |
确定对账流程和技术选型之后就有了最初的一个架构,如下图所示:

需要参与比对的业务方,按照对账中心的规范(约定大于开发),生成指定格式的对账文件,并且把文件上传到 FTP 对应的目录下等待对比。
采用 FTP 是为了使
对账中心与业务系统解耦,对账中心不会直接调业务系统的接口、更不能直接连业务系统的数据库来获取数据,为了对账而把业务系统搞挂了,就得不偿失了。
对账文件的要求有两点: 第一,生成和解析要容易实现;第二,文件要尽可能占用较小的磁盘空间。
基于这 2 点的考虑,我们采用的是.txt(当然.csv 也可以),加上特定的分隔符,每行表示一条记录。
对账中心按约定好的路径、格式去获取文件并解析,生成对应的 Java 对象,放到集合中,然后利用集合自身的特性交集(平账)、差集(多账/少账)得到比对结果,并保存到提前建好的和该业务场景对应的结果表中。通过 WEB 后台页面就可以查看、处理差异结果。
有一点需要特殊说明一下:
集合本身具有去重的特性,如果对账文件中有相同的记录,会被自动去重,如果业务要求这种数据也要比对出来,就需要在添加进集合时做一些特殊处理,确保集合中的数据和对账文件中的数据完全一致。
到此,基本的业务需求算是满足了,线上运行也确实暴露出了业务系统的一些问题。接下来大家也能猜到,肯定会有其他的业务场景陆续接入。但接入了几个场景后,现有架构存在的问题就慢慢暴露出来了。
问题如下:
1.差异无告警,问题暴露不及时,需要人工去对账后台查看;2.接入门槛高,如架构图中'···'所示,每接入一个场景整个流程的每个环节都要重新开发,而且工作量很大。有点像私人定制,完全没有体现出软件设计中的复用性;3.对账中心自身能力很薄弱。
为了后续更多的场景能够快速的接入,问题能够及时暴露,我们需要对这些问题需要改造优化。改造的两大方向如图所示:

对账中心 2.0
我们仔细分析后发现,导致接入成本高的根本原因在于,每个业务场景的数据载体不通用,这就导致从解析文件开始,后面的所有流程都要定制开发,工作量随之就大大增加。所以就先拿它开刀,抽象出一个通用的数据载体,供后面的流程使用。

如上图所示,对账中心不在关注业务数据的具体字段,在对账中心看来数据主要由 2 部分构成,对比的唯一键(uniqueId)、要对比的内容(compareFileds),不参与对比或者 AB 有差异的内容可以放到拓展类中(jsonObject)。基类自身具备比对的能力,从拓展类中获取要比对的内容。
根本问题解决了,架构也要做相应的调整,于是就有了 2.0 版的架构,如下图所示:

从图上可以看出,对账中心做了很大的调整。
•抽取出了两个引擎,引入了两个中心。由于数据载体得到了统一,所以解析引擎之后的流程都可以按通用的设计方案来实现。•告警中心也提供了两种告警方式,钉钉(简单的差异汇总)和邮件(详细的差异明细)。•唯一键、要对比的内容 也可以通过配置中心实现动态配置(前提是对账文件中有对应的内容)。
差异数据需要特殊说明一下,对账中心有2处会用到差异数据。
一处是告警,把差异的详细信息发送给告警接收人;
另一处是,把差异数据合并到后面比对的数据集合中继续比对。出于2个原因,一是业务数据可能会因时间差出现隔日的情况,数据在A的时间是23:59:59,在B的时间是00:00:00,如果不做处理,第一天会出现A多账,第二天就会出现A少账。我们把历史差异合并到第二天的比对数据中,就可以对平。第二个原因是如果在节假日产生差异,当日告警,后续如果没有差异告警,上班后很容易把节假日的告警忽略。
我们采取的是历史7天的差异会继续参与比对,这样既可以解决上面的2个问题,又不至于每次查询历史所有造成性能问题。
看起来比1.0要好很多了,但随着业务方的不断接入,又暴露出一系列新的问题。
问题如下:
1.对账文件如果要新增某种业务类型的数据,需要二次开发上线;2.接入方反馈接入成本还是很高,能不能连生成对账文件的开发量也省去;3.取数Job分散,不利于管理。
由于Job独立于业务系统,在系统变更人员交接时很容易漏掉这部分内容;4.数据源单一,目前只支持从FTP读取.txt文件;5.如果数据量很大,一次比对内存不够用,对文件拆分比对复杂度又会指数上升;6.无权限控制,项目配置、差错处理所有人都可以操作,存在一定的风险。
对账中心 3.0
针对上面的问题,我们又思考了架构该如何调整。既然文件的弊端暴露出来了,那我们就考虑引入第二种方案--数据库。
既然公司使用了阿里云,内部的数据就都可以拿到,那么公司内部的数据我们就通过业务库直接获取,外部的数据还是通过文件的形式处理。
使用数据库来存放源数据,就要解决如何和业务系统解耦的问题,前面也提到过不能直接连业务库,尽量也别调接口。好在公司有自己的数据仓库,大部分业务数据在数据仓库都可以拿到,数据仓库和业务库又可以互通,所以我们就借助数仓来解决这个问题。
没有数仓的,可以考虑和DBA共同开发数据同步的脚本,达到同样的目的。注意,一定要走从库,一定不能影响到业务系统。
我们依赖数仓还有另外一个很重要的原因,就是数仓的任务调度能力和任务依赖传递能力。取数任务一定要在比对任务之前执行完,否则就会出错。2.0版本时,都是人为的设定任务的执行时间,如果任务耗时是10分钟,下一个任务就要预留出20分钟甚至更长的时间。任务多了之后,设置时间这一项工作就会让人崩溃。
方案确定了,于是就有了 3.0 版的架构,如下图所示:

这样调整之后,就解决了2.0的前5个问题;之前接入方的Java开发工作已经被数仓的SQL脚本所取代,实现了零Java代码接入。我们又增强了配置中心,使配置像写WHERE条件一样灵活。如果变更取数规则,简单配置即可。

我们又接入了公司的Urm系统,实现了权限管理。
同样,系统还存在一系列的问题,这些问题需要在后面的版本继续优化。
问题如下:
1.解析引擎单一,支持的文件格式少,目前只支持 .txt;2.对账时效单一,还不支持实时对账;3.对账模式单一,只支持交易对账。
要达到第一节中所提到的应具备的能力,还有很长的路要走。
对账中心的适用场景和作用
适用场景
1.需要周期、长期对某些数据进行核对;2.大数据量核对,已经超出了Excel的处理能力;3.采用异步方案来保证数据最终一致性的系统;4.财务、审计涉及的业务系统的数据;
作用
1.及时暴露系统问题;2.提升用户体验,问题少了,体验自然就好了;3.提升工作效率,降低人工成本;4.相当于给业务系统又上了一个保险;
这点有点像日志监控系统,平时没有存在感,一旦有异常,就会立即出来告诉你。5.反向推动业务数据存储的规范性。
我们会认为业务数据很完善,一旦和关联系统做比对的时候就会发现,要想把取数口径调一致真没有想象的那么简单。
总结
1、系统的设计一定要以满足业务需求为前提,不能为了炫技而过度设计。
2、要善于发现系统的痛点,这样才能不断完善。














 3109
3109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









