








一、Seaborn简介
1.定义
Seaborn是一个基于matplotlib且数据结构与pandas统一的统计图制作库。
Seaborn框架旨在以数据可视化为中心来挖掘与理解数据。
2.优点
- 代码较少
- 图形美观
- 功能齐全
- 主流模块安装
二、安装
1.pip命令安装
pip install matplotlib
pip install seaborn
2.从github安装
pip install git+https://github.com/mwaskom/seaborn.git
三、流程
1.导入绘图模块
mport matplotlib.pyplot as plt
import seaborn as sns
2.提供显示条件
%matplotlib inline #在Jupyter中正常显示图形
3.导入数据
#Seaborn内置数据集导入
dataset = sns.load_dataset('dataset')
#外置数据集导入(以csv格式为例)
dataset = pd.read_csv('dataset.csv')
4.设置画布
#设置一块大小为(12,6)的画布
plt.figure(figsize=(12, 6))
5.输出图形
#整体图形背景,共5种:"white", "dark", "whitegrid", "darkgrid", "ticks"
sns.set_style('ticks')
#以条形图为例输出图形
sns.barplot(x=x,y=y,data=dataset,...)
'''
barplot()括号里的是需要设置的具体参数,涉及到数据、颜色、坐标轴、以及具体图形的一些控制变量,
基本的一些参数包括'x'、'y'、'data',分别表示x轴,y轴,以及选择的数据集。
'''
6.保存图形
#将画布保存为保存为png、jpg、svg等格式图片
plt.savefig('jg.png')
四、实战
本文实验数据集来源于豆果美食网,关注J哥公众号「菜J学Python」,后台回复cook即可自动获取。如果对豆果美食网数据爬虫代码感兴趣,也可在公众号后台添加J哥交流。
#数据准备
df = pd.read_csv('./cook.csv') #读取数据集(可在微信公众号「菜J学Python」后台回复cook获取)
df['难度'] = df['用料数'].apply(lambda x:'简单' if x<5 else('一般' if x<15 else '较难')) #增加分类字段
df = df[['菜谱','用料','用料数','难度','菜系','评分','用户']] #选择需要的列
df.sample(5) #查看数据集的随机5行数据
| 菜谱 | 用料 | 用料数 | 难度 | 菜系 | 评分 | 用户 | |
|---|---|---|---|---|---|---|---|
| 2138 | 蛋白芝麻脆片 | 蛋白,木糖醇,色拉油,盐,低筋面粉,芝麻 | 6 | 一般 | 清真菜 | 1.0 | Better_J |
| 619 | 牙签肉 | 鸡胸肉,蚝油,烤肉酱,料酒,生抽,牙签,孜然粉,糖,生粉 | 9 | 一般 | 湘菜 | 4.7 | 暮之雪 |
| 1562 | 青椒炒香菇 | 香菇,青椒,蒜 | 3 | 简单 | 鲁菜 | 4.7 | 小舞Dora |
| 873 | 豉油烧鸡腿 | 鸡腿,姜,葱,酿造酱油,黑胡椒 | 5 | 一般 | 粤菜 | 4.8 | 阿罗al |
| 2111 | 香蕉蛋白奶昔 | 香蕉,脱脂牛奶,香蕉奶昔粉,冰块,料理机 | 5 | 一般 | 清真菜 | 5.0 | 魏姓男子 |
#导入相关包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置加载的字体名
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set_style('white') #设置图形背景样式为white
直方图
#语法
'''
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None,
hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None, color=None,
vertical=False, norm_hist=False, axlabel=None, label=None, ax=None)
'''
#distplot()输出直方图,默认拟合出密度曲线
plt.figure(figsize=(10, 6)) #设置画布大小
rate = df['评分']
sns.distplot(rate,color="salmon",bins=20) #参数color样式为salmon,bins参数设定数据片段的数量
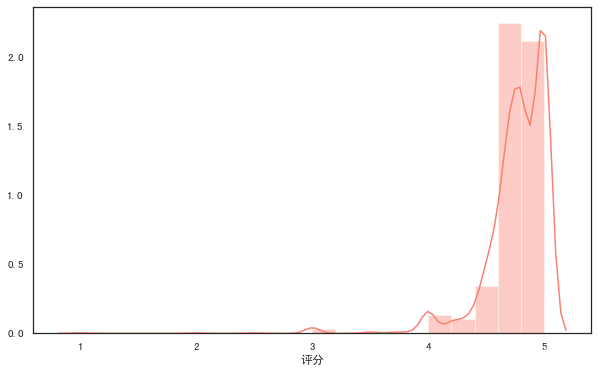
#kde参数设为False,可去掉拟合的密度曲线
plt.figure(figsize=(10, 6))
sns.distplot(rate,kde= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1831
1831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









