







5. Spark构建分类模型
分类是监督学习的一种形式,我们用带有类标记或者类输出的训练样本训练模型。
5.1 分类模型的种类
- Spark中常见的三种分类模型:线性模型、决策树和朴素贝叶斯模型。
- 线性模型:简单而且相对容易扩展到非常大的数据集
- 决策树:一个强大的非线性技术,训练过程计算量大而且较难扩展,但是在很多情况下性能很好。
- 朴素贝叶斯模型:简单,易训练,并且具有高效和并行的优点。
- Spark的MLlib库提供了基于线性模型、决策树和朴素贝叶斯的二分类模型,以及基于决策树和朴素贝叶斯的多类别分类模型。
5.1.1 线性模型
- 线性模型的核心思想:对样本的预测结果进行建模,即对输入变量应用简单的线性预测函数。
- 模型的拟合、训练或优化:给定输入数据的特征向量和相关的目标值,存在一个权重向量能够最好对数据进行拟合,拟合的过程即最小化模型输出与实际的误差。具体来说,我们需要找到一个权重向量能够最小化所有训练样本的由损失函数计算出来的损失之和。
- 本文只介绍MLlib提供的两个适合二分类模型的损失函数:逻辑损失(逻辑回归模型)和合页损失(线性支持向量机)。
- 逻辑回归:一个概率模型。输出等价于模型预测某个数据点属于正类的概率估计。
5.1.2 朴素贝叶斯模型
朴素贝叶斯是一个概率模型,通过计算给定数据点在某个类别的概率来进行预测。朴素贝叶斯模型假定每个特征分配到某个类别的概率是独立分布的。
5.1.3 决策树
- 决策树是一个强大的非概率模型,可以处理类属或者数值特征,同时不要求输入数据归一化或标准化。决策树非常适合应用集成方法,比如多个决策树的集成,成为决策森林。
- 决策树算法是一种自上而下始于根节点(或特征)的方法,在每一个步骤中通过评估特征分裂的信息增益,最后选出分割数据集最优的特征。信息增益通过计算节点不纯度(即节点标签不相似或不同质的程度)减去分割后的两个子节点不纯度的加权和。对于分类任务,这里有两个评估方法用于选择最好分割:基尼不纯和熵。
5.2 从数据中抽取合适的特征
- 大部分机器学习模型以特征向量的形式处理数值数据。
- MLlib中的分类模型通过LabeledPoint对象操作,其中封装了目标变量(标签)和特征向量:case class LabeledPoint(label: Double, features: Vector)
数据链接,下载train.tsv文件。
- 为了让Spark更好地操作数据,删除文件第一行的列头名称。
sed 1d train.tsv > train_noheader.tsv- 启动Spark shell
./bin/spark-shell --driver-memory 4g- 训练数据读入RDD并进行检查
val rawData = sc.textFile("/PATH/train_noheader.tsv")
val records = rawData.map(line => line.split("\t"))
records.first输出如下:

开始四列分别包含URL,页面的ID,原始的文本内容和分配给页面的类别。
由于数据格式的问题,我们做一些数据清理的工作:把额外的(“)去掉,用0替换缺失数据。
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.Vectors
val data = records.map { r =>
val trimmed = r.map(_.replaceAll("\"", ""))
val label = trimmed(r.size - 1).toInt
val features = trimmed.slice(4, r.size - 1).map(d => if (d == "?") 0.0 else d.toDouble)
LabeledPoint(label, Vectors.dense(features))
}data.cache
val numData = data.count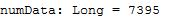
对数据集做进一步处理之前,我们发现数值数据中包含负的特征值,而朴素贝叶斯模型要求特征值非负,因此下面为朴素贝叶斯模型构建一份输入特征向量的数据,将负特征值设为0:
val nbData = records.map { r =>
val trimmed = r.map(_.replaceAll("\"", ""))
val label = trimmed(r.size - 1).toInt
val features = trimmed.slice(4, r.size - 1).map(d => if (d == "?") 0.0 else d.toDouble).map(d => if (d < 0) 0.0 else d)
LabeledPoint(label, Vectors.dense(features))
}5.3 训练分类模型
- 为了比较不同模型的性能,我们将训练逻辑回归、SVM、朴素贝叶斯和决策树。
- 每个模型的训练方法几乎一样,不同的是每个模型都有着自己特定可配置的模型参数。
- MLlib大多数情况下会设置明确的默认值,但实际上,最好的参数配置需要通过评估技术来选择。
5.3.1 训练分类模型
- 引入必要的类并对每个模型配置一些基本的输入参数。
import org.apache.spark.mllib.classification.LogisticRegressionWithSGD
import org.apache.spark.mllib.classification.SVMWithSGD
import org.apache.spark.mllib.classification.NaiveBayes
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.tree.configuration.Algo
import org.apache.spark.mllib.tree.impurity.Entropy
- 为逻辑回归和SVM设置迭代次数,为决策树设置最大树深度。
val numIterations = 10
val maxTreeDepth = 5- 训练逻辑回归模型
val lrModel = LogisticRegressionWithSGD.train(data, numIterations)- 训练SVM模型
val svmModel = SVMWithSGD.train(data, numIterations)- 训练朴素贝叶斯,要使用处理过的没有负特征值的数据
val nbModel = NaiveBayes.train(nbData) - 训练决策树
val dtModel = DecisionTree.train(data, Algo.Classification, Entropy, maxTreeDepth)5.4 使用分类模型
现在我们有四个在输入标签和特征下训练好的模型。
在训练数据上进行预测。
val dataPoint = data.first
val prediction = lrModel.predict(dataPoint.features)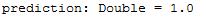
val trueLabel = dataPoint.label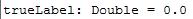
可以看出,我们的模型预测出错了!
我们可以将RDD[Vector]整体作为输入做预测:
val predictions = lrModel.predict(data.map(lp => lp.features))
predictions.take(5)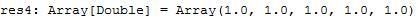
5.5 评估分类模型的性能
在二分类中评估模型性能的方法包括:预测正确率和错误率、准确率和召回率、准确率-召回率曲线下方的面积、ROC曲线、ROC曲线下的面积和F-Measure。
5.5.1 预测的正确率和错误率
- 正确率:训练样本中被正确分类的数目除以总样本数。
- 错误率:训练样本中被错误分类的数目除以总样本数。
- 逻辑回归模型的正确率:
val lrTotalCorrect = data.map { point =>
if (lrModel.predict(point.features) == point.label) 1 else 0
}.sum
val lrAccuracy = lrTotalCorrect / numData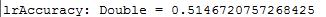
- SVM模型的正确率:
val svmTotalCorrect = data.map { point =>
if (svmModel.predict(point.features) == point.label) 1 else 0
}.sum
val svmAccuracy = svmTotalCorrect / numData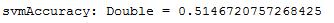
- 朴素贝叶斯模型的正确率:
val nbTotalCorrect = nbData.map { point =>
if (nbModel.predict(point.features) == point.label) 1 else 0
}.sum
val nbAccuracy = nbTotalCorrect / numData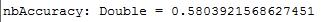
- 决策树模型的正确率,决策树的预测阈值需要明确给出(score > 0.5):
val dtTotalCorrect = data.map { point =>
val score = dtModel.predict(point.features)
val predicted = if (score > 0.5) 1 else 0
if (predicted == point.label) 1 else 0
}.sum
val dtAccuracy = dtTotalCorrect / numData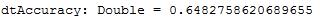
5.5.2 准确率和召回率
- 在信息检索中
- 准确率:用于评价结果的质量。
- 召回率:用于评价结果的完整性。
- 在二分类问题中
- 准确率:真阳性/(真阳性+假阳性)
- 真阳性:被正确预测的类别为1的样本(1->1)。
- 假阳性:错误预测为类别1的样本(0->1)。
- 召回率:真阳性/(真阳性+假阴性)
- 假阴性:类别为1却被预测为0的样本(1->0).
- 准确率和召回率是负相关的。
- 准确率:真阳性/(真阳性+假阳性)
- 准确率和召回率依赖于模型中选择的阈值
- 当阈值低于某个程度,模型的预测结果永远会是类别1,模型的召回率为1,但是准确率很可能很低。
- 当阈值足够大,模型的预测结果永远会是类别0,模型的召回率为0,无法定义模型的准确率。
- 准确率-召回率(PR)曲线下的面积为平均准确率,PR曲线下的面积为1等价于一个完美模型,其准确率和召回率达到100%。
5.5.3 ROC曲线和AUC
- ROC曲线:对分类器的真阳性率-假阳性率的图形化解释。
- 真阳性率(TPR):真阳性/(真阳性+假阴性)
- 假阳性率(FPR):假阳性/(假阳性+真阴性)
- AUC:ROC下的面积。
- AUC为1.0时表示一个完美的分类器,0.5则表示一个随机的性能。
MLlib内置了一系列方法用来计算二分类的PR和ROC曲线下的面积。
- 逻辑回归模型
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
val lrMetrics = Seq(lrModel).map { model =>
val scoreAndLabels = data.map { point =>
(model.predict(point.features), point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(model.getClass.getSimpleName, metrics.areaUnderPR, metrics.areaUnderROC)
}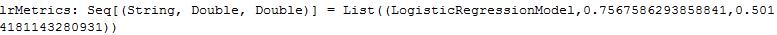
- SVM模型
val svmMetrics = Seq(svmModel).map { model =>
val scoreAndLabels = data.map { point =>
(model.predict(point.features), point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(model.getClass.getSimpleName, metrics.areaUnderPR, metrics.areaUnderROC)
}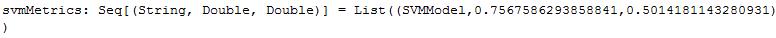
- 朴素贝叶斯模型
val nbMetrics = Seq(nbModel).map{ model =>
val scoreAndLabels = nbData.map { point =>
val score = model.predict(point.features)
(if (score > 0.5) 1.0 else 0.0, point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(model.getClass.getSimpleName, metrics.areaUnderPR, metrics.areaUnderROC)
}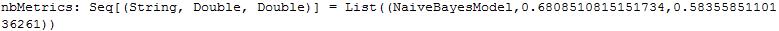
- 决策树模型
val dtMetrics = Seq(dtModel).map{ model =>
val scoreAndLabels = data.map { point =>
val score = model.predict(point.features)
(if (score > 0.5) 1.0 else 0.0, point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(model.getClass.getSimpleName, metrics.areaUnderPR, metrics.areaUnderROC)
}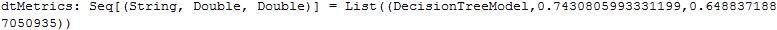
val allMetrics = lrMetrics ++ svmMetrics ++ nbMetrics ++ dtMetrics
allMetrics.foreach{ case (m, pr, roc) =>
println(f"$m, Area under PR: ${pr * 100.0}%2.4f%%, Area under ROC: ${roc * 100.0}%2.4f%%")
}
5.6 改进模型性能以及参数调优
5.6.1 特征标准化
我们使用的许多模型对输入数据的分布和规模有着一些固定的假设,其中最常见的假设形式是特征满足正态分布。
我们先将特征向量用RowMatrix类表示成MLlib中的分布矩阵。RowMatrix是一个由向量组成的RDD,其中每个向量是分布矩阵的一行。
import org.apache.spark.mllib.linalg.distributed.RowMatrix
val vectors = data.map(lp => lp.features)
val matrix = new RowMatrix(vectors)
val matrixSummary = matrix.computeColumnSummaryStatistics()- 输出矩阵每列的均值:
println(matrixSummary.mean)
- 输出矩阵每列的最小值:
println(matrixSummary.min)
- 输出矩阵每列的最大值:
println(matrixSummary.max)
- 输出矩阵每列的方差:
println(matrixSummary.variance)
- 输出矩阵每列中非0项的数目:
println(matrixSummary.numNonzeros)
可以清晰地发现第二个特征的方差和均值比其他的都要高,原始数据并不符合标准的高斯分布。为了使数据更符合模型的假设,可以对每个特征进行标准化,使得每个特征是0均值和单位标准差。
import org.apache.spark.mllib.feature.StandardScaler
val scaler = new StandardScaler(withMean = true, withStd = true).fit(vectors)
val scaledData = data.map(lp => LabeledPoint(lp.label, scaler.transform(lp.features)))第一行标准化前:
println(data.first.features)
第一行标准化后
println(scaledData.first.features)
使用标准化的数据重新训练模型,这里只训练逻辑回归,因为决策树和朴素贝叶斯不受特征标准化的影响。
val lrModelScaled = LogisticRegressionWithSGD.train(scaledData, numIterations)
val lrTotalCorrectScaled = scaledData.map { point =>
if (lrModelScaled.predict(point.features) == point.label) 1 else 0
}.sum
val lrAccuracyScaled = lrTotalCorrectScaled / numData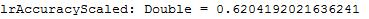
val lrPredictionsVsTrue = scaledData.map { point =>
(lrModelScaled.predict(point.features), point.label)
}
val lrMetricsScaled = new BinaryClassificationMetrics(lrPredictionsVsTrue)
val lrPr = lrMetricsScaled.areaUnderPR
val lrRoc = lrMetricsScaled.areaUnderROC
println(f"${lrModelScaled.getClass.getSimpleName}\nAccuracy: ${lrAccuracyScaled * 100}%2.4f%%\nArea under PR: ${lrPr * 100.0}%2.4f%%\nArea under ROC: ${lrRoc * 100.0}%2.4f%%") 
5.6.2 其他特征
类别特征对性能的影响:
- 查看所有类别,并对每个类别做一个索引映射。
val categories = records.map(r => r(3)).distinct.collect.zipWithIndex.toMap
val numCategories = categories.size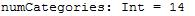
- 创建数据集
val dataCategories = records.map { r =>
val trimmed = r.map(_.replaceAll("\"", ""))
val label = trimmed(r.size - 1).toInt
val categoryIdx = categories(r(3))
val categoryFeatures = Array.ofDim[Double](numCategories)
categoryFeatures(categoryIdx) = 1.0
val otherFeatures = trimmed.slice(4, r.size - 1).map(d => if (d == "?") 0.0 else d.toDouble)
val features = categoryFeatures ++ otherFeatures
LabeledPoint(label, Vectors.dense(features))
}
println(dataCategories.first)
- 数据集标准化
val scalerCats = new StandardScaler(withMean = true, withStd = true).fit(dataCategories.map(lp => lp.features))
val scaledDataCats = dataCategories.map(lp => LabeledPoint(lp.label, scalerCats.transform(lp.features)))数据集标准化之前的特征:
println(dataCategories.first.features)
数据集标准化之后的特征:
println(scaledDataCats.first.features)
- 用扩展后的特征来训新的逻辑回归模型:
val lrModelScaledCats = LogisticRegressionWithSGD.train(scaledDataCats, numIterations)
val lrTotalCorrectScaledCats = scaledDataCats.map { point =>
if (lrModelScaledCats.predict(point.features) == point.label) 1 else 0
}.sum
val lrAccuracyScaledCats = lrTotalCorrectScaledCats / numData
val lrPredictionsVsTrueCats = scaledDataCats.map { point =>
(lrModelScaledCats.predict(point.features), point.label)
}
val lrMetricsScaledCats = new BinaryClassificationMetrics(lrPredictionsVsTrueCats)
val lrPrCats = lrMetricsScaledCats.areaUnderPR
val lrRocCats = lrMetricsScaledCats.areaUnderROC
println(f"${lrModelScaledCats.getClass.getSimpleName}\nAccuracy: ${lrAccuracyScaledCats * 100}%2.4f%%\nArea under PR: ${lrPrCats * 100.0}%2.4f%%\nArea under ROC: ${lrRocCats * 100.0}%2.4f%%") 
5.6.3 使用正确的数据格式
5.6.4 模型参数调优
- 模型性能的影响因素:特征提取、特征选择、输入数据的格式和模型对数据分布的假设。
- MLlib默认的train方法对每个模型的参数都使用默认值。
1.线性模型
逻辑回归和SVM模型有相同的参数,原因是他们都使用随机梯度下降(SGD)作为基础优化技术。
MLlib为线性模型提供了两个优化技术:SGD和L-BFGS。L-BFGS通常来说更精确,要调的参数较少。
import org.apache.spark.rdd.RDD
import org.apache.spark.mllib.optimization.Updater
import org.apache.spark.mllib.optimization.SimpleUpdater
import org.apache.spark.mllib.optimization.L1Updater
import org.apache.spark.mllib.optimization.SquaredL2Updater
import org.apache.spark.mllib.classification.ClassificationModeldef trainWithParams(input: RDD[LabeledPoint], regParam: Double, numIterations: Int, updater: Updater, stepSize: Double) = {
val lr = new LogisticRegressionWithSGD
lr.optimizer.setNumIterations(numIterations).setUpdater(updater).setRegParam(regParam).setStepSize(stepSize)
lr.run(input)
}def createMetrics(label: String, data: RDD[LabeledPoint], model: ClassificationModel) = {
val scoreAndLabels = data.map { point =>
(model.predict(point.features), point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(label, metrics.areaUnderROC)
}迭代
val iterResults = Seq(1, 5, 10, 50).map { param =>
val model = trainWithParams(scaledDataCats, 0.0, param, new SimpleUpdater, 1.0)
createMetrics(s"$param iterations", scaledDataCats, model)
}
iterResults.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.2f%%") }步长
val stepResults = Seq(0.001, 0.01, 0.1, 1.0, 10.0).map { param =>
val model = trainWithParams(scaledDataCats, 0.0, numIterations, new SimpleUpdater, param)
createMetrics(s"$param step size", scaledDataCats, model)
}
stepResults.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.2f%%") }正则化
val regResults = Seq(0.001, 0.01, 0.1, 1.0, 10.0).map { param =>
val model = trainWithParams(scaledDataCats, param, numIterations, new SquaredL2Updater, 1.0)
createMetrics(s"$param L2 regularization parameter", scaledDataCats, model)
}
regResults.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.2f%%") }2.决策树
import org.apache.spark.mllib.tree.impurity.Impurity
import org.apache.spark.mllib.tree.impurity.Entropy
import org.apache.spark.mllib.tree.impurity.Gini
def trainDTWithParams(input: RDD[LabeledPoint], maxDepth: Int, impurity: Impurity) = {
DecisionTree.train(input, Algo.Classification, impurity, maxDepth)
}val dtResultsEntropy = Seq(1, 2, 3, 4, 5, 10, 20).map { param =>
val model = trainDTWithParams(data, param, Entropy)
val scoreAndLabels = data.map { point =>
val score = model.predict(point.features)
(if (score > 0.5) 1.0 else 0.0, point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(s"$param tree depth", metrics.areaUnderROC)
}
dtResultsEntropy.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.2f%%") }val dtResultsGini = Seq(1, 2, 3, 4, 5, 10, 20).map { param =>
val model = trainDTWithParams(data, param, Gini)
val scoreAndLabels = data.map { point =>
val score = model.predict(point.features)
(if (score > 0.5) 1.0 else 0.0, point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(s"$param tree depth", metrics.areaUnderROC)
}
dtResultsGini.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.2f%%") }3.朴素贝叶斯
def trainNBWithParams(input: RDD[LabeledPoint], lambda: Double) = {
val nb = new NaiveBayes
nb.setLambda(lambda)
nb.run(input)
}
val nbResults = Seq(0.001, 0.01, 0.1, 1.0, 10.0).map { param =>
val model = trainNBWithParams(dataNB, param)
val scoreAndLabels = dataNB.map { point =>
(model.predict(point.features), point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(s"$param lambda", metrics.areaUnderROC)
}
nbResults.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.2f%%") }4.交叉验证
val trainTestSplit = scaledDataCats.randomSplit(Array(0.6, 0.4), 123)
val train = trainTestSplit(0)
val test = trainTestSplit(1)val regResultsTest = Seq(0.0, 0.001, 0.0025, 0.005, 0.01).map { param =>
val model = trainWithParams(train, param, numIterations, new SquaredL2Updater, 1.0)
createMetrics(s"$param L2 regularization parameter", test, model)
}
regResultsTest.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.6f%%") }val regResultsTrain = Seq(0.0, 0.001, 0.0025, 0.005, 0.01).map { param =>
val model = trainWithParams(train, param, numIterations, new SquaredL2Updater, 1.0)
createMetrics(s"$param L2 regularization parameter", train, model)
}
regResultsTrain.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.6f%%") }














 3120
3120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









