







 本文介绍了在Spark上如何获取和处理MovieLens数据集,包括数据的探索、可视化和预处理步骤。通过IPython和matplotlib进行数据探索,对用户、电影和评级数据进行了详细分析,展示了如何处理类别特征,为机器学习模型准备数据。
本文介绍了在Spark上如何获取和处理MovieLens数据集,包括数据的探索、可视化和预处理步骤。通过IPython和matplotlib进行数据探索,对用户、电影和评级数据进行了详细分析,展示了如何处理类别特征,为机器学习模型准备数据。
3. Spark上数据的获取、处理与准备
3.1 获取公开数据集
MovieLens数据集:包含表示多个用户对多部电影的10万次评级数据,也包含电影元数据和用户属性信息。
- 下载数据集,解压
unzip ml-100k.zip- 会创建一个名为ml-100k的文件夹,进入文件夹
cd ml-100k其中重要的文件有u.user(用户属性文件)、u.item(电影元数据)和u.data(用户对电影的评级)
- u.user文件包含user.id(用户ID)、age(年龄)、gender(性别)、occupation(职业)、和ZIP code(邮政编码)这些属性。
head -5 u.user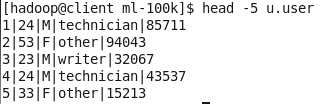
- u.item文件则包含movie id、title、release date、IMDB link和电影分类相关属性。
head -5 u.item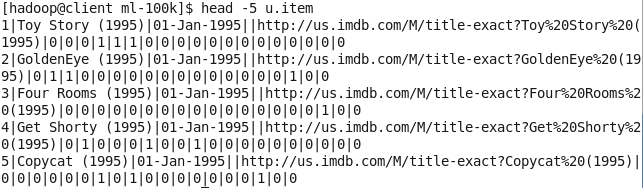
- u.data文件包含user id、movie id、rating(从1到5)和timestamp属性。
head -5 u.data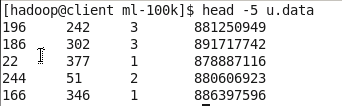
3.2 探索与可视化数据
通过IPython交互式终端和matplotlib库来对数据进行处理和可视化。需要安装Anaconda,选择python 2.7。
在启动PySpark终端是,我们可以使用IPython而非标准的Python shell。启动时向IPython传入其他参数,让它在启动时也启用pylab功能。
IPYTHON=1 IPYTHON_OPTS="--pylab" ./bin/pyspark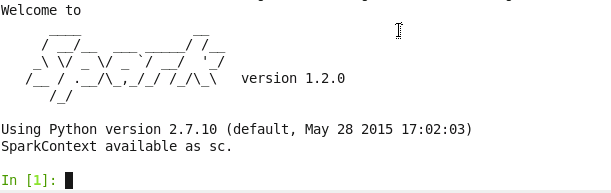
3.2.1 探索用户数据
user_data = sc.textFile("PATH/ml-100k/u.user")
user_data.first()其输出如下:

统计用户、性别、职业和邮编的数目
user_fields = user_data.map(lambda line: line.split("|"))
num_users = user_fields.map(lambda fields: fields[0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









