







本次实践项目选自kaggle数据集New York City Airbnb Open Data,Airbnb是全球的民宿短租公寓预订平台,这份数据集也正是来自于Airbnb公开的数据。数据集下载链接如下。
#导入需要用到的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.image as mping
%matplotlib inline
import seaborn as sns首先导入数据,拿到数据后的第一件事就是查看头部信息
airbnb = pd.read_csv("E:/Kaggle/AB_NYC_2019.csv")
airbnb.head()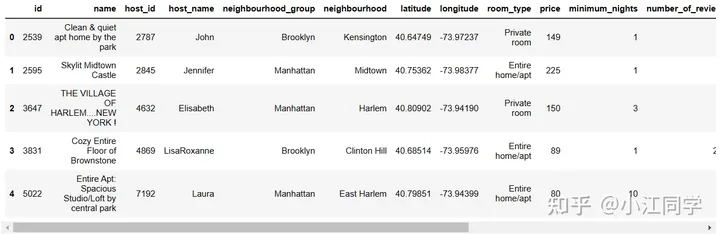
对图中数据进行解读,其中不易理解的列:neighbourhood_group:行政区;neighbourhood :社区;latitude:纬度;longitude:经度;number_of_revivews:评论数量;minimum_night:最少租住天数
# 查看数据总数
len(airbnb)
# 查看每列的数据类型
airbnb.dtypes
# 查看缺失值
airbnb.isnull().sum()
从缺失值这里可以看出,其中last_review与reviews_per_month缺失的厉害,但是这两列中,缺失值就代表着0,比如最后一次评论缺失,就代表着没有人评论,每月平均评论缺失,也代表着没有人评论,因此接下来我们将对此展开数据清洗。首先删除不需要的列。
airbnb.drop(['id','host_name','last_review'], axis=1, inplace=True) # 在drop函数中,axis=1代表列,inplace=True表示删除后原dataframe也会改变
# 检测是否删除成功
airbnb.head(3) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2232
2232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









