







CNNs系列---AlexNet介绍
导言
我们将开启关于卷积神经网络的探索,这里有必要进行一些简要的说明和前提背景介绍。深度学习(我主要感兴趣的方向是目标检测)的学习和探索,离不开对卷积神经网络。然而卷积神经网络本身却是一个黑盒,难以用数学的方式准确的进行描述,通常是通过结果去反向分析一个模型的好坏,这也就成了大多数人口中调侃的一般“深度学习如炼丹”。但是如今深度学习的火爆(ChatGPT,Segment Anything等),也从一定程度上佐证,我们目前提出的卷积神经网络至少在图像、语音语义等领域是一个很重要的研究方向。
为了能够对深度学习(目标检测、语义分割)进行宽中窥豹,特意开启了关于神经网络的学习,来加深我们对现有的、影响深刻的网络的了解。我们这个系列的笔记本身就是相当于从零开始,所以我们将从最简单的模型开始,并花大量的时间去对模型去探索,对有疑惑的点通过实践来验证,以形成所谓的“经验”。
为了能够对卷积神经网络有一定的了解,我们首先会根据卷积神经网络的发展和模型的复杂程度等考量进行学习,通过由易入深的方式逐步探索。当然也没有办法保证一篇笔记可以记录整个网络的探索,也无法保证我们可以通过一周的实践可以对网络的的重点都能过一遍(因为我们需要花大量的时间去训练、调参等)。
声明:
- 目前我们所有的代码都是基于
PyTorch编写的 - 我们假设你已经对深度学习的一些基本知识有一定的了解,并且可以使用pytorch编写一些简单的demo
AlexNet介绍
1. 网络结构
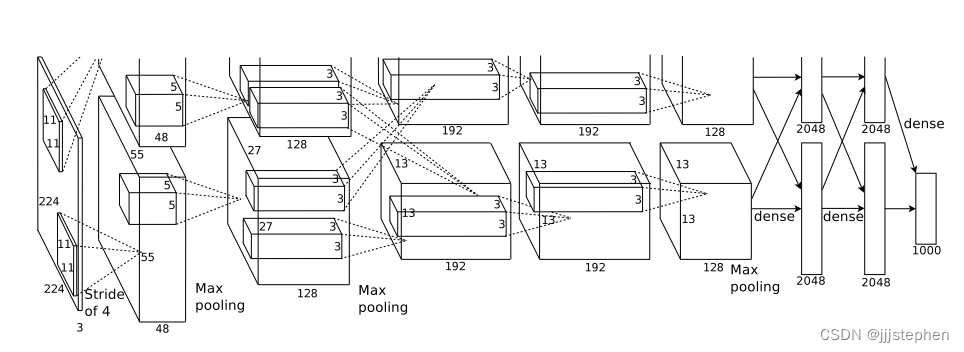
作者在当时提出AlexNet时,使用了两款GPU进行训练,所以会出现两组的卷积,并且基于如上的网络设计,出现了一个现象如下图所示:

图中,顶部48个内核在GPU1上学习,而底部48个内核在GPU2上学习。在GPU1上训练出来的结果大多是与颜色无关的特征,在GPU2上训练出来的结果大多是与颜色相关的特征。
出现这一现象最后也不了了之了(谁能给解释一下呢?),因为后续人们在训练AlexNet时,基本上在一张GPU中就可以完成。当然,AlexNet的网络结构就需要做一定的调整(后续我们将基于这个我把网络进行讲解)。

注意:原图输入是224*224,但是实际上进行了随机裁剪,实际大小为227*277
import torch
import torch.nn as nn
from torchsummary import summary
class AlexNet(nn.Module):
def __init__(self, class_num = 5):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# input[3, 227, 227] output[96, 55, 55]
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(inplace=True),
# output[96, 27, 27]
nn.MaxPool2d(kernel_size=3, stride=2),
# output[256, 27, 27]
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
# output[256, 13, 13]
nn.MaxPool2d(kernel_size=3, stride=2),
# output[384, 13, 13]
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# output[384, 13, 13]
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# output[256, 13, 13]
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# output[256, 6, 6]
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, class_num),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
(1) 参数量、计算量和输出尺寸计算公式
首先,我们定义输入的图像(input_image)的尺寸为
W
×
H
W\times H
W×H(一般情况下,我们输入网络中的图像
W
=
H
W=H
W=H),所以我们这里定义输入图像尺寸为input_size。
然后,我们定义卷积的参数为 k × k × c k \times k \times c k×k×c,这里 k k k为卷积核的宽、高(一般我们定义的卷积的宽高都相等), c c c为卷积核的通道数。
输出的feature map尺寸为
W
′
×
H
′
W' \times H'
W′×H′。
卷积的步长为stride
输出通道数为channels
卷积时图像扩充边界为padding
参数量 = ∑ i N ( k i 2 c + 1 ) × c h a n n e l s 参数量 = \sum_i^{N}(k_i^2c+1)\times channels 参数量=i∑N(ki2c+1)×channels 运算量 = ∑ i N 参数 量 i × W ′ H ′ 运算量=\sum_i^{N}参数量_i\times W'H' 运算量=i∑N参数量i×W′H′ o u t p u t _ s i z e = ( i n p u t _ s i z e − k + 2 ∗ p a d d i n g ) / s t r i d e + 1 output\_size=(input\_size-k + 2 * padding)/stride + 1 output_size=(input_size−k+2∗padding)/stride+1
(2) 网络参数解析
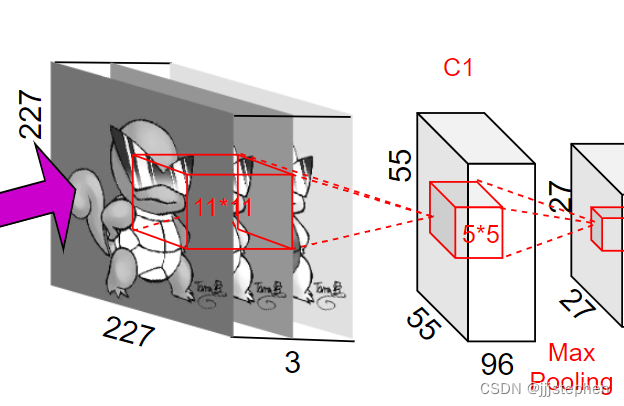
输入层为[224,224,3]的图像,padding后的图像为[227,227,3]
第一层,使用了96个11*11的卷积核,步长(stride)为4,padding为0
- 参数量 = (11 * 11 * 3 + 1)* 96 = 34944
- 计算量 = 34944 * 55 * 55 = 105705600
- 第一层卷积层输出尺寸 = ( 227 − 11 + 0 × 2 ) / 4 + 1 = 55 (227 - 11 + 0 \times 2) / 4 + 1=55 (227−11+0×2)/4+1=55
最大池化层,使用了卷积核尺寸为3*3,步长(stride)为2
- 第一层最大池化层输出尺寸 = ( 55 − 3 + 0 × 2 ) / 2 + 1 = 27 (55 - 3 + 0 \times 2) / 2 + 1=27 (55−3+0×2)/2+1=27
第一层卷积层输出,第二层输入为[27,27,96]
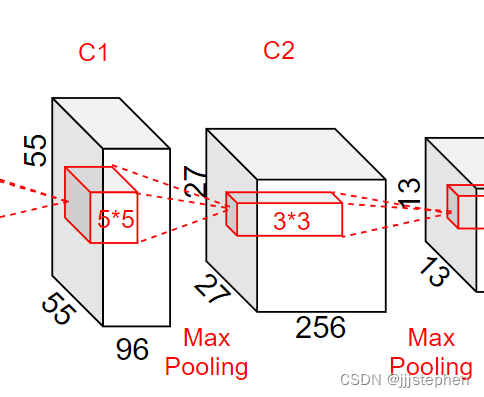
第二层输入为[27,27,96],使用了256个5*5的卷积核,步长(stride)为1,padding为2
- 参数量 = (5 * 5 * 96 + 1)* 256 = 614656
- 计算量 = 614656* 27 * 27 = 448084224
- 第二层卷积层输出尺寸 = ( 27 − 5 + 2 × 2 ) / 1 + 1 = 27 (27 - 5 + 2 \times 2) / 1 + 1=27 (27−5+2×2)/1+1=27
最大池化层,使用了卷积核尺寸为3*3,步长(stride)为2
- 第二层最大池化层输出尺寸 = ( 27 − 3 + 0 × 2 ) / 2 + 1 = 13 (27 - 3 + 0 \times 2) / 2 + 1=13 (27−3+0×2)/2+1=13
第二层卷积层输出,第三层输入为[13,13,256]
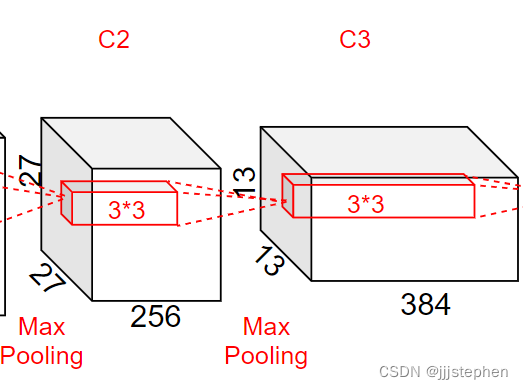
第三层输入为[13,13,256],使用了384个3*3的卷积核,步长(stride)为1,padding为1
- 参数量 = (3 * 3 * 256 + 1)* 384 = 885120
- 计算量 = 885120* 13 * 13 = 149585280
- 第三层卷积层输出尺寸 = ( 13 − 3 + 1 × 2 ) / 1 + 1 = 13 (13 - 3 + 1 \times 2) / 1 + 1=13 (13−3+1×2)/1+1=13
第三层卷积层输出,第四层输入为[13,13,384]

第四层输入为[13,13,384],使用了384个3*3的卷积核,步长(stride)为1,padding为1
- 参数量 = (3 * 3 * 384 + 1)* 384 = 1327488
- 计算量 = 1327488 * 13 * 13 = 224345472
- 第四层卷积层输出尺寸 = ( 13 − 3 + 1 × 2 ) / 1 + 1 = 13 (13 - 3 + 1 \times 2) / 1 + 1=13 (13−3+1×2)/1+1=13
第四层卷积层输出,第四层输入为[13,13,384]
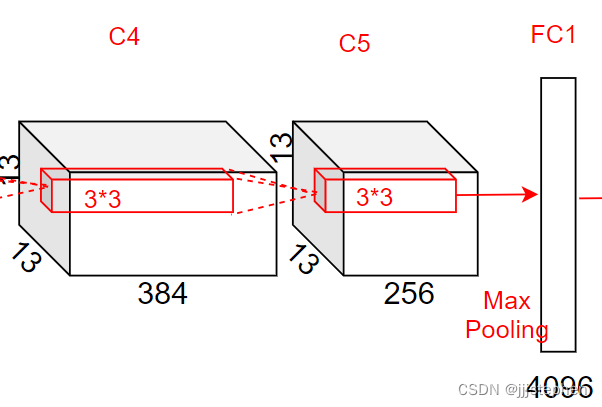
第五层输入为[13,13,384],使用了256个3*3的卷积核,步长(stride)为1,padding为1
- 参数量 = (3 * 3 * 384 + 1)* 256 = 884992
- 计算量 = 884992 * 13 * 13 = 149563648
- 第五层卷积层输出尺寸 = ( 13 − 3 + 1 × 2 ) / 1 + 1 = 13 (13 - 3 + 1 \times 2) / 1 + 1=13 (13−3+1×2)/1+1=13
最大池化层,使用了卷积核尺寸为3*3,步长(stride)为2
- 第二层最大池化层输出尺寸 = ( 13 − 3 + 0 × 2 ) / 2 + 1 = 6 (13 - 3 + 0 \times 2) / 2 + 1=6 (13−3+0×2)/2+1=6
第五层卷积层输出,第六层输入为[6,6,256]
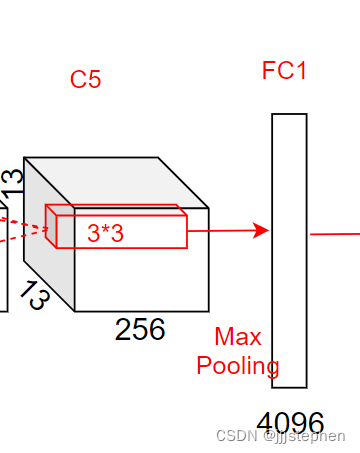
第六层输入为[6,6,256],使用了4096个1*1的卷积核
- 参数量 = (6 * 6 * 256 + 1)* 4096 = 37752862
- 计算量 = 37752862* 1 * 1 = 37752862
第六层全连接层输出,第七层输入为[-1,4096]
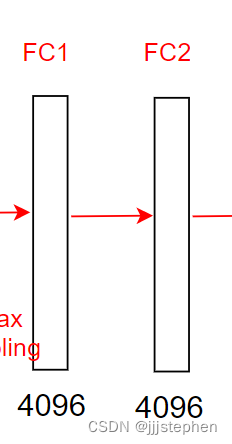
第六层输入为[-1,4096],使用了4096个1*1的卷积核
- 参数量 = (1 * 1 * 4096 + 1)* 4096 = 16781312
- 计算量 = 16781312 * 1 * 1 = 16781312
第七层全连接层输出,第八层输入为[-1,4096]
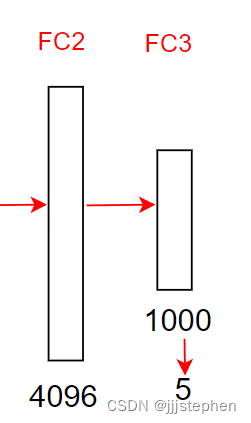
第七层输入为[-1,4096],使用了5个1*1的卷积核
- 参数量 = (1 * 1 * 4096 + 1)* 5= 20485
- 计算量 = 20485 * 1 * 1 = 20485
第七层全连接层输出,第八层输入为[-1,5]
综上,总的训练参数量为58301829,计算量为1131885883
==========================================================================================
==========================================================================================
├─Sequential: 1-1 [-1, 256, 6, 6] --
| └─Conv2d: 2-1 [-1, 96, 55, 55] 34,944
| └─ReLU: 2-2 [-1, 96, 55, 55] --
| └─MaxPool2d: 2-3 [-1, 96, 27, 27] --
| └─Conv2d: 2-4 [-1, 256, 27, 27] 614,656
| └─ReLU: 2-5 [-1, 256, 27, 27] --
| └─MaxPool2d: 2-6 [-1, 256, 13, 13] --
| └─Conv2d: 2-7 [-1, 384, 13, 13] 885,120
| └─ReLU: 2-8 [-1, 384, 13, 13] --
| └─Conv2d: 2-9 [-1, 384, 13, 13] 1,327,488
| └─ReLU: 2-10 [-1, 384, 13, 13] --
| └─Conv2d: 2-11 [-1, 256, 13, 13] 884,992
| └─ReLU: 2-12 [-1, 256, 13, 13] --
| └─MaxPool2d: 2-13 [-1, 256, 6, 6] --
├─Sequential: 1-2 [-1, 5] --
| └─Linear: 2-14 [-1, 4096] 37,752,832
| └─ReLU: 2-15 [-1, 4096] --
| └─Dropout: 2-16 [-1, 4096] --
| └─Linear: 2-17 [-1, 4096] 16,781,312
| └─ReLU: 2-18 [-1, 4096] --
| └─Linear: 2-19 [-1, 5] 20,485
==========================================================================================
Total params: 58,301,829
Trainable params: 58,301,829
Non-trainable params: 0
Total mult-adds (G): 1.19
==========================================================================================
Input size (MB): 0.59
Forward/backward pass size (MB): 5.02
Params size (MB): 222.40
Estimated Total Size (MB): 228.02
==========================================================================================
2.AlexNet中涉及到的知识点
(1) 基本概念
过拟合:在训练集上表现很好,验证集核测试阶段很差。即为了得到一致性假设过于严格而导致模型的泛化能力差。
过拟合的表现:
- 训练集的正确率不增反减
- 验证集的正确率不再发生变化
- 训练集的error一直再下降,但验证集的error不增反减
过拟合的产生原因:
- 样本方面
- 用于训练的样本数量过少
- 训练样本的噪声过大
- 模型方面
- 参数过多,模型太复杂
- 网络层数过多,导致后面学习到的特征不够具有代表性
(2) AlexNet网络结构的贡献
-
引用
ReLU激活函数深度学习在模型训练中时间开销是一个很重要的考量因素。采用
ReLU的卷积神经的网络训练时间比等价的tanh单元要快好几倍。同时,ReLU有效防止了过拟合现象的出现。由于ReLU激活函数导出性能突出,使得其在深度学习框架中占有重要的地位。

上图时AlexNet论文中的图片,其中虚线时采用tanh激活函数的training error,实线时采用ReLU激活函数的training error。关于采用不同激活函数training error的具体表现我们将在后续关于AlexNet的具体讲解中进行实验,并对实验数据进行分析。当然,在实际中
training error的快速收敛核许多因素相关,如学习率等,这些内容同样我们将在后续关于AlexNet的具体讲解中进行实验,并对实验数据进行分析。 -
overlapping pooling操作
池化层总结了统一卷积核卷积产生的特征映射中相邻的神经元组的输出(Pooling layers in CNNs summarize the outputs of neighboring groups of neurons in the same kernel map)。这是引用了论文中的一句话,关于这句话我还没有更加深入的理解,有深入理解的同学请批评指正。传统上,由相邻池化单元汇总的邻域不重叠。如,图像大小为
256*256,pooling size=2*2,stride=2,这样可以使得图像或者是feature map大小缩小为原来的一倍,变为128*128,在这个过程中没有发生池化层的层叠。AlexNet采用了overlapping pooling,即pooling size > stride。这样的操作非常像卷积操作,可以使得相邻像素之间产生信息交互核保留必要的联系。overlapping pooling也可以有效的防止过拟合的发生。 -
Dropout操作
采用Dropout可以说是AlexNet的最大的亮点之一,当然Dropout不是AlexNet首次提出的,关于Dropout具体细节和相关论文,我们将在AlexNet系列的最后(关于AlexNet的补充)进行介绍。论文中
Dropout中将概率设置为了0.5,即Dropout操作会将概率小于0.5的每个隐藏层神经元的输出设置为0(相当于去掉了一些神经节点),从而起到防止过拟合的作用。那些“失活的”神经元不再进行前向传播并且不参与反向传播,减少了复杂的神经元之间的相互影响。 -
网络层数的增加
与原始的LeNet相比,AlexNet网络深度更深,参数更大。关于LeNet的相关介绍,这里不再进行详细介绍,因为其影响力在深度学习领域远远低于AlexNet且其涉及到的相关知识全都包含到了AlexNet中,所以没必要对其进行介绍了。
更多请关注微信公众号【Hope Hut】:
















 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









