







目录
一、引言
在当今大数据时代,数据量呈指数级增长,传统的数据处理方式已经力不从心。Hadoop 作为大数据处理的核心框架,其 MapReduce 分布式计算模型发挥了关键作用。本文将深入探讨 Hadoop 中 MapReduce 的原理、架构、编程实现以及应用场景,并通过丰富的图示和示例来帮助读者理解这一强大的分布式计算框架。
二、MapReduce 原理
(一)基本概念
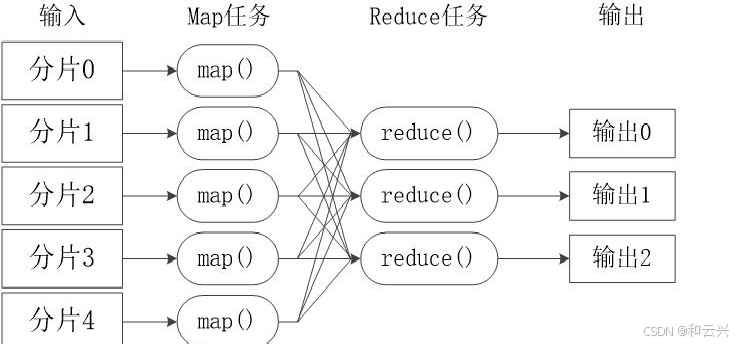
MapReduce 是一种编程模型,用于处理大规模数据集。它将数据处理任务抽象为两个主要阶段:Map 阶段和 Reduce 阶段。
(二)Map 阶段
- 数据读取与分割
输入数据通常存储在 Hadoop 分布式文件系统(HDFS)中。在 Map 阶段,数据被分割成多个数据块(一般为 64MB 或 128MB),这些数据块被分配到集群中的不同节点上。每个数据块会启动一个 Map 任务。例如,对于一个存储大量文本文件的 HDFS,Map 任务会读取这些文本文件的部分内容。
2.映射操作
Map 函数接受一个键值对(<key, value>)作为输入,这里的 key 和 value 的含义取决于输入数据的格式。例如,在处理文本文件时,key 可以是文件中的行偏移量,value 是该行的文本内容。Map 函数对输入数据进行处理,输出一系列新的中间键值对。以单词计数为例,Map 函数可能会将一行文本中的每个单词作为新的 key,值为 1,表示这个单词出现了一次(如 <“hello”, 1>)。
(三)Reduce 阶段
- 数据分组与排序
Map 阶段输出的中间键值对会根据 key 进行分组和排序。具有相同 key 的键值对会被聚集在一起。例如,所有以 “hello” 为 key 的中间键值对会被归为一组。
三、MapReduce 架构
(一)JobTracker 和 TaskTracker
- JobTracker
JobTracker 是 Hadoop MapReduce 的主节点,它负责接收用户提交的作业,将作业分解成多个任务(包括 Map 任务和 Reduce 任务),并调度这些任务到集群中的各个 TaskTracker 节点上执行。它还监控任务的执行进度和状态,在任务失败时重新调度任务。 - TaskTracker
TaskTracker 运行在集群中的从节点上,它接收来自 JobTracker 的任务,并在本地执行这些任务。每个 TaskTracker 可以同时执行多个 Map 任务和 Reduce 任务,具体数量取决于节点的资源配置。它会定期向 JobTracker 汇报任务的执行进度和状态。
(二)数据本地化
为了减少数据传输开销,Hadoop 尽量将 Map 任务分配到存储数据的数据块所在的节点上执行。这就是数据本地化优化。如果无法在数据所在节点上执行 Map 任务,才会考虑从其他节点获取数据。
(三)图示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









