







在《第二篇|Spark Core编程指南》一文中,对Spark的核心模块进行了讲解。本文将讨论Spark的另外一个重要模块–Spark SQL,Spark SQL是在Shark的基础之上构建的,于2014年5月发布。从名称上可以看出,该模块是Spark提供的关系型操作API,实现了SQL-on-Spark的功能。对于一些熟悉SQL的用户,可以直接使用SQL在Spark上进行复杂的数据处理。通过本文,你可以了解到:
- Spark SQL简介
- DataFrame API&DataSet API
- Catalyst Optimizer优化器
- Spark SQL基本操作
- Spark SQL的数据源
- RDD与DataFrame相互转换
- Thrift server与Spark SQL CLI

Spark SQL简介
Spark SQL是Spark的其中一个模块,用于结构化数据处理。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息,Spark SQL会使用这些额外的信息来执行额外的优化。使用SparkSQL的方式有很多种,包括SQL、DataFrame API以及Dataset API。值得注意的是,无论使用何种方式何种语言,其执行引擎都是相同的。实现这种统一,意味着开发人员可以轻松地在不同的API之间来回切换,从而使数据处理更加地灵活。
DataFrame API&DataSet API
DataFrame API
DataFrame代表一个不可变的分布式数据集合,其核心目的是让开发者面对数据处理时,只关心要做什么,而不用关心怎么去做,将一些优化的工作交由Spark框架本身去处理。DataFrame是具有Schema信息的,也就是说可以被看做具有字段名称和类型的数据,类似于关系型数据库中的表,但是底层做了很多的优化。创建了DataFrame之后,就可以使用SQL进行数据处理。
用户可以从多种数据源中构造DataFrame,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。DataFrame API支持Scala,Java,Python和R,在Scala和Java中,row类型的DataSet代表DataFrame,即Dataset[Row]等同于DataFrame。
DataSet API
DataSet是Spark 1.6中添加的新接口,是DataFrame的扩展,它具有RDD的优点(强类型输入,支持强大的lambda函数)以及Spark SQL的优化执行引擎的优点。可以通过JVM对象构建DataSet,然后使用函数转换(map,flatMap,filter)。值得注意的是,Dataset API在Scala和 Java中可用,Python不支持Dataset API。
另外,DataSet API可以减少内存的使用,由于Spark框架知道DataSet的数据结构,因此在持久化DataSet时可以节省很多的内存空间。
Catalyst Optimizer优化器
在Catalyst中,存在两种类型的计划:
- 逻辑计划(Logical Plan):定义数据集上的计算,尚未定义如何去执行计算。每个逻辑计划定义了一系列的用户代码所需要的属性(查询字段)和约束(where条件),但是不定义该如何执行。具体如下图所示:
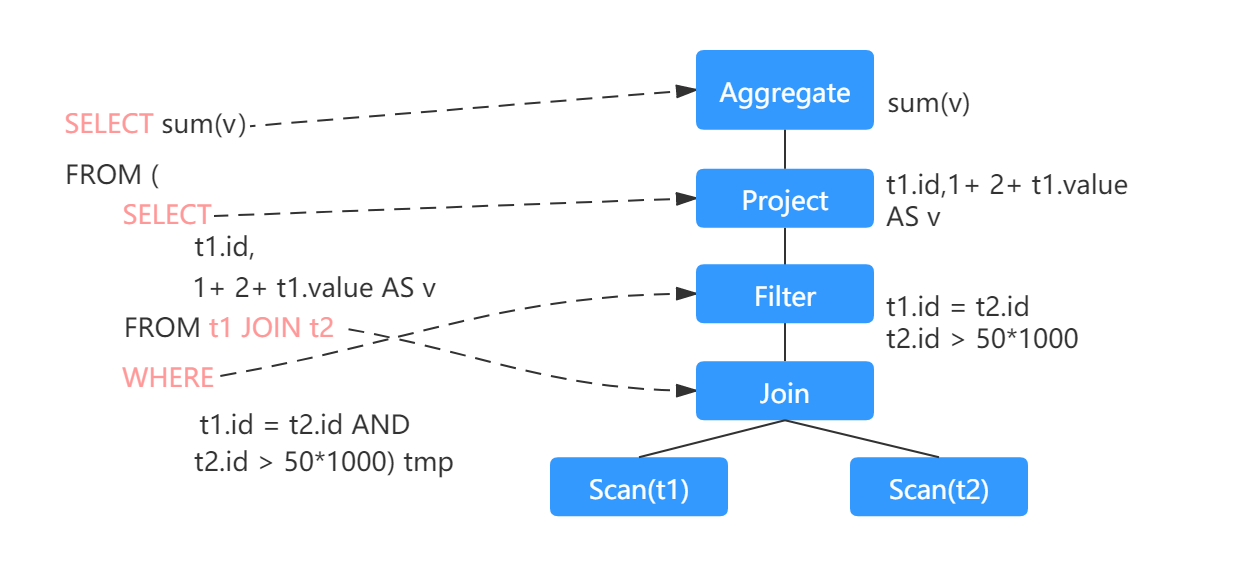
- 物理计划(Physical Plan):物理计划是从逻辑计划生成的,定义了如何执行计算,是可执行的。举个栗子:逻辑计划中的JOIN会被转换为物理计划中的sort merge JOIN。需要注意,Spark会生成多个物理计划,然后选择成本最低的物理计划。具体如下图所示:
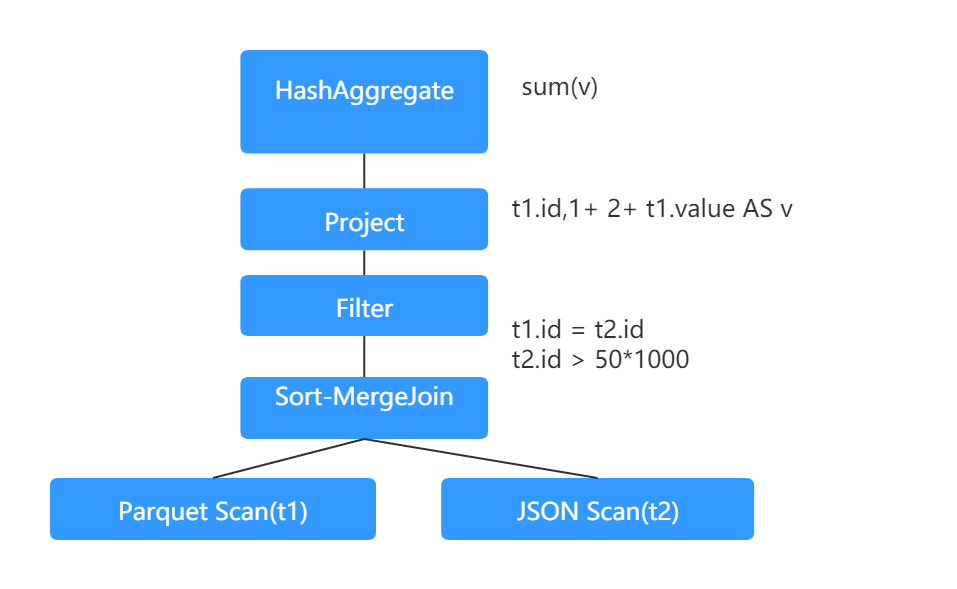
在Spark SQL中,所有的算子操作会被转换成AST(abstract syntax tree,抽象语法树),然后将其传递给Catalyst优化器。该优化器是在Scala的函数式编程基础会上构建的,Catalyst支持基于规则的(rule-based)和基于成本的(cost-based)优化策略。
Spark SQL的查询计划包括4个阶段(见下图):
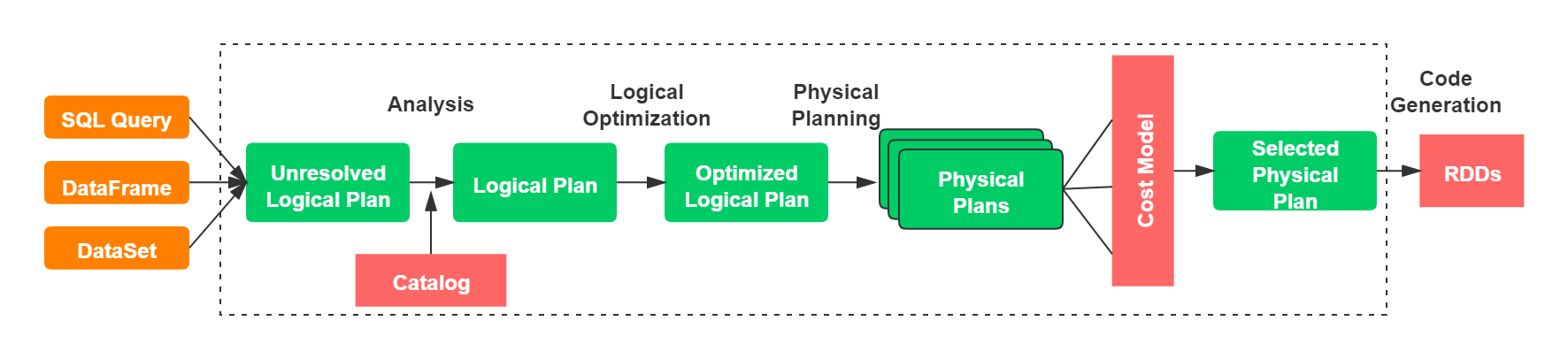
- 1.分析
- 2.逻辑优化
- 3.物理计划
- 4.生成代码,将查询部分编译成Java字节码
**注意:**在物理计划阶段,Catalyst会生成多个计划,并且会计算每个计划的成本,然后比较这些计划的成本的大小,即基于成本的策略。在其他阶段,都是基于规则的的优化策略。
分析
Unresolved Logical plan --> Logical plan。Spark SQL的查询计划首先起始于由SQL解析器返回的AST,或者是由API构建的DataFrame对象。在这两种情况下,都会存在未处理的属性引用(某个查询字段可能不存在,或者数据类型错误),比如查询语句:SELECT col FROM sales,关于字段col的类型,或者该字段是否是一个有效的字段,只有等到查看该sales表时才会清楚。当不能确定一个属性字段的类型或者没能够与输入表进行匹配时,称之为未处理的。Spark SQL使用Catalyst的规则以及Catalog对象(能够访问数据源的表信息)来处理这些属性。首先会构建一个Unresolved Logical Plan树,然后作用一系列的规则,最后生成Logical Plan。
逻辑优化
Logical plan --> Optimized Logical Plan。逻辑优化阶段使用基于规则的优化策略,比如谓词下推、投影裁剪等。经过一些列优化过后,生成优化的逻辑计划Optimized Logical Plan。
物理计划
Optimized Logical Plan -->physical Plan。在物理计划阶段,Spark SQL会将优化的逻辑计划生成多个物理执行计划,然后使用Cost Model计算每个物理计划的成本,最终选择一个物理计划。在这个阶段,如果确定一张表很小(可以持久化到内存),Spark SQL会使用broadcast join。
需要注意的是,物理计划器也会使用基于规则的优化策略,比如将投影、过滤操作管道化一个Spark的map算子。此外,还会将逻辑计划阶段的操作推到数据源端(支持谓词下推、投影下推)。
代码生成
查询优化的最终阶段是生成Java字节码,使用Quasi quotes来完成这项工作的。
经过上面的分析,对Catalyst Optimizer有了初步的了解。关于Spark的其他组件是如何与Catalyst Optimizer交互的呢?具体如下图所示:
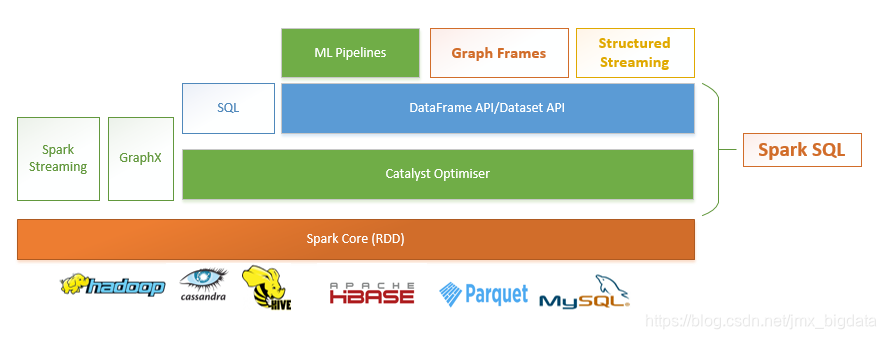
如上图所示:ML Pipelines, Structured streaming以及 GraphFrames都使用了DataFrame/Dataset
APIs,并且都得益于 Catalyst optimiser。
Quick Start
创建SparkSession
SparkSession是Dataset与DataFrame API的编程入口,从Spark2.0开始支持。用于统一原来的HiveContext和SQLContext,为了兼容两者,仍然保留这两个入口。通过一个SparkSession入口,提高了Spark的易用性。下面的代码展示了如何创建一个SparkSession:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
//导入隐式转换,比如将RDD转为DataFrame
import spark.implicits._
创建DataFrame
创建完SparkSession之后,可以使用SparkSession从已经存在的RDD、Hive表或者其他数据源中创建DataFrame。下面的示例使用的是从一个JSON文件数据源中创建DataFrame:
/**
* {"name":"Michael"}
* {"name":"Andy", "age":30}
* {"name":"Justin", "age":19}
*/
val df = spark.read.json("E://people.json")
//输出DataFrame的内容
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
DataFrame基本操作
创建完DataFrame之后,可以对其进行一些列的操作,具体如下面代码所示:
// 打印该DataFrame的信息
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// 查询name字段
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// 将每个人的age + 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// 查找age大于21的人员信息
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// 按照age分组,统计每种age的个数
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
在程序中使用SQL查询
上面的操作使用的是**DSL(domain-specific language)**方式,还可以直接使用SQL对DataFrame进行操作,具体如下所示:
// 将DataFrame注册为SQL的临时视图
// 该方法创建的是一个本地的临时视图,生命周期与其绑定的SparkSession会话相关
// 即如果创建该view的session结束了,该view也就消失了
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5238
5238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









