







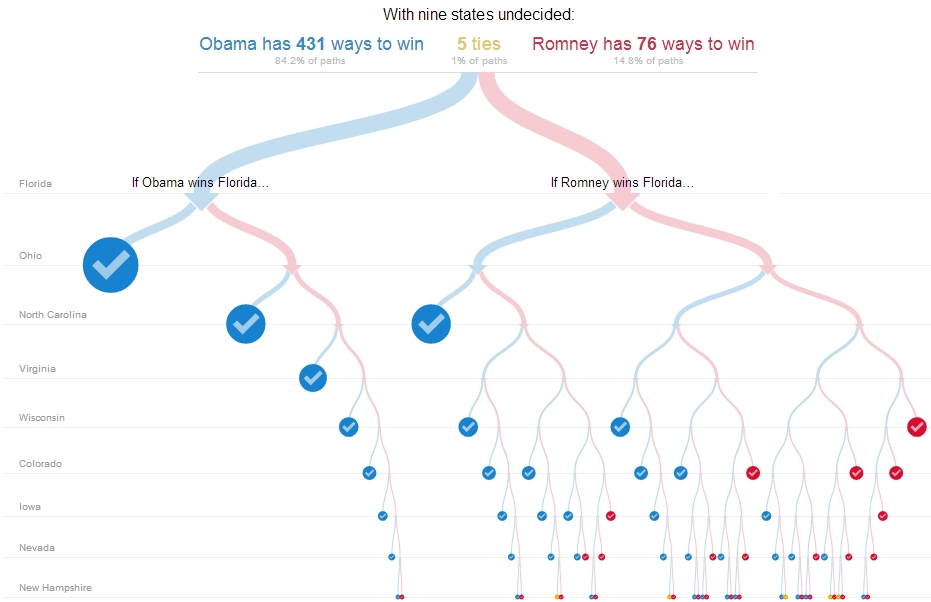
1 树形算法家族族谱
1.1 决策树
- 采用divide-and-conquer算法思想,递归构建
- 特征选择——决策树生成——树剪枝
- 互斥与完备:每个训练样本有且仅有一条路径规则
- 最终可能训练出多个,可能一个没有;从所有可能决策树中选择最优是NP问题,因此现实中常用启发式(heuristic)方法
- Loss Function:正则化的极大似然函数
树形表征
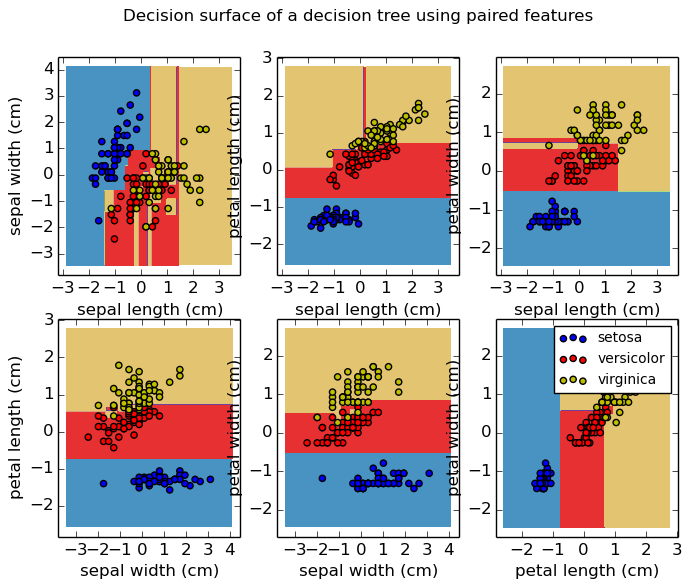
特征空间表征
1.1.1 ID3算法
采用信息增益决定每个节点选择哪个特征——启发认为信息增益大的特征具有更强的分类能力。
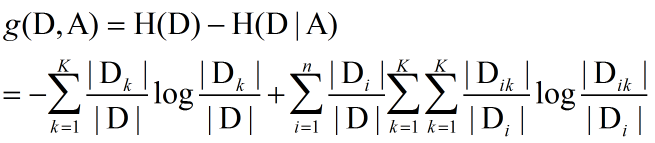
1.1.2 C4.5算法
采用信息增益比决定每个节点选择哪个特征
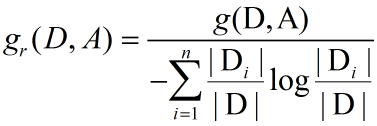
1.1.3 CART算法
CART假设决策树是二叉树(是/否),递归地二分每个特征
回归树:平方误差最小化准则
分类树:Gini指数最小化准则
1.1.4 剪枝
决策树的弱项就在于过拟合问题,因此通常需要剪枝后使用。
方法:最小化整体Loss Function
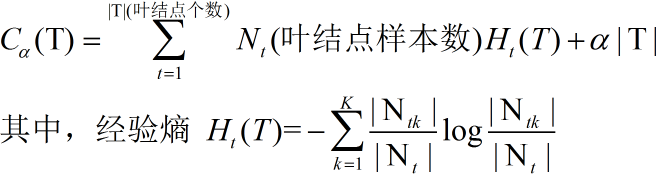
参数:α,表征了对模型复杂度的惩罚
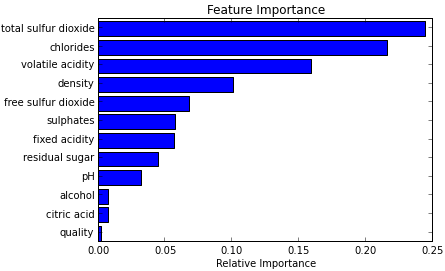
1.2 随机森林
- 能够处理高维数据,不用做特征选择
- 训练过程中,能检测到特征间的相互影响
- 训练完成后,能够给出哪个特征比较重要

随机森林由多个互不相关的决策树组成,每当有一个样本输入时,森林里的每棵决策树都会对样本进行一次分类打标处理,最后采取投票准则来决定样本属于哪一类。
行采样与列采样
行:样本。采取有放回的采样方式,也就是构建不同的决策树时,可能用到了相同样本。
列:特征。采取无放回的采样方式,保证特征的不相关。
相当于每棵树,在某些领域(特征)上都是专家,经过各专家的举手表决,选出最终结果。
用途
- 特征选择
- eg:特征在树里面的结点深度作为权重
- 分类 可以给出具体的概率值
- 回归
1.3 GBDT
Boosting is a powerful technique for combining multiple ‘base’ classifiers to produce
a form of committee whose performance can be significantly better than that of any
of the base classifiers.——《PRML》
1.3.1 Boosting
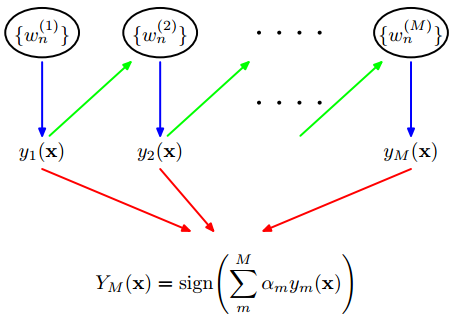
- 初始化每一维 wi(1)=1/N
- 对于每一个训练样本训练
- 通过合适的y最小化
Jm=∑i=1Nwi
- 通过合适的y最小化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









