







在阅读代码之前,需要先介绍一下Spark集群,主要参考了官网上的描述、源码以及源码注释,而关于Spark的其他一些概念,《RDD:基于内存的集群计算容错抽象》这篇论文已经讲得足够牛叉了,而且很权威,我就不扯淡了。
先上一张图(直接从官网拖下来~):
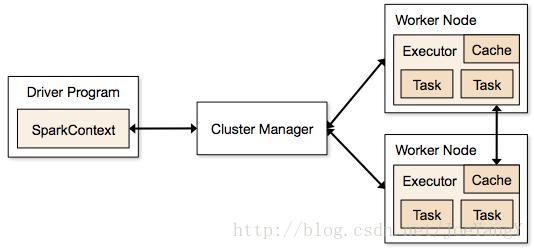
简介
Spark应用程序以一组独立的进程运行在集群上,并通过Driver中的SparkContext对象组织在一起。SparkContext对象会连接各种集群管理器(资源调度器,例如spark自带的manager、yarn、mesos),这些管理器会为应用分配资源。一旦连接完成, Spark访问集群中的executor(一组集群各个节点上的进程,用于真正运行计算和存储数据),然后将spark应用程序代码发送到这些executor中(比如jar包),最后发送task给这些executor,执行代码。每个spark应用程序在其整个运行期间独占executor,而executor内部会以多线程的方式并发运行task。这种方式无论从调度角度来看还是执行角度来说对于不同应用程序之间的隔离都很有帮助,但同时也意味着除非使用外置的文件系统(比如hdfs、tachyon之类),否则不同应用之间无法共享数据。
DriverProgram
DriverProgram即为我们自己编写的包含main函数并且会创建SparkContext的程序。DriverProgram在Spark中不仅代表了一个Spark应用程序的起点、包含了应用程序逻辑,同时也用于调度这个Spark应用程序(在后面分析SparkContext及相关组件时可以看到),所以虽然可以在实例化SparkContext时传入master地址远程调试代码、运行程序,但最好还是直接放到集群上去跑。
ClusterManager
这一部分主要以Spark自带的manager(也就是standalone模式)为例来介绍,关于mesos和yarn的分析就是另一个主题啦,有机会再深入研究一下。
Spark资源调度
Spark目前有这样几种在各个计算任务之间做资源调度的机制:第一,每个Spark应用程序运行在一组独立的executor进程上,Spark所在的clustermanager提供了对不同spark应用程序进行调度的功能;第二,在同一个Spark应用程序中,不同的线程提交的多个job(每次调用action方法即产生一个job进行提交)可能在同一时刻一起运行在spark之上,这在通过网络提供服务情景下十分常见(shark也正是这样运行的),所以spark在每个SparkContext对象中都包含了一个fairscheduler来调度同一个Sparkapplication内的资源。
Application之间的资源调度
当application运行在集群模式下,每个sparkapplication会得到一组executor(JVM),这组executor只会运行这个application的task和存储这个application的中间数据。在多个application运行的情况下,不同的clustermanager有不同的资源分配策略。
最简单的资源分配方式就是对资源进行静态分割,在这种情况下,每个application被指定了可以使用资源的最大值,并在其运行期间一直占用这部分资源。
在Spark的standalone模式下,application在被提交到集群后会以FIFO方式被执行,每个application在默认情况下都会尝试使用所有可用的节点。可以通过在application内设置spark.cores.max配置项来进行设置,也可以通过配置spark.executor.memory来控制executor所占用的内存。
当前没有任何一种方式支持在不同的application之间共享内存。如果需要在不同处理流程间共享数据,推荐的做法是启动一个独立的服务器application,这个application能够接受不同请求,并作用于同一个rdd之上。shark得jdbc服务就是一个很好的例子。在后续的版本中,像Tachyon这样的内存存储系统会提供一种新的途径来共享RDD而不用进行硬盘IO。
Application内资源调度
在前文提到过,在多线程提交job的情况下,一个appliction内多个job会同时运行在spark之上。Spark的调度器是线程安全的,并且支持实现服务器形式的application,用来并发地接收和处理不同的业务请求。
默认情况下,spark的调度器采用fifo(先进先出)模式:每个job被提交后,会先被拆成各个stage(通过DAGSchedular,如何拆分stage的可以参考RDD论文),stage是一组task的集合,当这些task被加载到executor上时,第一个job先对所有可用资源进行操作,然后是第二个...依次执行。如果排在前面的job不需要占用整个集群,那么排在后面的job也可以被立即执行,否则后面的job将会等待。
从spark0.8起,用户也可以将调度器配置成fair模式。在这种模式下,Spark采用一种公平的方式来调度任务,使一个application同时提交的job能够大体上平均地使用集群上的资源,这也就意味着当一个job长时间运行时,在此期间也能提交job并立即开始执行,而不用等前面这个长时间运行的job执行完了再开始,这一点在多用户访问的情景下特别有用。在driver中,通过配置StarkConf的spark.schedular.mode配置向为FAIR即可开始使用Fair调度器。
Fair调度器还支持将不同的job按池(pool)进行划分,并且可以对这些pool配置不同的参数,这样就能对不同的pool设置不同的优先级,将比较重要的job放到权重较高的pool中。默认情况下,一个新的job会被提交到defaultpool中,不过可以通过调用 SparkContext的setLocalProperty方法来配置spark.scheduler.pool来设置job将要被提交的pool,一旦设置后,当前线程所提交的job都会被放到指定的pool中。注意,这个设置是仅在当前线程中有效的,如果想要清除这个配置,掉同样的方法设置这个配置项的值为null即可。默认情况下,所有的pool会公平地获得集群资源,但在pool内部,默认情况下job还是以fifo的方式来进行资源调度的(当然也可以进行配置)。
用户可以通过一个xml来配置pool(可以参照conf/fairschedular.xml),并通过SparkConf的set方法来配置 spark.schedular.alloction.file配置项,值为配置文件的路径。
在配置文件中,pool标签的name属性为pool的名称,通过这个名称可以来指定线程提交job的目标pool;schedulingMode为pool内部的资源调度方式,可选FAIR或FIFO;weight代表pool获取资源的权重;minShare代表这个pool所占用的最小的core数量,默认为0,一旦进行配置后,这个pool中一旦有job提交就能立即获得core资源,而不用等其他pool里的job完成工作释放资源。
这部分是Spark中比较重要的部分之一,上面的描述是结合官网文档和自己的一些理解,后续必定会对这部分代码进行详细的分析。














 4189
4189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









