









”明月如霜,好风如水,清景无限 “
话不说说,直接上。
壹
先进王者官网:
https://pvp.qq.com/
然后找到内容中心-》英雄资料:

进入发现了,有全部的英雄信息:

f12发现,这个很简单,每个li标签就代表一个英雄,那么点击进单独的英雄界面发现:

很轻松地发现了,对应的SRC,也就是每个英雄对应皮肤的图片url。看起来,看起来相当简单啊???
import requests
from lxml import etree
import os
import re
from bs4 import BeautifulSoup
if not os .path.exists('./hero'):
os.mkdir('./hero')
path = "hero/"
url = "https://pvp.qq.com/web201605/herolist.shtml"
pic_url="https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg"
url_json = 'https://pvp.qq.com/web201605/js/herolist.json'
# headers = {
# 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
# }
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
herolist_json = requests.get(url_json).json() # 获取英雄列表json文件
hero_name = list(map(lambda x: x['cname'], herolist_json)) # 提取英雄的名字
hero_number = list(map(lambda x: x['ename'],herolist_json)) # 提取英雄的编号
nameTOnum=dict(zip(hero_name,hero_number))
response = requests.get(url=url,headers=headers)
html_text = response.text
tree = etree.HTML(html_text)
li_list=tree.xpath('//ul[@class="herolist clearfix"]/li')
before='https://pvp.qq.com/web201605/'
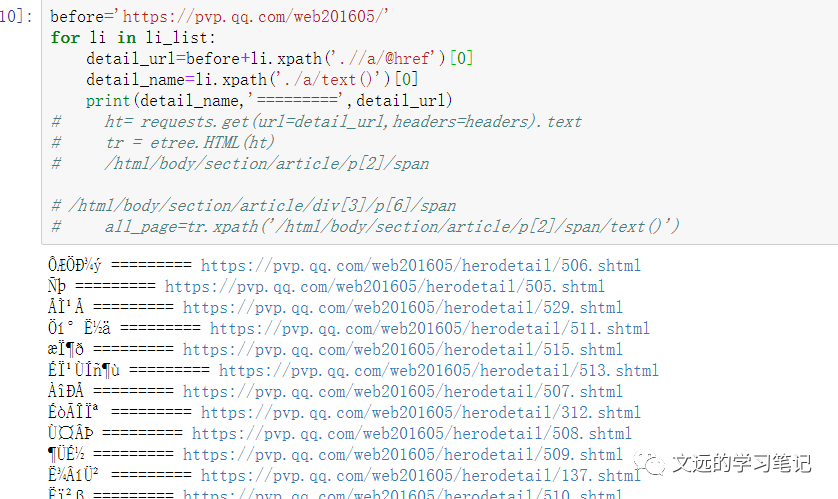
for li in li_list:
detail_url=before+li.xpath('.//a/@href')[0]
detail_name=li.xpath('./a/text()')[0]
detail_name = detail_name.encode('iso-8859-1').decode('gbk')
ht= requests.get(url=detail_url,headers=headers).text
tr = etree.HTML(ht)
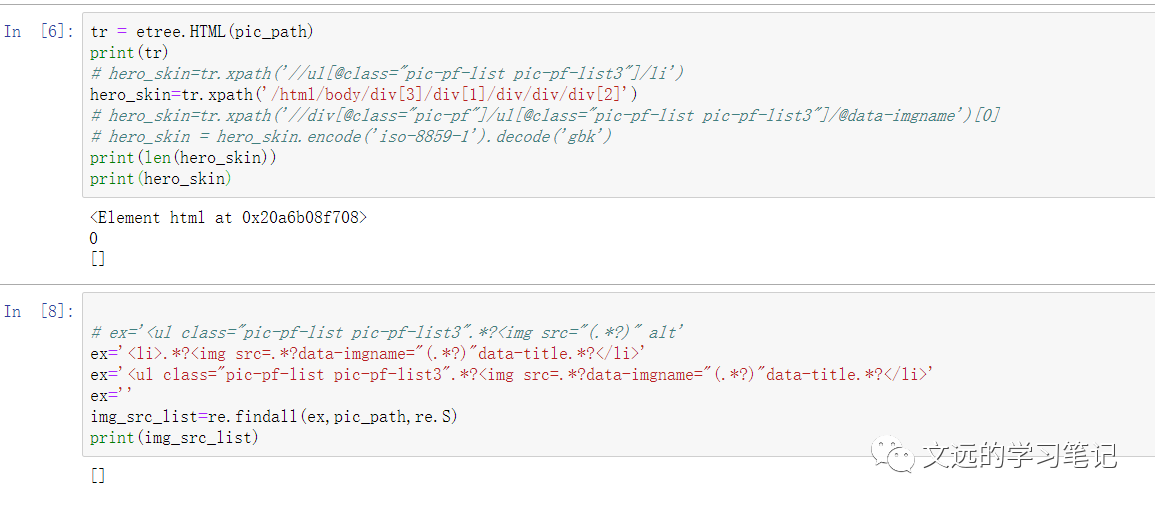
print(tr)
# hero_skin=tr.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/li')
hero_skin=tr.xpath('/html/body/div[3]/div[1]/div/div/div[2]')
# hero_skin=tr.xpath('//div[@class="pic-pf"]/ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0]
# hero_skin = hero_skin.encode('iso-8859-1').decode('gbk')
print(len(hero_skin))
print(hero_skin)
直接凉凉,空的。
贰
到底为啥呢?
我们先解决以下乱码问题。
来自某个大佬的总结:
只要将字符串(detail_name 为str类型)加上下面这句:
detail_name = detail_name.encode('iso-8859-1').decode('gbk')
而encode和decode类型咋确定呢?

为啥是空的,我们需要先对比一下,页面响应的html(text)数据:

这个时候就相当明显了,因为响应中没有了详细的皮肤照片信息,那么这个信息必然来自动态加载,f12看一下XHR(其实可以用selenium,对于动态加载会很方便),搞得文远把xpath,bs4和正则都尝试了一下:建议学好正则啊,正则很方便,推荐一个视频up:(讲得很直接有效)
https://www.bilibili.com/video/BV1zC4y1p7wDfrom=search&seid=3983830385641933215

哈哈,找到了,这个herolist.json。看了一下,发现只是英雄名称和一个对应的ename(英雄对应编号)
分析以下照片的url发现:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/106/106-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/106/106-bigskin-7.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/140/140-bigskin-4.jpg
其实ename就是104(关羽),106(小乔)。
那么回忆一下json数据的解析吧:
url = 'https://pvp.qq.com/web201605/js/herolist.json'
herolist_json = requests.get(url).json() # 获取英雄列表json文件
hero_name = list(map(lambda x: x['cname'], herolist_json)) # 提取英雄的名字
hero_number = list(map(lambda x: x['ename'],herolist_json)) # 提取英雄的编号
nameTOnum=dict(zip(hero_name,hero_number))
其实没两样,也就是个json()方法而已。
叁
到这里基本就结束了,但还有一个小点,每个英雄的皮肤数量不定。幸运的是,英雄单独界面里有英雄的皮肤名称。
<ul class="pic-pf-list pic-pf-list3" data-imgname="恋之微风&0|万圣前夜&0|天鹅之梦&26|纯白花嫁&11|缤纷独角兽&12|丁香结&1|青蛇&12">
<li>
<i class="">
<img src="//game.gtimg.cn/images/yxzj/img201606/heroimg/106/106-smallskin-1.jpg" alt="" data-imgname="//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/106/106-bigskin-1.jpg"
data-title="恋之微风" data-icon="0"></i><p>恋之微风</p>
</li>
方便的对应皮肤数量Num了。
例:
data-imgname="一骑当千&0|龙腾万里&16|天启骑士&0|冰锋战神&18|武圣&72"
也就是两下split()而已:
name_list=hero_skin_name.split('|')
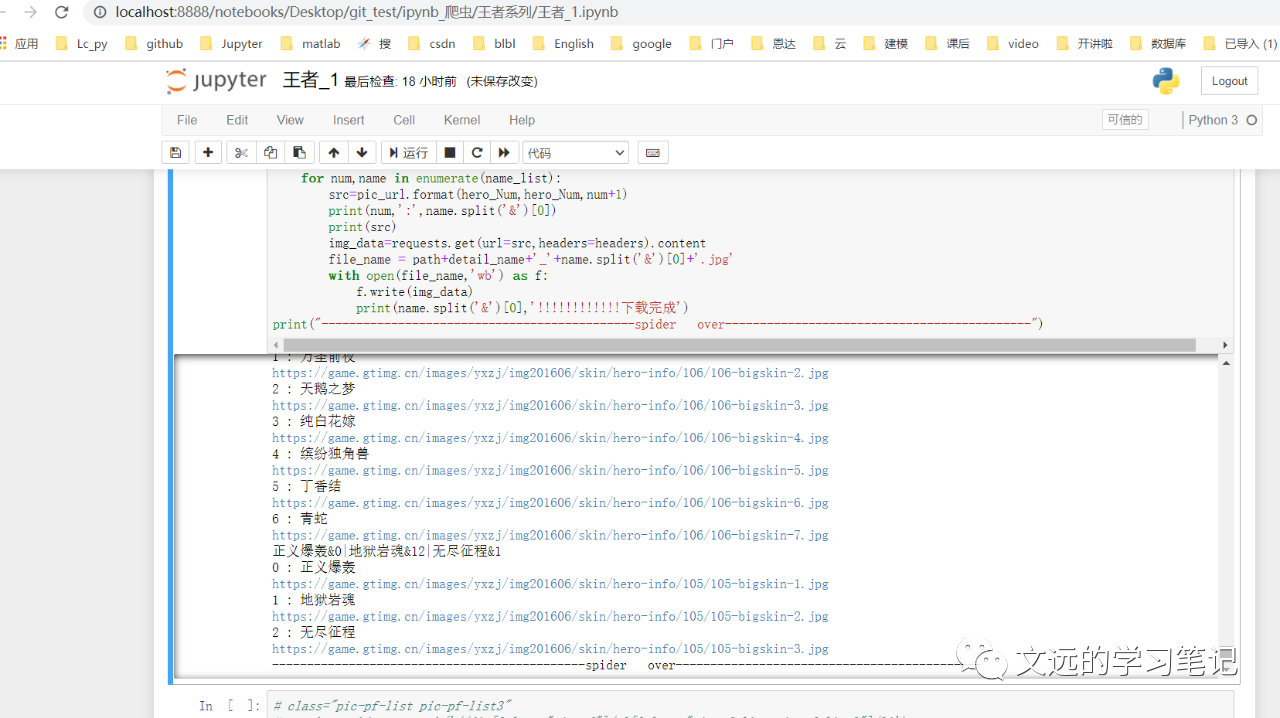
for num,name in enumerate(name_list):
name=name.split('&')[0]
print(num,':',name)
贴一下全部代码:
import requests
from lxml import etree
import os
import re
from bs4 import BeautifulSoup
if not os .path.exists('./hero'):
os.mkdir('./hero')
path = "hero/"
url = "https://pvp.qq.com/web201605/herolist.shtml"
pic_url="https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg"
url_json = 'https://pvp.qq.com/web201605/js/herolist.json'
# headers = {
# 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
# }
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
herolist_json = requests.get(url_json).json() # 获取英雄列表json文件
hero_name = list(map(lambda x: x['cname'], herolist_json)) # 提取英雄的名字
hero_number = list(map(lambda x: x['ename'],herolist_json)) # 提取英雄的编号
nameTOnum=dict(zip(hero_name,hero_number))
response = requests.get(url=url,headers=headers)
html_text = response.text
tree = etree.HTML(html_text)
li_list=tree.xpath('//ul[@class="herolist clearfix"]/li')
before='https://pvp.qq.com/web201605/'
for li in li_list:
detail_url=before+li.xpath('.//a/@href')[0]
detail_name=li.xpath('./a/text()')[0]
detail_name = detail_name.encode('iso-8859-1').decode('gbk')
hero_Num=nameTOnum[detail_name]
# print(detail_name,'=========',detail_url)
# with open(path+'PiFu.txt','a+',encoding='utf-8') as f:
# f.write(detail_name+':'+detail_url+'\n')
ht= requests.get(url=detail_url,headers=headers).text
ht=ht.encode('iso-8859-1').decode('gbk')
tr = etree.HTML(ht)
# soup = BeautifulSoup(ht,'lxml')
# li_all=soup.select('.pic-pf-list pic-pf-list3 >li')
# print(len(li_all))
# print(tr)
hero_skin_name=tr.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0]
print(hero_skin_name)
name_list=hero_skin_name.split('|')
for num,name in enumerate(name_list):
src=pic_url.format(hero_Num,hero_Num,num+1)
print(num,':',name.split('&')[0])
print(src)
img_data=requests.get(url=src,headers=headers).content
file_name = path+detail_name+'_'+name.split('&')[0]+'.jpg'
with open(file_name,'wb') as f:
f.write(img_data)
print(name.split('&')[0],'!!!!!!!!!!!!下载完成')
print("---------------------------------------------spider over--------------------------------------------")
肆
最后,放一下效果:

需要源码的直接点击阅读原文,喜欢的同学记得点赞和点击在看,还有记得Star啊,把文远设为星标就不会错过文章了!!!
END
作者:不爱跑马的影迷不是好程序猿
喜欢的话请关注点赞👇 👇👇 👇
















 1689
1689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









