






1.数据准备
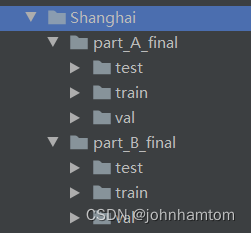
经过上一篇博客(https://blog.csdn.net/johnhamtom/article/details/128731524?spm=1001.2014.3001.5502)的数据处理介绍,现在已经将数据处理为了如下格式,现在可以开始训练了。
2.模型训练
到了模型训练阶段就比较容易了,本文使用的操作系统是ubuntu系统,使用的软件是Pycharm + Anaconda,其中Pycharm 作为IDE来调试代码,Anaconda用来管理python模拟环境。
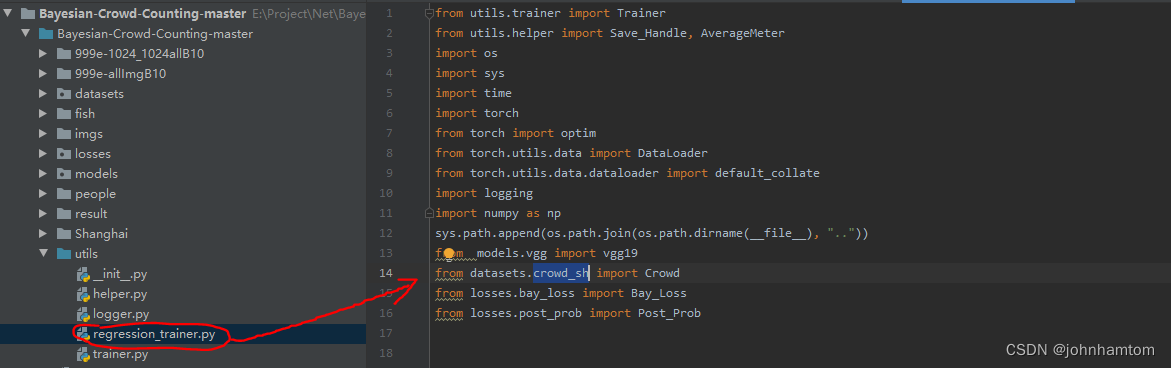
本文使用的是python3.8的环境,其它所需的库环境都安装了最新的,将上述环境准备好后,首先将utils目录下的regression_trainer.py的datasets.crowd改为datasets.crowd_sh,如下图所示。(crowd_sh.py是由官方提供的用于处理shanghaiTech数据集的代码)
然后打开train.py文件里设置数据文件夹目录、训练权重保存文件目录、参数等,其中–data-dir后面设置的是数据文件路径,引到数据根目录下即可,参考上述图片中显示的路径的话是写到part_A_final(训练PartA部分)或者part_B_final(训练PartB部分);–save-dir存放权重保存路径;后面的还有learning rate、weight decay等参数的设置,在train.py里给的比较清楚了。
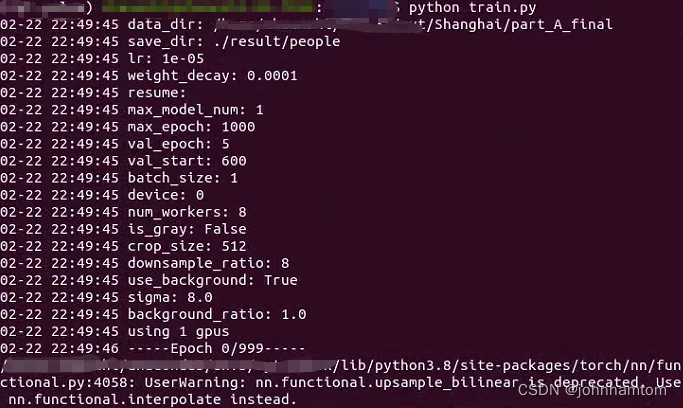
最后打开anaconda prompt 定位到项目文件夹目录位置,开启模拟环境并输入python train.py即可开始训练,如下图所示,里面的参数我使用的是官方给的默认参数,batch_size为1,训练轮次为1000轮,在600轮的时候开启验证,每五轮验证一次。
训练了约4小时左右就训练好了,ShanghaiTech数据集的PartA部分的场景比较复杂,验证时的MAE能到12+,而PartB部分的场景就没那么复杂,验证时的MAE在2左右,如下图所示。
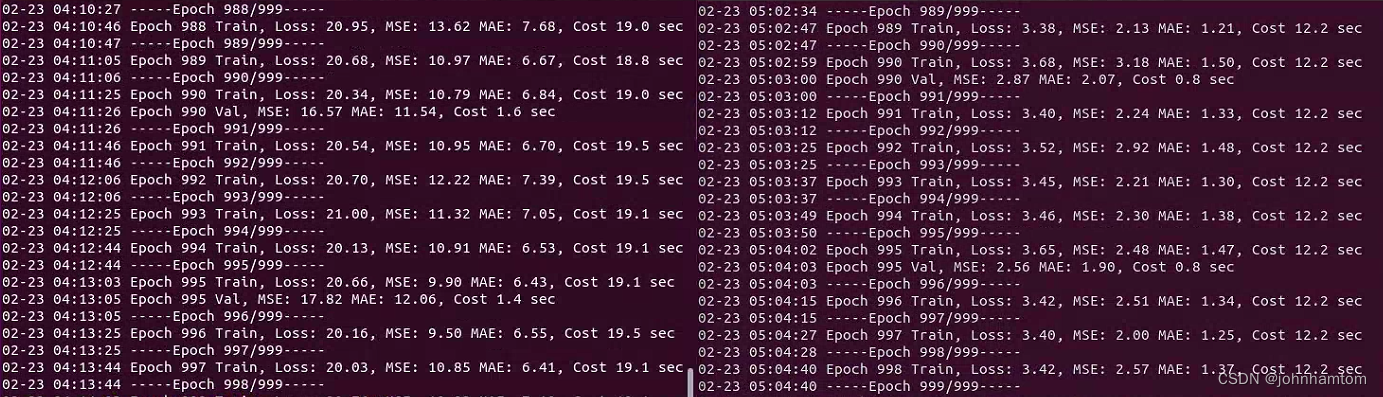
Part_A Part_B
3.模型测试
模型测试阶段要做的事就用训练好的模型去预测测试集中的人群图片中的人群数量,本文将会使用Accuracy、MAE(Mean Average Error)、RMSE(Root Mean Square Error)指标去评估模型的预测结果。
Accuracy、MAE、RMSE的公式分别如下:
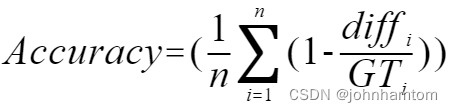
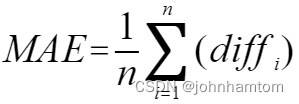
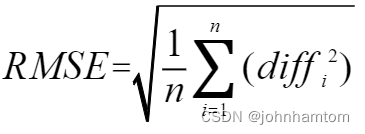
其中假设共有n张图片, diffi 指的是第 i 张图片的预测人数与真实人数的差的绝对值,GTi 指的是第i张图片的真实值。
接着调整下test.py文件的代码以达到需要,首先还是将它的datasets.crowd改为datasets.crowd_sh,跟模型训练阶段做的事一样,然后调整好数据集路径和权重读取路径,这个在代码中的位置也很清楚,接着新建两个dataframe在循环中存储每一张图片和所有图片的名字、GT值、预测值、准确率等信息,完整代码如下所示,详细信息看代码。
import torch
import os
import numpy as np
from datasets.crowd_sh import Crowd
from models.vgg import vgg19
import argparse
import pandas as pd
args = None
def parse_args():
parser = argparse.ArgumentParser(description='Test ')
parser.add_argument('--data-dir', default='./Shanghai/part_B_final',
help='training data directory')
parser.add_argument('--save-dir', default='./result/people/Shanghai_B',
help='model directory')
parser.add_argument('--device', default='0', help='assign device')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
os.environ['CUDA_VISIBLE_DEVICES'] = args.device.strip() # set vis gpu
# 我这边把val修改为了test
datasets = Crowd(os.path.join(args.data_dir, 'test'), 512, 8, is_gray=False, method='val')
dataloader = torch.utils.data.DataLoader(datasets, 1, shuffle=False,
num_workers=8, pin_memory=False)
model = vgg19()
device = torch.device('cuda')
model.to(device)
model.load_state_dict(torch.load(os.path.join(args.save_dir, 'best_model.pth'), device))
epoch_minus = []
# 两个dataframe在循环中存储每一张图片和所有图片的名字、GT值、预测值、准确率等信息
df = pd.DataFrame(columns=['Name', 'GT', 'Pre','Accuracy'])
dfNum = pd.DataFrame(columns=['Accuracy','AverageMAE','RMSE'])
sum = 0 # 记录图片数量
totalAcc = 0 # 记录总准确率
for inputs, count, name in dataloader:
inputs = inputs.to(device)
assert inputs.size(0) == 1, 'the batch size should equal to 1'
with torch.set_grad_enabled(False):
outputs = model(inputs)
temp_minu = count[0].item() - torch.sum(outputs).item()
# 计算每一张图片的准确信息,并记录总准确率
acc = 1-abs((torch.sum(outputs).item()) - count[0].item())/count[0].item()
totalAcc = acc + totalAcc
new = [name, count[0].item() , torch.sum(outputs).item() , acc]
df.loc[sum] = new
print(name, temp_minu, count[0].item(), torch.sum(outputs).item())
epoch_minus.append(temp_minu)
sum = sum + 1
mse = np.sqrt(np.mean(np.square(epoch_minus)))
mae = np.mean(np.abs(epoch_minus))
newdfNum = [totalAcc/sum,mae,mse]
dfNum.loc[0] = newdfNum
epoch_minus = np.array(epoch_minus)
log_str = 'Final Test: mae {}, mse {}'.format(mae, mse)
print(log_str)
filename = "shanghaiTech_Part_B"
df.to_csv(r"./people/"+filename+"-Images.csv", index=False) # CSV文件路径
dfNum.to_csv(r"./people/"+filename+"-Total.csv", index=False)
接下来打开anaconda prompt 定位到项目文件夹目录位置,开启模拟环境并输入python test.py即可开始测试,如下图所示,
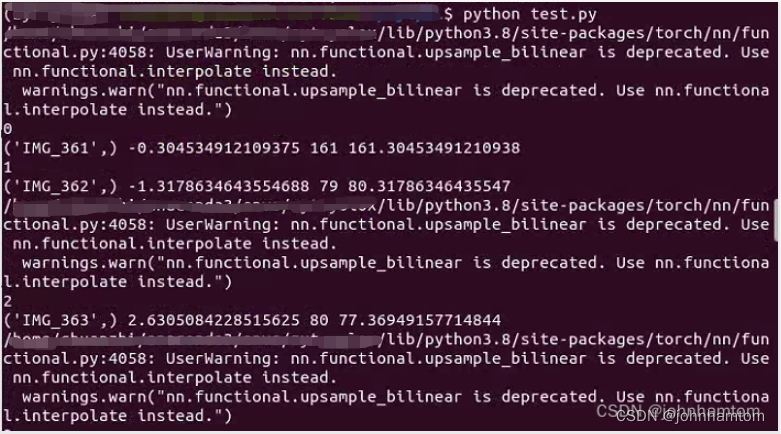
最终测试结果如下,单张图片的测试信息就不一 一介绍了,是输出为下图样式的CSV文件。
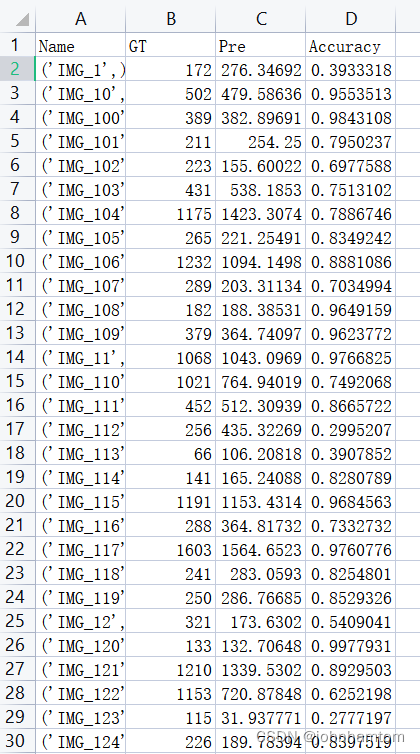
总的测试结果如下表所示,相比较论文中的结果稍差一点点,但也正常,毕竟batch_size参数我仅设置为了1,没有去进一步调整。
| part | Accuracy | AverageMAE | RMSE |
|---|---|---|---|
| Part_A | 0.806 | 74.54 | 123.0396 |
| Part_B | 0.928 | 10.15 | 19.7185 |
4.小结
本文利用了ShanghaiTech数据集训练了BL模型,并且使用训练好的权重对Part_A和Part_B部分的测试集进行了测试。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









