






一、引言
在此次实战中,本文将会使用纽约市出租车出行数据据集[1],对应的天气数据集[2]和油价数据集[3]来构建回归模型,以预测纽约市出租车出行的总时间。
除了上下车经纬度、载客人数等数据,出行时的天气情况和当时的油价情况也可能对出行时长造成影响, 故本文选择了kaggle网站上的纽约市出租车和豪华轿车委员会发布的2016年纽约市出租车出行时长数据集(即GPS数据,后称出租车数据集)、2016年纽约市天气数据集(后称天气数据集)和2016年纽约市油价数据集(后称油价数据集)来对出租车出行时长进行分析。
2016年纽约市出租车出行时长数据集有1458644行,包括10个变量、2016年纽约市天气数据集有10449 行,包括30个变量、2016年纽约市油价数据集有52行,包括2个变量,如表1与2所示。
表1
| 属性 | 含义 |
|---|---|
| vendor_id | 指示与行程记录关联的提供者的代码 |
| Pickup_datetime | 使用仪表的日期和时间 |
| Pickup_longitude | 使用仪表的经度 |
| dropoff_datetime | 仪表脱离的日期和时间 |
| passenger_count | 车辆中的乘客数量 |
| Pickup_latitude | 使用仪表的纬度 |
| dropoff_longitude | 仪表脱离的经度 |
| dropoff_latitude | 仪表脱离的纬度 |
| store_and_fwd_flag | 行程记录之前是否保存在车辆内存中,- Y = 是;N=否 |
| trip_duration | 旅行的持续时间(以秒为单位) |
表 2
| 属性 | 含义 |
|---|---|
| wspdi | 风速(英里/小时) |
| windchilli | 华氏度的风寒 |
| hail | 1-有冰雹 0-无冰雹 |
| wgustm | 以公里/小时为单位的阵风 |
| heatindexm | 热指数摄氏度 |
| thunder | 1-有打雷 0-无打雷 |
| wgusti | 以英里/小时为单位的阵风 |
| heatindexi | 华氏温度指数 |
| tornado | 1-有龙卷风 0-无龙卷风 |
| hum | 湿度 % |
| pressurei | 压力inHg |
| rain | 1-有雨 0-无雨 |
| datetime | 日期和时间(EST) |
| wdird | 以度为单位的风向 |
| precipm | 以毫米为单位的降水量 |
| tempm | 摄氏温度 |
| wdire | 风向描述 |
| precipi | 以英寸为单位的降水量 |
| tempi | 华氏温度 |
| vim | 以公里为单位的能见度 |
| conds | 风、雪文字描述1 |
| dewptm | 摄氏度露点 |
| visi | 以英里为单位的能见度 |
| icon | 风、雪文字描述2 |
| dewpti | 华氏露点 |
| pressurem | 以毫巴为单位的压力 |
| fog | 有雾0-无雾 |
| Date | 记录时的日期 |
| Gdollars | 记录日期对应油价 |
二、数据合并
首先将出行数据集,天气数据集和油价数据集进行合并。
导入所需的库。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
from scipy import stats
import zipfile
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
读入数据
train = pd.read_csv(r"E:\project\taxiDuarion\train.zip",
compression="zip", index_col="id")#出租车数据训练集
test = pd.read_csv(r"E:\project\taxiDuarion\test.zip",
compression="zip", index_col="id")#出租车数据测试集
Weather = pd.read_csv(r"E:\project\taxiDuarion\天气数据\Weather.csv") #天气数据
gas = pd.read_csv(r"E:\project\taxiDuarion\油价数据\gasoline.csv") #油价数据
查看数据集情况,其中左上为出租车出行数据训练集,右上为出租车出行数据测试集,左下为天气数据集,右下为油价数据集,从中可以看出天气数据集可能存在大量异常值情况。

首先构造一下时间的特征,以方便后续合并。
# 将上下车的时间转化为标准的datetime时间格式
train.pickup_datetime = pd.to_datetime(train.pickup_datetime)
train.dropoff_datetime = pd.to_datetime(train.dropoff_datetime)
test.pickup_datetime = pd.to_datetime(test.pickup_datetime)
Weather.pickup_datetime = pd.to_datetime(Weather.pickup_datetime)
gas.Date = pd.to_datetime(gas.Date)
#增加出租车时间信息特征
train['weekday'] = 0 #星期几
train['hour'] = 0 #开始出行小时
train['minute'] = 0 #开始出行分钟
train['month'] = 0 #开始出行时的月份
train['day'] = 0 #当月第几天
train['week'] = 0 #当月第几周
train['sesson'] = 0 #季节
test['weekday'] = 0 #星期几
test['hour'] = 0 #开始出行小时
test['minute'] = 0 #开始出行分钟
test['month'] = 0 #开始出行时的月份
test['day'] = 0 #当月第几天
test['week'] = 0 #当月第几周
test['sesson'] = 0 #季节
#增加天气数据的时间信息特征
Weather['hour'] = 0 #开始出行小时
Weather['month'] = 0 #开始出行时的月份
Weather['day'] = 0 #当月第几天
#增加油价的时间信息特征
gas['month'] = 0 #月份
gas['day'] = 0 #天
gas['week'] = 0 #当月第几周
#增加出租车时间信息特征
train['weekday'] = train.pickup_datetime.dt.weekday #星期几
train['weekday'] = train['weekday']+1
train['hour'] = train.pickup_datetime.dt.hour #开始出行小时
train['minute'] = train.pickup_datetime.dt.minute #开始出行分钟
train['month'] = train.pickup_datetime.dt.month #开始出行时的月份
train['day'] = train.pickup_datetime.dt.day #当月第几天
train['week'] = ((train.pickup_datetime.dt.day)/7)+1 #当月第几个星期(1代表当月第一周)
train['sesson'] = (train.pickup_datetime.dt.month/4)+1 #季节
test['weekday'] = test.pickup_datetime.dt.weekday #星期几
test['weekday'] = test['weekday']+1
test['hour'] = test.pickup_datetime.dt.hour #开始出行小时
test['minute'] = test.pickup_datetime.dt.minute #开始出行分钟
test['month'] = test.pickup_datetime.dt.month #开始出行时的月份
test['day'] = test.pickup_datetime.dt.day #当月第几天
test['week'] = ((test.pickup_datetime.dt.day)/7)+1 #当月第几个星期(1代表当月第一周)
test['sesson'] = (test.pickup_datetime.dt.month/4)+1 #季节
#增加天气时间信息特征
Weather['hour'] = Weather.pickup_datetime.dt.hour #开始出行小时
Weather['month'] = Weather.pickup_datetime.dt.month #开始出行时的月份
Weather['day'] = Weather.pickup_datetime.dt.day #当月第几天
#增加油价的时间信息特征
gas['month'] = gas.Date.dt.month #月份
gas['day'] = gas.Date.dt.day #天
gas['week'] = ((gas.Date.dt.day)/7)+1 #当月第几周
#下取整,得到星期数和季节数
train[["sesson"]] = train[["sesson"]].astype(int)
train[["week"]] = train[["week"]].astype(int)
test[["sesson"]] = test[["sesson"]].astype(int)
test[["week"]] = test[["week"]].astype(int)
gas[["week"]] = gas[["week"]].astype(int)
接下来做一些去重操作。
Weather=Weather.drop_duplicates(['hour','month','day']) #去除重复行
gas=gas.drop_duplicates(['month','week']) #去除重复行
然后根据小时 月份 天 链接天气数据。
df_train = pd.merge(train,Weather,how='left',on=['hour','month','day'])
df_test = pd.merge(test,Weather,how='left',on=['hour','month','day'])
接着根据月份和星期 链接油价数据。
out_train = pd.merge(df_train,gas,how='left',on=['month','week'])
out_test = pd.merge(df_test,gas,how='left',on=['month','week'])
删除掉一些没有用的特征,并导出合并后的数据集。
#删除时间变量等信息
del out_train['pickup_datetime_y']
del out_train['Date']
del out_train['day_y']
del out_test['pickup_datetime_y']
del out_test['Date']
del out_test['day_y']
out_train.to_csv(r"D:\A原始数据文件训练集(合并后).txt", sep='\t', index=False)
out_test.to_csv(r"D:\A原始数据文件测试集集(合并后).txt", sep='\t', index=False)
合并结果数据量为1458644,特征数有47,如下。
| 属性 | 含义 |
|---|---|
| vendor_id | 指示与行程记录关联的提供者的代码 |
| Pickup_datetime | 使用仪表的日期和时间 |
| Pickup_longitude | 使用仪表的经度 |
| dropoff_datetime | 仪表脱离的日期和时间 |
| passenger_count | 车辆中的乘客数量 |
| Pickup_latitude | 使用仪表的纬度 |
| dropoff_longitude | 仪表脱离的经度 |
| dropoff_latitude | 仪表脱离的纬度 |
| store_and_fwd_flag | 行程记录之前是否保存在车辆内存中, - Y = 是;N=否 |
| datetime | 日期和时间(EST) |
| wdird | 以度为单位的风向 |
| precipm | 以毫米为单位的降水量 |
| tempm | 摄氏温度 |
| wdire | 风向描述 |
| precipi | 以英寸为单位的降水量 |
| tempi | 华氏温度 |
| vim | 以公里为单位的能见度 |
| conds | 风、雪文字描述 |
| dewptm | 摄氏度露点 |
| visi | 以英里为单位的能见度 |
| icon | 风、雪文字描述2 |
| dewpti | 华氏露点 |
| pressurem | 以毫巴为单位的压力 |
| fog | 有雾0-无雾 |
| hum | 湿度 % |
| pressurei | 压力inHg |
| rain | 1-有雨 0-无雨 |
| wspdm | 以公里/小时为单位的风速 |
| windchillm | 摄氏的风寒 |
| snow | 1-有雪 0-无雪 |
| wspdi | 风速(英里/小时) |
| windchilli | 华氏度的风寒 |
| hail | 1-有冰雹0-无冰雹 |
| wgustm | 以公里/小时为单位的阵风 |
| heatindexm | 热指数摄氏度 |
| thunder | 1-有打雷0-无打雷 |
| wgusti | 以英里/小时为单位的阵风 |
| Date | 记录时的日期 |
| weekday | 记录日期对应周几 |
| Gdollars | 记录日期对应油价 |
| hour | 记录日期对应几点 |
| minute | 记录日期对应几分 |
| day_x | 记录日期对应当月第几天 |
| week | 记录日期对应当月第几周 |
| session | 记录日期对应季节 |
| heatindexi | 华氏温度指数 |
| tornado | 1-有龙卷风0-无龙卷风 |
| trip_duration | 旅行的持续时间(以秒为单位) |
三、特征工程
导入所需库及数据集。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
%matplotlib inline
pd.set_option('display.float_format', lambda x:'%.5f'%x) # 小数点后面保留5位小数,不以科学计数法显示
pd.set_option('display.max_columns', None)#显示全部列
train = pd.read_csv(r"D:\A原始数据文件训练集(合并后).txt", sep='\t', encoding='utf-8')
test = pd.read_csv(r"D:\A原始数据文件测试集集(合并后).txt", sep='\t', encoding='utf-8')
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
构建上下车位置对应街区特征。
#计算出上下车的区域。
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
discrete_variable = [] #记录离散型变量
train_pickup_borough = []
for j,k in zip(train.pickup_longitude,train.pickup_latitude):
if ((j>=-74.040269) and (j<=-73.865036)) and ((k>=40.574031) and (k<=40.736728)):
train_pickup_borough.append('Brooklyn')
elif ((j>=-74.245856) and (j<=-73.057562)) and ((k>=40.502863) and (k<=40.647234)):
train_pickup_borough.append('Staten_island')
elif ((j>=-74.011645) and (j<=-73.913772)) and ((k>=40.703384) and (k<=40.876058)):
train_pickup_borough.append('Manhattan')
elif ((j>=-73.931573) and (j<=-73.781473)) and ((k>=40.797766) and (k<=40.912460)):
train_pickup_borough.append('Bronx')
else: train_pickup_borough.append('Queens')
Borough_ptrain = pd.DataFrame(train_pickup_borough,columns=['pickup_borough'])
train = pd.concat([train,Borough_ptrain], axis=1)
test_pickup_borough = []
for g,h in zip(test.pickup_longitude,test.pickup_latitude):
if ((g>=-74.040269) and (g<=-73.865036)) and ((h>=40.574031) and (h<=40.736728)):
test_pickup_borough.append('Brooklyn')
elif ((g>=-74.245856) and (g<=-73.057562)) and ((h>=40.502863) and (h<=40.647234)):
test_pickup_borough.append('Staten_island')
elif ((g>=-74.011645) and (g<=-73.913772)) and ((h>=40.703384) and (h<=40.876058)):
test_pickup_borough.append('Manhattan')
elif ((g>=-73.931573) and (g<=-73.781473)) and ((h>=40.797766) and (h<=40.912460)):
test_pickup_borough.append('Bronx')
else: test_pickup_borough.append('Queens')
Borough_ptest = pd.DataFrame(test_pickup_borough,columns=['pickup_borough'])
test = pd.concat([test,Borough_ptest],axis=1)
train_dropoff_borough = []
for d,f in zip(train.dropoff_longitude,train.dropoff_latitude):
if ((d>=-74.040269) and (d<=-73.865036)) and ((f>=40.574031) and (f<=40.736728)):
train_dropoff_borough.append('Brooklyn')
elif ((d>=-74.245856) and (d<=-73.057562)) and ((f>=40.502863) and (f<=40.647234)):
train_dropoff_borough.append('Staten_island')
elif ((d>=-74.011645) and (d<=-73.913772)) and ((f>=40.703384) and (f<=40.876058)):
train_dropoff_borough.append('Manhattan')
elif ((d>=-73.931573) and (d<=-73.781473)) and ((f>=40.797766) and (f<=40.912460)):
train_dropoff_borough.append('Bronx')
else: train_dropoff_borough.append('Queens')
Borough_dtrain = pd.DataFrame(train_dropoff_borough,columns=['dropoff_borough'])
train = pd.concat([train,Borough_dtrain],axis=1)
test_dropoff_borough = []
for a,s in zip(test.dropoff_longitude,test.dropoff_latitude):
if ((a>=-74.040269) and (a<=-73.865036)) and ((s>=40.574031) and (s<=40.736728)):
test_dropoff_borough.append('Brooklyn')
elif ((a>=-74.245856) and (a<=-73.057562)) and ((s>=40.502863) and (s<=40.647234)):
test_dropoff_borough.append('Staten_island')
elif ((a>=-74.011645) and (a<=-73.913772)) and ((s>=40.703384) and (s<=40.876058)):
test_dropoff_borough.append('Manhattan')
elif ((a>=-73.931573) and (a<=-73.781473)) and ((s>=40.797766) and (s<=40.912460)):
test_dropoff_borough.append('Bronx')
else: test_dropoff_borough.append('Queens')
Borough_dtest = pd.DataFrame(test_dropoff_borough,columns=['dropoff_borough'])
test = pd.concat([test,Borough_dtest],axis=1)
discrete_variable.append('dropoff_borough')
discrete_variable.append('pickup_borough')
对上下车位置特征进行编码。
train['pickup_borough'] = train['pickup_borough'].astype('str')
train['dropoff_borough'] = train['dropoff_borough'].astype('str')
test['pickup_borough'] = test['pickup_borough'].astype('str')
test['dropoff_borough'] = test['dropoff_borough'].astype('str')
encoder= LabelEncoder().fit(train['pickup_borough'])
train['pickup_borough'] = encoder.transform(train['pickup_borough'])
encoder= LabelEncoder().fit(train['dropoff_borough'])
train['dropoff_borough'] = encoder.transform(train['dropoff_borough'])
encoder= LabelEncoder().fit(test['pickup_borough'])
test['pickup_borough'] = encoder.transform(test['pickup_borough'])
encoder= LabelEncoder().fit(test['dropoff_borough'])
test['dropoff_borough'] = encoder.transform(test['dropoff_borough'])
对出行时长特征进行对数化处理。
train['trip_duration'] = np.log(train['trip_duration'].values)
plt.hist(train['trip_duration'].values, bins=100)
plt.xlabel('log(trip_duration)')
plt.ylabel('number of records')
plt.show()
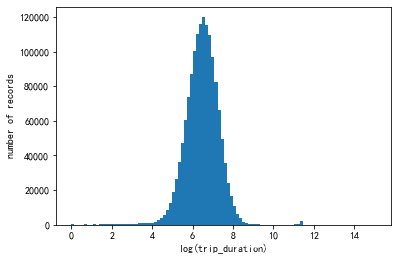
查看出行时长变量的分布范围并对其异常值进行处理。
#查看预测变量的分布情况
plt.scatter(range(train.shape[0]),train['trip_duration'])
#框定范围
train = train[train.trip_duration<train.trip_duration.quantile(0.98)]
train = train[train.trip_duration>train.trip_duration.quantile(0.01)]
plt.scatter(range(train.shape[0]),train['trip_duration'])
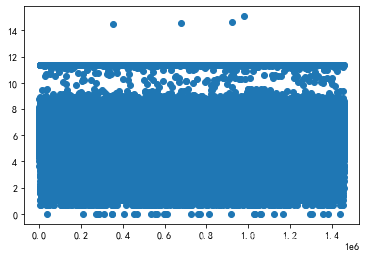

对离散型特征进行处理。
#记录离散型变量
discrete_variable.append('vendor_id')
discrete_variable.append('store_and_fwd_flag')
discrete_variable.append('wdire')
discrete_variable.append('conds')
discrete_variable.append('icon')
#转化为字符型
train['store_and_fwd_flag'] = train['store_and_fwd_flag'].astype('str')
train['wdire'] = train['wdire'].astype('str')
train['conds'] = train['conds'].astype('str')
train['icon'] = train['icon'].astype('str')
test['store_and_fwd_flag'] = test['store_and_fwd_flag'].astype('str')
test['wdire'] = test['wdire'].astype('str')
test['conds'] = test['conds'].astype('str')
test['icon'] = test['icon'].astype('str')
#将离散字符串变量转化为离散数值型变量
encoder= LabelEncoder().fit(train['wdire'])
train['wdire'] = encoder.transform(train['wdire'])
encoder= LabelEncoder().fit(train['store_and_fwd_flag'])
train['store_and_fwd_flag'] = encoder.transform(train['store_and_fwd_flag'])
encoder= LabelEncoder().fit(train['icon'])
train['icon'] = encoder.transform(train['icon'])
encoder= LabelEncoder().fit(train['conds'])
train['conds'] = encoder.transform(train['conds'])
#将离散字符串变量转化为离散数值型变量
encoder= LabelEncoder().fit(test['wdire'])
test['wdire'] = encoder.transform(test['wdire'])
encoder= LabelEncoder().fit(test['store_and_fwd_flag'])
test['store_and_fwd_flag'] = encoder.transform(test['store_and_fwd_flag'])
encoder= LabelEncoder().fit(test['icon'])
test['icon'] = encoder.transform(test['icon'])
encoder= LabelEncoder().fit(test['conds'])
test['conds'] = encoder.transform(test['conds'])
删除掉多余的特征,并处理经纬度中的异常值。
#处理异常值--经纬度
train = train[(train.pickup_longitude > -100.0 )]
train = train[(train.pickup_latitude <50.0 )]
train = train[(train.dropoff_longitude < -65.0 )]
train = train[(train.dropoff_latitude > 36.0 )]
根据上下车的经纬度信息构造距离特征。
#欧式距离
train['Euclide_D']=np.sqrt((train['pickup_longitude']-train['dropoff_longitude'])**2+(train['pickup_latitude']-train['dropoff_latitude'])**2)
#曼哈顿距离
train['Manhattan_D']=np.abs(train['pickup_latitude']-train['dropoff_latitude']) + np.abs(train['pickup_longitude']-train['dropoff_longitude'])
#半正矢公式距离
def haversine_(pick_lat, pick_lng, drop_lat, drop_lng):
pick_lat, pick_lng, drop_lat, drop_lng = map(np.radians, (pick_lat, pick_lng, drop_lat, drop_lng))
AVG_EARTH_RADIUS = 6371 #km
lat = pick_lat - drop_lat
lng = pick_lng - drop_lng
distance = np.sin(lat/2)**2 + np.cos(pick_lat)*np.cos(drop_lat)*np.sin(lng/2)**2
h = 2 * AVG_EARTH_RADIUS * np.arcsin(np.sqrt(distance))
return h
train['Haversine_D'] = haversine_(train['pickup_latitude'].values,
train['pickup_longitude'].values,
train['dropoff_latitude'].values,
train['dropoff_longitude'].values)
#欧式距离
test['Euclide_D']=np.sqrt((test['pickup_longitude']-test['dropoff_longitude'])**2+(test['pickup_latitude']-test['dropoff_latitude'])**2)
#曼哈顿距离
test['Manhattan_D']=np.abs(test['pickup_latitude']-test['dropoff_latitude']) + np.abs(test['pickup_longitude']-test['dropoff_longitude'])
#半正矢公式距离
def haversine_(pick_lat, pick_lng, drop_lat, drop_lng):
pick_lat, pick_lng, drop_lat, drop_lng = map(np.radians, (pick_lat, pick_lng, drop_lat, drop_lng))
AVG_EARTH_RADIUS = 6371 #km
lat = pick_lat - drop_lat
lng = pick_lng - drop_lng
distance = np.sin(lat/2)**2 + np.cos(pick_lat)*np.cos(drop_lat)*np.sin(lng/2)**2
h = 2 * AVG_EARTH_RADIUS * np.arcsin(np.sqrt(distance))
return h
test['Haversine_D'] = haversine_(test['pickup_latitude'].values,
test['pickup_longitude'].values,
test['dropoff_latitude'].values,
test['dropoff_longitude'].values)
再处理异常值。
#删除缺失值过多的特征:wgustm wgusti windchillm windchilli heatindexm heatindexi precipm precipi
deleteCol = ['wgustm','wgusti','windchillm','windchilli','heatindexm','heatindexi','precipm','precipi']
#删除操作,删除8个缺失值过多的特征
train = train.drop(deleteCol, axis=1)
#删除操作,删除8个缺失值过多的特征
test = test.drop(deleteCol, axis=1)
#一些特征仅有少量缺失值,这里采取用中位数填补的措施
for column in list(train.columns):
mean_val = train[column].mean()
train[column].fillna(mean_val, inplace=True)
#一些特征仅有少量缺失值,这里采取用中位数填补的措施
for column in list(test.columns):
mean_val = test[column].mean()
test[column].fillna(mean_val, inplace=True)
通过箱图查看特征分布情况。
# 画箱式图
column = train.columns.tolist()[:len(train.columns)] # 列表头 将列转化为列表,每一列转化为一个列表保存
fig = plt.figure(figsize=(30, 60)) # 指定绘图对象宽度和高度
for i in range(len(train.columns)):
plt.subplot(10, 5, i + 1) # 13行3列子图
sns.boxplot(train[column[i]], orient="v", width=0.6) # 箱式图
plt.ylabel(column[i], fontsize=8)
# l,m,h = np.percentile(train[column[i]], (25, 50, 75), interpolation='midpoint')
# print("特征:"+str(column[i]))
# print("特征:"+str(column[i])+"的上四分位为:"+ str(h)+",下四分位数为:"+str(l))
# print("特征:"+str(column[i])+"的上界为:"+ str((h+(h-l)*1.5))+",下界为:"+str((l-(h-l)*1.5)))
# print("-------------------------------")
plt.show()
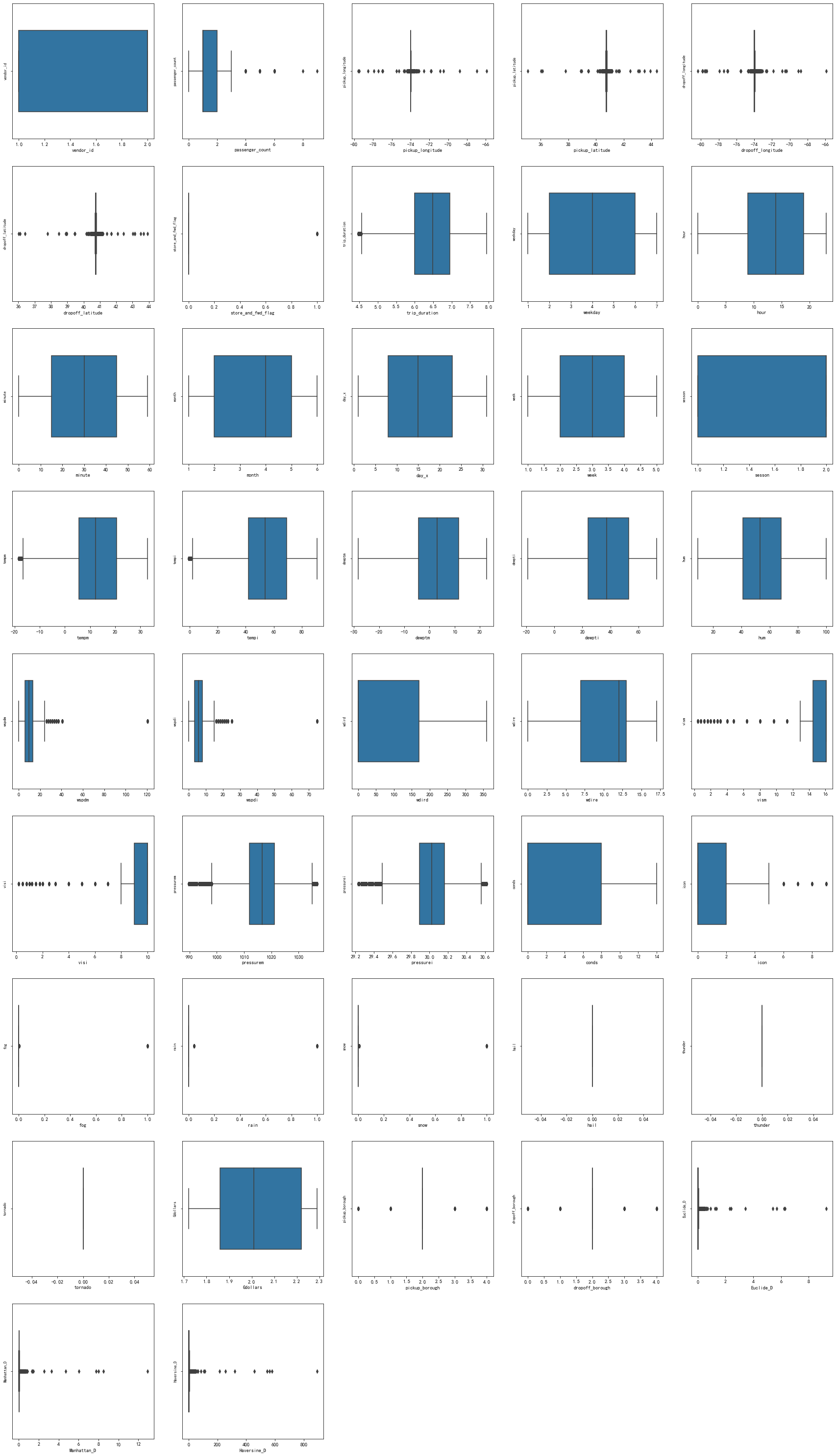
删除全0的特征。
#删除全0的特征
deleteCol = ['fog','rain','snow','hail','thunder','tornado']
train = train.drop(deleteCol, axis=1)
test = test.drop(deleteCol, axis=1)
对类别型变量进行哑变量处理。
#哑变量处理
weekday=pd.get_dummies(train['weekday'],sparse=True)
vendor_id=pd.get_dummies(train['vendor_id'],sparse=True)
month=pd.get_dummies(train['month'],sparse=True)
week=pd.get_dummies(train['week'],sparse=True)
conds=pd.get_dummies(train['conds'],sparse=True)
wdire=pd.get_dummies(train['wdire'],sparse=True)
icon=pd.get_dummies(train['icon'],sparse=True)
store_and_fwd_flag=pd.get_dummies(train['store_and_fwd_flag'],sparse=True)
pickup_borough = pd.get_dummies(train['pickup_borough'],sparse=True)
dropoff_borough = pd.get_dummies(train['dropoff_borough'],sparse=True)
Tweekday=pd.get_dummies(test['weekday'],sparse=True)
Tvendor_id=pd.get_dummies(test['vendor_id'],sparse=True)
Tmonth=pd.get_dummies(test['month'],sparse=True)
Tweek=pd.get_dummies(test['week'],sparse=True)
Tconds=pd.get_dummies(test['conds'],sparse=True)
Twdire=pd.get_dummies(test['wdire'],sparse=True)
Ticon=pd.get_dummies(test['icon'],sparse=True)
Tstore_and_fwd_flag=pd.get_dummies(test['store_and_fwd_flag'],sparse=True)
Tpickup_borough = pd.get_dummies(test['pickup_borough'],sparse=True)
Tdropoff_borough = pd.get_dummies(test['dropoff_borough'],sparse=True)
Onehot = ['周一','周二','周三','周四','周五','周六','周日','一月','二月','三月','四月','五月','六月','第一周','第二周','第三周','第四周','第五周','vendor_id_1','vendor_id_2','N','Y','conds1 ','conds2','conds3','conds4','conds5','conds6','conds7','conds8','conds9','conds10','conds11','conds12','conds13','conds14','conds15','icon1 ','icon2','icon3','icon4','icon5','icon6','icon7','icon8','icon9','icon10','wdire1 ','wdire2','wdire3','wdire4','wdire5','wdire6','wdire7','wdire8','wdire9','wdire10','wdire11','wdire12','wdire13','wdire14','wdire15','wdire16','wdire17','wdire18','pickup_borough1 ','pickup_borough2','pickup_borough3','pickup_borough4','pickup_borough5','dropoff_borough1 ','dropoff_borough2','dropoff_borough3','dropoff_borough4','dropoff_borough5']
weekday.columns = ['周一','周二','周三','周四','周五','周六','周日']
month.columns = ['一月','二月','三月','四月','五月','六月']
week.columns = ['第一周','第二周','第三周','第四周','第五周']
vendor_id.columns = ['vendor_id_1','vendor_id_2']
store_and_fwd_flag.columns = ['N','Y']
conds.columns = ['conds1 ','conds2','conds3','conds4','conds5','conds6','conds7','conds8','conds9','conds10','conds11','conds12','conds13','conds14','conds15']
icon.columns = ['icon1 ','icon2','icon3','icon4','icon5','icon6','icon7','icon8','icon9','icon10']
wdire.columns = ['wdire1 ','wdire2','wdire3','wdire4','wdire5','wdire6','wdire7','wdire8','wdire9','wdire10','wdire11','wdire12','wdire13','wdire14','wdire15','wdire16','wdire17','wdire18']
pickup_borough.columns = ['pickup_borough1 ','pickup_borough2','pickup_borough3','pickup_borough4','pickup_borough5']
dropoff_borough.columns = ['dropoff_borough1 ','dropoff_borough2','dropoff_borough3','dropoff_borough4','dropoff_borough5']
Tweekday.columns = ['周一','周二','周三','周四','周五','周六','周日']
Tmonth.columns = ['一月','二月','三月','四月','五月','六月']
Tweek.columns = ['第一周','第二周','第三周','第四周','第五周']
Tvendor_id.columns = ['vendor_id_1','vendor_id_2']
Tstore_and_fwd_flag.columns = ['N','Y']
Tconds.columns = ['conds1 ','conds2','conds3','conds4','conds5','conds6','conds7','conds8','conds9','conds10','conds11','conds12','conds13','conds14','conds15']
Ticon.columns = ['icon1 ','icon2','icon3','icon4','icon5','icon6','icon7','icon8','icon9','icon10']
Twdire.columns = ['wdire1 ','wdire2','wdire3','wdire4','wdire5','wdire6','wdire7','wdire8','wdire9','wdire10','wdire11','wdire12','wdire13','wdire14','wdire15','wdire16','wdire17','wdire18']
Tpickup_borough.columns = ['pickup_borough1 ','pickup_borough2','pickup_borough3','pickup_borough4','pickup_borough5']
Tdropoff_borough.columns = ['dropoff_borough1 ','dropoff_borough2','dropoff_borough3','dropoff_borough4','dropoff_borough5']
#存储离散型变量
discrete_variable.append('weekday')
discrete_variable.append('month')
discrete_variable.append('week')
del train['weekday']
del train['month']
del train['week']
del train['vendor_id']
del train['store_and_fwd_flag']
del train['conds']
del train['icon']
del train['wdire']
del train['pickup_borough']
del train['dropoff_borough']
del test['weekday']
del test['month']
del test['week']
del test['vendor_id']
del test['store_and_fwd_flag']
del test['conds']
del test['icon']
del test['wdire']
del test['pickup_borough']
del test['dropoff_borough']
train_afterOnehot = pd.concat([train,weekday,month,week,vendor_id,store_and_fwd_flag,conds,icon,wdire,pickup_borough,dropoff_borough],axis=1)
test_afterOnehot = pd.concat([test,Tweekday,Tmonth,Tweek,Tvendor_id,Tstore_and_fwd_flag,Tconds,Ticon,Twdire,Tpickup_borough,Tdropoff_borough],axis=1)
train_afterOnehot.info()
对连续型变量先进行Box-Cox变换,使其满足正态,然后进行最大最小值归一化处理。
#对特征进行Box-Cox变换,使其满足正态
after_BoxCox_train = train_data_scaler
after_BoxCox_test = test_data_scaler
from scipy import stats
for col in MinMaxNum:
after_BoxCox_train[col],a = stats.boxcox(after_BoxCox_train[col] + 1)
for col in MinMaxNum:
after_BoxCox_test[col],b = stats.boxcox(after_BoxCox_test[col] + 1)
# 最大最小值归一化
# 区间缩放,返回值为缩放到[0, 1]区间的数据
train_data_scaler = after_BoxCox_train
test_data_scaler = after_BoxCox_test
NotOneHot = [i for i in train_data_scaler.columns if i not in Onehot]
MinMaxNum = NotOneHot
MinMaxNum.remove('trip_duration')
for col in MinMaxNum:
train_data_scaler[col] = (train_data_scaler[col] - train_data_scaler[col].min())/(train_data_scaler[col].max() - train_data_scaler[col].min())
for col in MinMaxNum:
test_data_scaler[col] = (test_data_scaler[col] - test_data_scaler[col].min())/(test_data_scaler[col].max() - test_data_scaler[col].min())
合并训练集测试,并进行PCA降维。
#PCA降维
from sklearn.decomposition import PCA
np.set_printoptions(suppress=True)
column = []
pca_train = data_all.drop(['trip_duration','oringin'],axis=1)
for i in range(100):
print("降到"+str(i+1)+"维")
pca = PCA(n_components=(i+1))#降到i+1维
pca.fit(pca_train) #训练
newX=pca.fit_transform(pca_train) #降维后的数据
# PCA(copy=True, n_components=2, whiten=False)
print(pca.explained_variance_ratio_) #输出贡献率
print("累积贡献率"+ str(sum(pca.explained_variance_ratio_)))
print("--------------------------------------")
print("降到"+str(30)+"维")
pca = PCA(n_components=(30))#降到i+1维
pca.fit(pca_train) #训练
newX=pca.fit_transform(pca_train) #降维后的数据
# PCA(copy=True, n_components=2, whiten=False)
print(pca.explained_variance_ratio_) #输出贡献率
print("累积贡献率"+ str(sum(pca.explained_variance_ratio_)))
print("--------------------------------------")
观察发现,降到30维已经有0.907的累计贡献率。
保存降维后的数据。
new = pd.DataFrame(newX)
new.columns = ['pca1','pca2','pca3','pca4','pca5','pca6','pca7','pca8','pca9','pca10','pca11','pca12','pca13','pca14','pca15','pca16','pca17','pca18','pca19','pca20','pca21','pca22','pca23','pca24','pca25','pca26','pca27','pca28','pca29','pca30']
new = pd.concat([new,data_all['trip_duration'],data_all['oringin']],axis=1)
#根据列值拆分数据集,并将预测变量合并回去
index1 = new['oringin'] == "train"
index2 = new['oringin'] == "test"
train_all = new[index1]
test_all = new[index2]
train_all = train_all.drop('oringin',axis=1)
test_all = test_all.drop('oringin',axis=1)
train_all.to_csv(r"D:\A特征工程处理后训练集.txt", sep='\t', index=False)
test_all.to_csv(r"D:\A特征工程处理后测试集.txt", sep='\t', index=False)
至此特征工程阶段结束。
四、模型训练
导入库及所需数据集。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression #线性回归
from sklearn.neighbors import KNeighborsRegressor #K近邻回归
from sklearn.tree import DecisionTreeRegressor #决策树回归
from sklearn.ensemble import RandomForestRegressor #随机森林回归
from sklearn.svm import SVR #支持向量回归
import lightgbm as lgb #lightGbm模型
from sklearn.model_selection import train_test_split # 切分数据
from sklearn.metrics import mean_squared_error #评价指标
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
from scipy import stats
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split,GridSearchCV,cross_val_score
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from math import sqrt
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
import warnings
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.linear_model import Ridge #岭回归
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
%matplotlib inline
pd.set_option('display.float_format', lambda x:'%.5f'%x) # 小数点后面保留5位小数,不以科学计数法显示
pd.set_option('display.max_columns', None)#显示全部列
from matplotlib import pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
train = pd.read_csv(r"D:\A特征工程处理后训练集.txt", sep='\t', encoding='utf-8')
test = pd.read_csv(r"D:\A特征工程处理后测试集.txt", sep='\t', encoding='utf-8')
test = test.drop('trip_duration',axis=1)
数据集划分,其中test_data用于测试,check_data用于调参。
X = ['pca1','pca2','pca3','pca4','pca5','pca6','pca7','pca8','pca9','pca10','pca11','pca12','pca13','pca14','pca15','pca16','pca17','pca18','pca19','pca20','pca21','pca22','pca23','pca24','pca25','pca26','pca27','pca28','pca29','pca30']
Y = ['trip_duration']
X_train = train[X]
Y_train = train[Y]
#划分测试集与训练集
train_data,test_data,train_target,test_target=train_test_split(X_train,Y_train,test_size=0.2,random_state=0)
#在测试集的基础上再划分验证集与测试集
check_data,test_data,check_target,test_target=train_test_split(test_data,test_target,test_size=0.5,random_state=0)
使用’岭回归’,‘lasso回归’,‘随机森林回归’,‘XGBOOST回归’,‘极端随机树回归’,'LightGBM回归’进行训练及测试。
#岭回归
clf = linear_model.RidgeCV(fit_intercept=False)
# 训练模型
clf.fit(train_data, train_target)
print ('alpha的数值 : ', clf.alpha_)
print( '参数的数值:', clf.coef_)
alpha = clf.alpha_
Brige = Ridge(alpha = alpha , solver="cholesky")
Brige.fit(train_data, train_target)
pre_Brige = Brige.predict(test_data)
BrigesRMSE = sqrt(mean_squared_error(test_target, pre_Brige))
BrigesMAE = mean_absolute_error(test_target, pre_Brige)
BrigesR2 = r2_score(test_target, pre_Brige)
print('BrigesRMSE:' +str(BrigesRMSE))
print('BrigesMAE:' +str(BrigesMAE))
print('BrigesR2:' +str(BrigesR2))
from sklearn.linear_model import Lasso, LassoCV
# 构造不同的Lambda值
Lambdas = np.logspace(-5, 2, 200)
# LASSO回归模型的交叉验证
lasso_cv = LassoCV(alphas=Lambdas, normalize=True, cv=10, max_iter=10000)
lasso_cv.fit(train_data, train_target)
# 输出最佳的lambda值
lasso_best_alpha = lasso_cv.alpha_ # 0.06294988990221888
Lasso = Lasso(alpha = lasso_best_alpha )
Lasso.fit(train_data, train_target)
pre_Lasso = Lasso.predict(test_data)
LassoRMSE = sqrt(mean_squared_error(test_target, pre_Lasso))
LassoMAE = mean_absolute_error(test_target, pre_Lasso)
LassoR2 = r2_score(test_target, pre_Lasso)
print('LassoRMSE:' +str(LassoRMSE))
print('LassoMAE:' +str(LassoMAE))
print('LassoR2:' +str(LassoR2))
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(random_state = 66)
rf.fit(train_data,train_target)
pre_rf = rf.predict(test_data)
rfRMSE = sqrt(mean_squared_error(test_target, pre_rf))
rfMAE = mean_absolute_error(test_target, pre_rf)
rfR2 = r2_score(test_target, pre_rf)
print('rfRMSE:' +str(rfRMSE))
print('rfMAE:' +str(rfMAE))
print('rfR2:' +str(rfR2))
from xgboost import XGBRegressor
XGBR = XGBRegressor()
XGBR.fit(train_data,train_target)
pre_XGBR = XGBR.predict(test_data)
XGBRRMSE = sqrt(mean_squared_error(test_target, pre_XGBR))
XGBRMAE = mean_absolute_error(test_target, pre_XGBR)
XGBRR2 = r2_score(test_target, pre_XGBR)
print('XGBRRMSE:' +str(XGBRRMSE))
print('XGBRMAE:' +str(XGBRMAE))
print('XGBRR2:' +str(XGBRR2))
ETR = ExtraTreesRegressor()
ETR.fit(train_data,train_target)
pre_ETR = ETR.predict(test_data)
ETRRRMSE = sqrt(mean_squared_error(test_target, pre_ETR))
ETRRMAE = mean_absolute_error(test_target, pre_ETR)
ETRRR2 = r2_score(test_target, pre_ETR)
print('ETRRRMSE:' +str(ETRRRMSE))
print('ETRRMAE:' +str(ETRRMAE))
print('ETRRR2:' +str(ETRRR2))
lgb = lgb.LGBMRegressor()
lgb.fit(train_data,train_target)
pre_lgb = lgb.predict(test_data)
lgbRRMSE = sqrt(mean_squared_error(test_target, pre_lgb))
lgbRMAE = mean_absolute_error(test_target, pre_lgb)
lgbR2 = r2_score(test_target, pre_lgb)
print('lgbRRMSE:' +str(lgbRRMSE))
print('lgbRMAE:' +str(lgbRMAE))
print('lgbR2:' +str(lgbR2))
查看测试结果。
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
x_data = ['岭回归','lasso回归','随机森林回归','XGBOOST回归','极端随机树回归','LightGBM回归']
y_data = [BrigesRMSE,LassoRMSE,rfRMSE,XGBRRMSE,ETRRRMSE,lgbRRMSE]
plt.barh(y=x_data, width =y_data)
plt.show()
x_data = ['岭回归','lasso回归','随机森林回归','XGBOOST回归','极端随机树回归','LightGBM回归']
y_data = [BrigesMAE,LassoMAE,rfMAE,XGBRMAE,ETRRMAE,lgbRMAE]
plt.barh(y=x_data, width =y_data)
plt.show()
x_data = ['岭回归','lasso回归','随机森林回归','XGBOOST回归','极端随机树回归','LightGBM回归']
y_data = [BrigesR2,LassoR2,rfR2,XGBRR2,ETRRR2,lgbR2]
plt.barh(y=x_data, width =y_data)
plt.show()
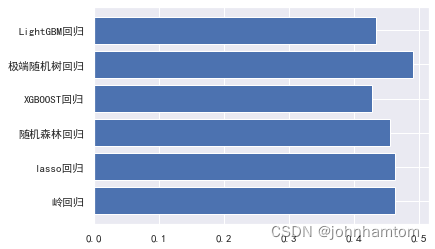
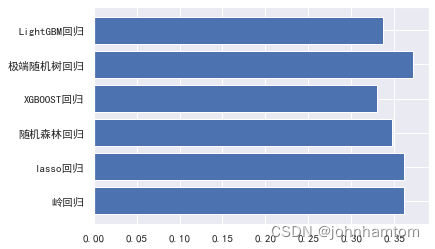
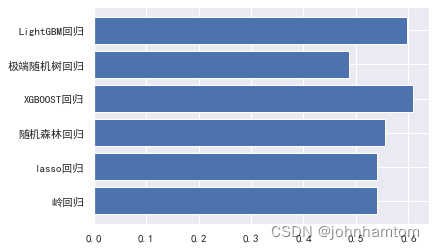
综合发现,xgboost模型的效果最优,然后使用学习曲线查看训练情况,结果表明没有存在拟合问题。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
# 图一
title = r"Learning Curves (XGBOOST回归)"
#cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = XGBRegressor() #建模
plot_learning_curve(estimator, title, X_train, Y_train, ylim=(0.10, 1.00), cv=3, n_jobs=1)
plt.show()
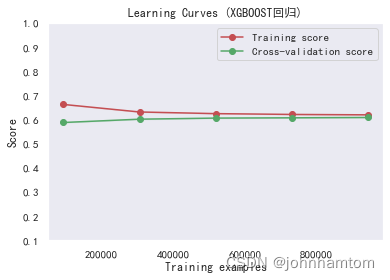
使用网格调参对XGBoost模型进行调参。
共两轮。
from sklearn.model_selection import train_test_split,GridSearchCV,cross_val_score
from xgboost import XGBRegressor
import time
start = time.time()
param_grid = {'n_estimators':[800,900,1000],
'max_depth':[5,6,7],
'learning_rate':[0.02,0.05,0.1],
}
XGBR = XGBRegressor()
GS = GridSearchCV(XGBR,param_grid,cv=5)
GS.fit(check_data,check_target)
end = time.time()
print("循环运行时间:%.2f秒"%(end-start))
print(GS.best_params_)
print(GS.best_score_)
#循环运行时间:30169.42秒
#{'learning_rate': 0.05, 'max_depth': 7, 'n_estimators': 1000}
#0.6016442032512698
from sklearn.model_selection import train_test_split,GridSearchCV,cross_val_score
from xgboost import XGBRegressor
import time
start = time.time()
param_grid = {'n_estimators':[1000,1100,1200],
'max_depth':[7,8,9],
'learning_rate':[0.05],
}
XGBR = XGBRegressor()
GS = GridSearchCV(XGBR,param_grid,cv=5)
GS.fit(check_data,check_target)
end = time.time()
print("循环运行时间:%.2f秒"%(end-start))
print(GS.best_params_)
print(GS.best_score_)
#循环运行时间:18565.73秒
#{'learning_rate': 0.05, 'max_depth': 7, 'n_estimators': 1000}
#0.6016442032512698
使用调好的参数训练模型并进行比对。
from xgboost import XGBRegressor
AXGBR = XGBRegressor(n_estimators=1000,max_depth=7,learning_rate=0.05)
AXGBR.fit(train_data,train_target)
Apre_XGBR = AXGBR.predict(test_data)
AXGBRRMSE = sqrt(mean_squared_error(test_target, Apre_XGBR))
AXGBRMAE = mean_absolute_error(test_target, Apre_XGBR)
AXGBRR2 = r2_score(test_target, Apre_XGBR)
print('XGBRRMSE:' +str(AXGBRRMSE))
print('XGBRMAE:' +str(AXGBRMAE))
print('XGBRR2:' +str(AXGBRR2))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
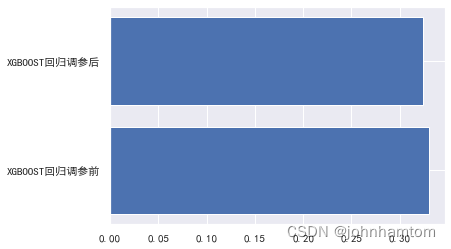
x_data = ['XGBOOST回归调参前','XGBOOST回归调参后']
y_data = [XGBRRMSE,AXGBRRMSE]
plt.barh(y=x_data, width =y_data)
plt.show()
x_data = ['XGBOOST回归调参前','XGBOOST回归调参后']
y_data = [XGBRMAE,AXGBRMAE]
plt.barh(y=x_data, width =y_data)
plt.show()
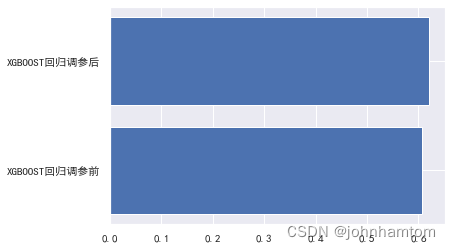
x_data = ['XGBOOST回归调参前','XGBOOST回归调参后']
y_data = [XGBRR2,AXGBRR2]
plt.barh(y=x_data, width =y_data)
plt.show()
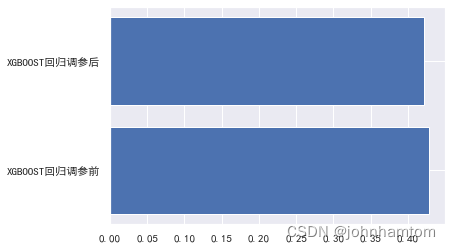
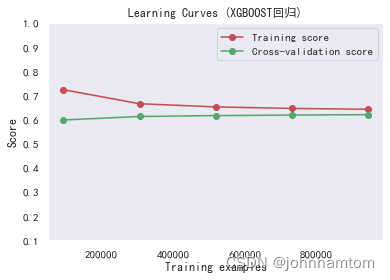
最后再使用学习曲线查看是否存在拟合问题。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
from xgboost import XGBRegressor
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
# 图一
title = r"Learning Curves (XGBOOST回归)"
#cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = XGBRegressor(n_estimators=1000,max_depth=7,learning_rate=0.05) #建模
plot_learning_curve(estimator, title, X_train, Y_train, ylim=(0.10, 1.00), cv=3, n_jobs=1)
plt.show()
五、参考
[1] kaggle.New York City Taxi Trip Duration.https://www.kaggle.com/competitions/nyc-taxi-trip-duration/data.(2022,4,6)
[2] MEINERTSEN.New York City Taxi Trip - Hourly Weather Data.https://www.kaggle.com/datasets/meinertsen/new-york-city-taxi-trip-hourly-weather-data.(2022,4,6)
[3] HAOZHENGNI.Gasoline Retail Price in New York City.https://www.kaggle.com/datasets/haozheng0512/gasoline-price-nyc.(2022,4,6)

















 2505
2505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









