






笔记来着的
参考文章
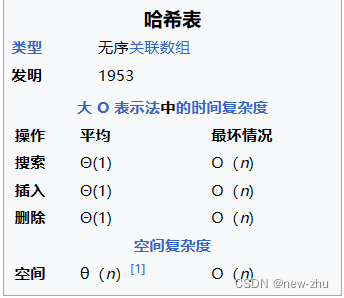
哈希表 - 维基百科,自由的百科全书 (wikipedia.org) 基础信息
数据结构之—哈希表_哈希表数据结构_林纾y的博客-CSDN博客 应用,java
C++【哈希表的模拟实现】-腾讯云开发者社区-腾讯云 (tencent.com)
哈希表的原理
在计算中,哈希表(也称为哈希映射)是一种实现关联数组的数据结构,也称为字典,它是一种将键映射到值的抽象数据类型。哈希表也叫散列表,其实就是相对于排序而言的,没有按顺序排放
简单来说,就是可以通过一个键值,来将需要进行查询的数据映射到表中的一个位置
哈希表本质上是一个数组,在数组的基础上还添加了其他的东西,比如说数组+链表,数组+二叉树
哈希表打个比方,就是一个电话本,要找一个人的电话,就先找到人名的首字母,然后找到对应的地方。这样子就比一页一页翻找更加方便了,那么人名就是关键字,取首字母就是函数法则。
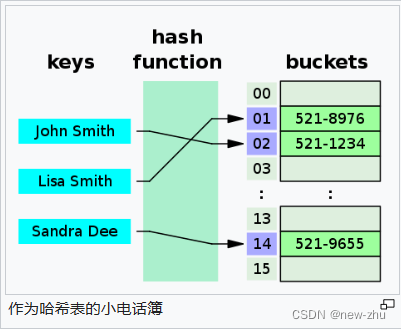
像在这里,就比较直观表现出来,为什么哈希表像一个电话本。 就是将keys,用hash fuction来进行变换,得到存放位置。
Hash函数(hash function)
这个函数就是来进行判断keys应该放在哪里,将其映射为一个整数。首先哈希值需要均匀分布,那么也就是尽量尽可能不要让最后的哈希值都一样,不然就会产生哈希冲突(就是一个位置怎么存放两个或者多个数据,到底最后需要的是哪一个呢)。
比如通过哈希函数之后,显示的结果是:4,5,2,4,4,5,8。这样子的结果显示是不太好的,也就是哈希冲突严重。
HASH函数必须具备两个基本特征:单向性 和 碰撞约束。单向性是指其的操作方向的不可逆性,在HASH函数中是指 只能从输入推导出输出,而不能从输出计算出输入;碰撞约束是指 不能找到一个输入使其输出结果等于一个已知的输出结果 或者 不能同时找到两个不同的输入使其输出结果完全一致。一个函数只用同时严格的具备了这样的特性,我们才能认可这样的一个HASH。
哈希表怎么存数据
Entry就是一个键值和值的对应,也可以叫做键值对。哈希表就是根据key值来通过哈希函数计算得到一个值,这个值就是用来确定这个Entry要存放在哈希表中的位置的,那么这个值就是一个小标值,用来确定放在数组的哪一个位置上。
ok,那么这样子就会产生之前描述到的问题,如果两个不同的值,通过哈希函数产生了一样的值,会放在同一个位置怎么办。
哈希冲突
多个值都想放在同一个位置,就产生了冲突。为了解决这样子的问题,有很多方法,这里有两种。
第一种是拉链法,就是用链表的形式来存储多个值。在单独的链接中,该过程涉及为每个搜索数组索引构建一个具有键值对的链表。冲突的项目通过单个链表链接在一起,可以遍历该链表以使用唯一的搜索键访问该项目

可能会出现链表过长的问题,而且存在额外的复杂性,如果链表的节点分散在内存中,单独链接实现的链表可能就不具有缓存意识,插入和搜索期间的列表遍历可能会让效率变低。
第二种是开放寻址法,如果位置不够怎么办,那就顺延下去呗
这是另一种冲突解决技术,其中每个条目记录都存储在存储桶数组本身中,并通过探测执行哈希解析。当必须插入新条目时,将检查存储桶,从散列到槽开始,并按某个探测顺序进行,直到找到未占用的槽。搜索条目时,将按相同的顺序扫描存储桶,直到找到目标记录或找到未使用的阵列槽,这表示搜索不成功

这样子方便,但同时也会存在问题,那就是如图所示的,Ted本来应该在153的,但是因为开放寻址的方法,被挤到了154去,但我们指向的还是153
除了上面的两种,还有合并哈希,布谷鸟散列,跳房子散列,罗宾汉哈希等等
动态调整/哈希表扩容
当哈希表被占用的位置变多,链表过长,那么哈希冲突出现的概率会变高,也就需要扩容了。
HashMap中,当前容量达到75%就会进行扩容,但不是简单进行数组扩大,会创建一个新的数组,将原来数组的所有的Entry重新进行位置分配


哈希查找
首先,通过已有信息以及哈希函数来得到数据存放的位置拿到数据之后看key能不能对应的上,如果可以就ok,如果不可以,那么就下一个位置或者链表中的next来查看。
哈希简单代码
gpt生成的,参考
#include<iostream>
using namespace std;
const int MAX_SIZE = 10; // 哈希表的大小
const int HASH_CONST = 7; // 哈希函数的常数
// 定义哈希节点结构体
struct Node
{
int key;
int value;
Node* next; // 链表指针,用于处理哈希冲突
};
// 哈希表类定义
class HashTable
{
private:
Node* hashTable[MAX_SIZE]; // 哈希表数组,每个元素是一个指向链表头的指针
public:
// 构造函数,初始化哈希表
HashTable()
{
for (int i = 0; i < MAX_SIZE; ++i)
{
hashTable[i] = nullptr;
}
}
// 哈希函数,用于计算键的哈希值
int hashFunc(int key)
{
return key % HASH_CONST;
}
// 插入键值对
void insert(int key, int value)
{
int index = hashFunc(key); // 计算哈希值
Node* node = new Node{ key, value, nullptr }; // 创建新的节点
if (hashTable[index] == nullptr)
{
// 如果该位置为空,直接插入新节点
hashTable[index] = node;
}
else
{
// 如果该位置已经有节点,将新节点插入到链表末尾
Node* temp = hashTable[index];
while (temp->next != nullptr)
{
temp = temp->next;
}
temp->next = node;
}
}
// 查找键对应的值
int search(int key)
{
int index = hashFunc(key); // 计算哈希值
Node* temp = hashTable[index]; // 指向链表头
while (temp != nullptr)
{
// 在链表中查找键对应的值
if (temp->key == key)
{
return temp->value;
}
temp = temp->next;
}
return -1; // 如果未找到,返回-1
}
};
int main()
{
HashTable table; // 创建哈希表对象
table.insert(10, 100); // 插入键值对
table.insert(20, 200);
table.insert(30, 300);
table.insert(40, 400);
int res = table.search(30); // 查找键对应的值
if (res == -1)
{
cout << "Key not found" << endl;
}
else
{
cout << "Value for key 30: " << res << endl;
}
return 0;
}















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









