







 本文详细描述了如何通过逆向工程分析头条接口中的加密参数_signature,涉及jsvmp(JavaScript虚拟化)、环境检测技巧和断点调试方法,最终揭示了如何补全环境并解决cookie问题。然而,接口并未实际使用_signature进行验证。
本文详细描述了如何通过逆向工程分析头条接口中的加密参数_signature,涉及jsvmp(JavaScript虚拟化)、环境检测技巧和断点调试方法,最终揭示了如何补全环境并解决cookie问题。然而,接口并未实际使用_signature进行验证。
声明:本文仅作学习交流,请遵守法律法规,不要恶意爬取网站。
网址:'aHR0cHM6Ly93d3cudG91dGlhby5jb20v'
接口:'aHR0cHM6Ly93d3cudG91dGlhby5jb20vaG90LWV2ZW50L2hvdC1ib2FyZC8='
本文提到的接口是头条的今日热榜接口,观察接口发现其中有一个加密参数 _signature,以下分析此参数的生成过程

分析过程
搜索参数名,js没有做混淆之类的措施,很幸运的找到参数
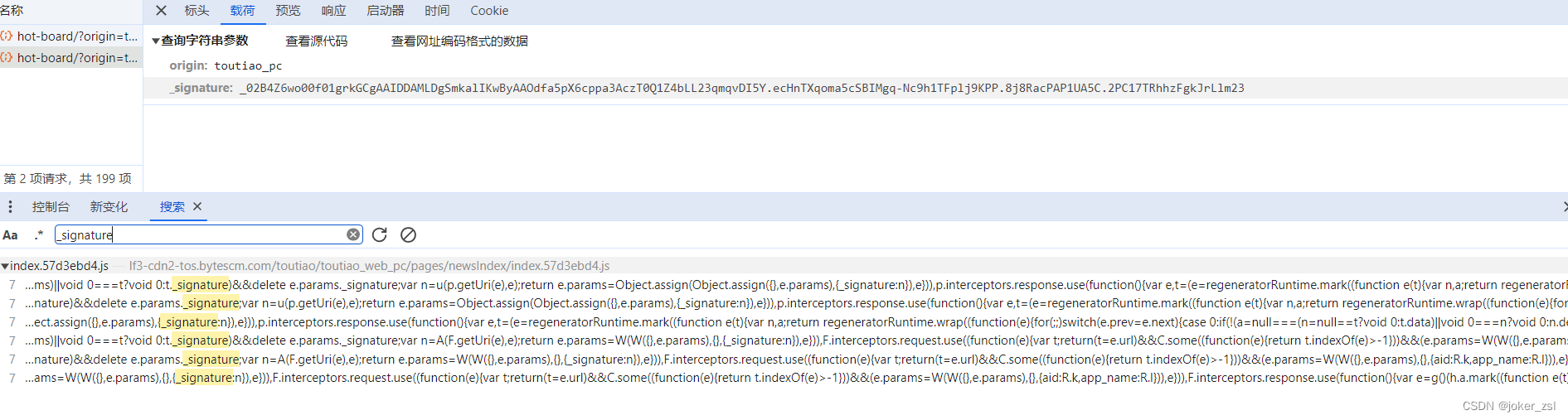
挨个点击进去打上断点,刷新页面触发断点,就找到了正确的断点位置
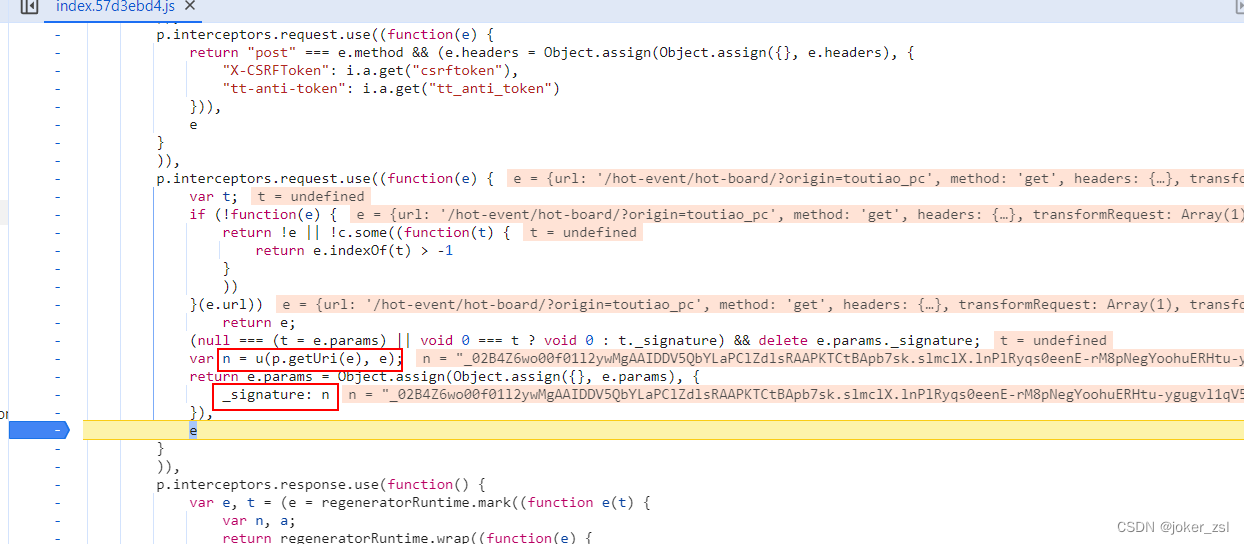
很明显, _signature: n 而 n = u(p.getUri(e), e),u方法的返回值即是所需要的
点u进入方法内部,可以看到返回值是一个三元表达式
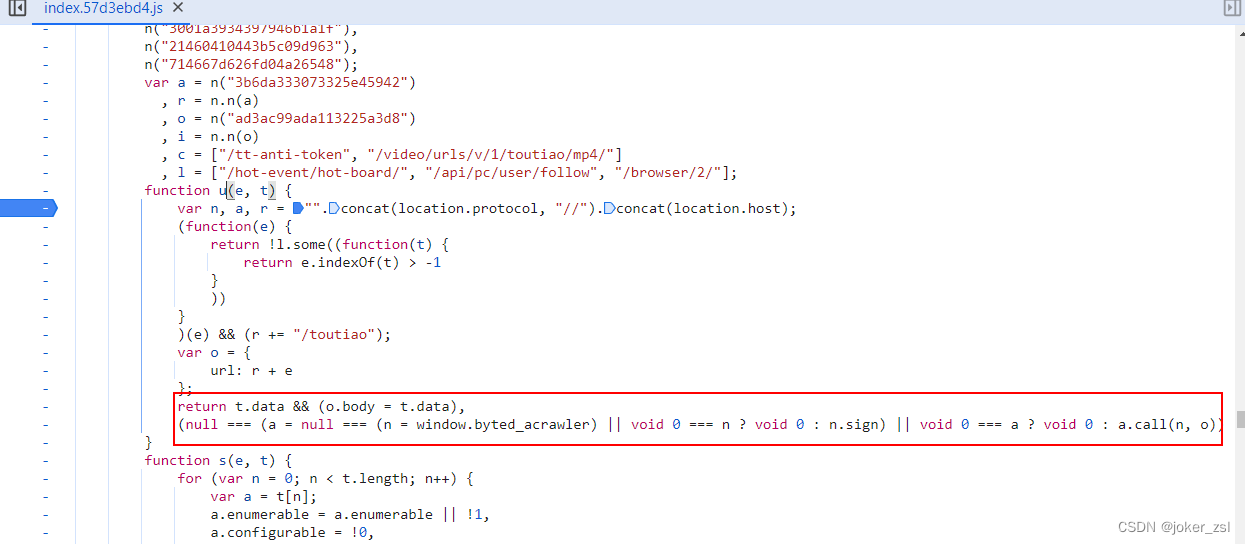
精简后的结果是: window.byted_acrawler.sign(o),其入参o是固定值
控制台输出下,看到值正是想要的
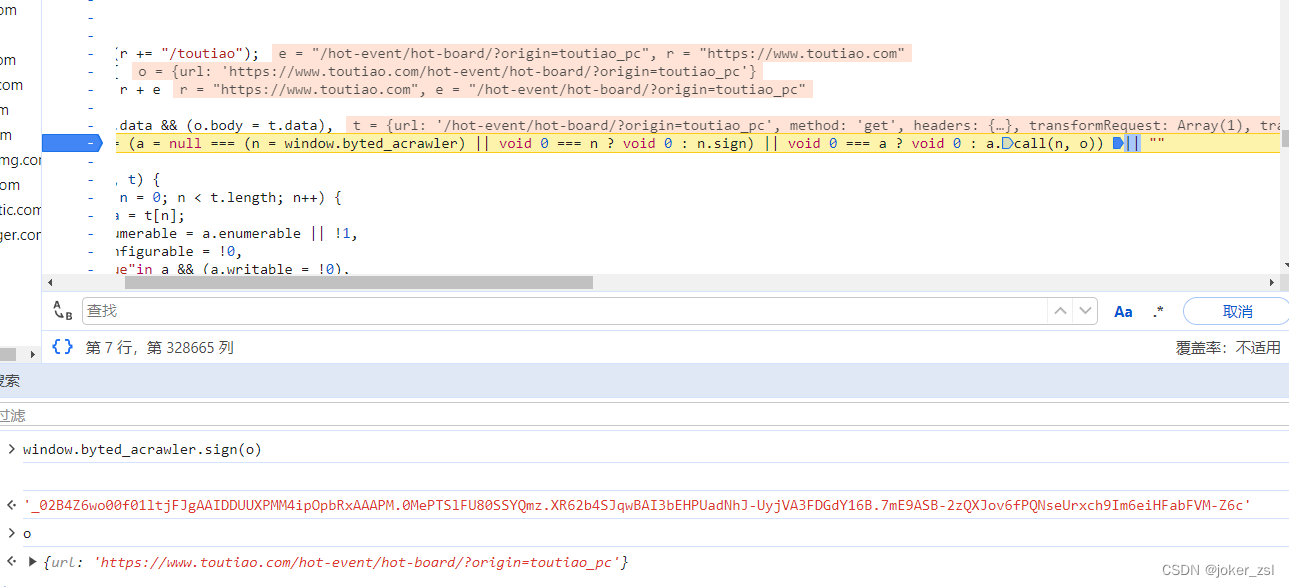
然后我们进入到window.byted_acrawler.sign方法中,跳转到了acrawler.js文件
好了,到此开始今天的第一个知识点:
jsvmp
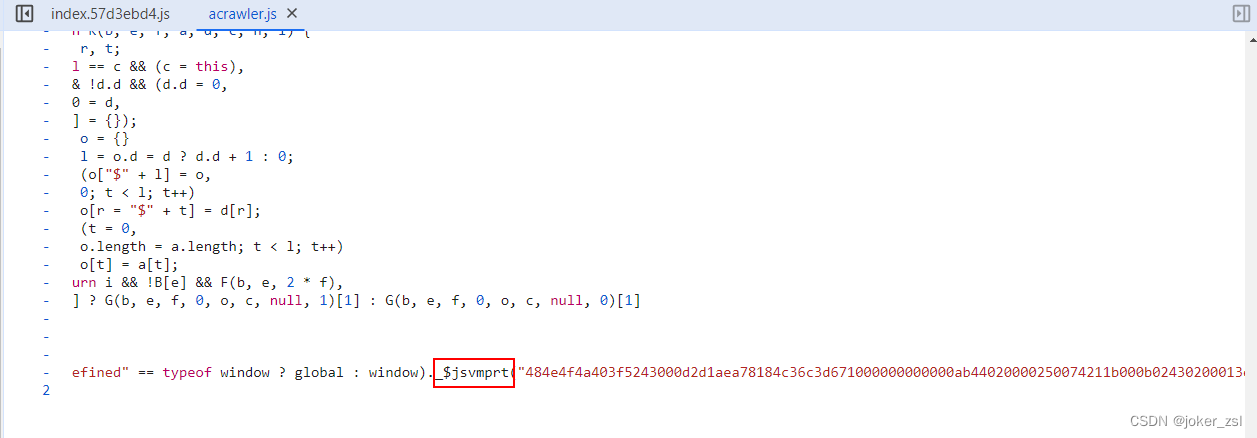
jsvmp即js代码的虚拟化,是一种保护js代码的方式,其主要过程简单可以理解为加密和解密。先把原始的js代码按照一定的规则进行加密,然后使用自己实现的代码解释器进行还原。acrawler.js中第一行即使代码解释器,第二行中的"484e4f4a403f..."即加密后的字节码。
逆向使用了jsvmp的代码,无需关注解释器是如何实现的,直接全部扣下来。
逆向过程
扣下全部js后先运行一下,看看有无问题。
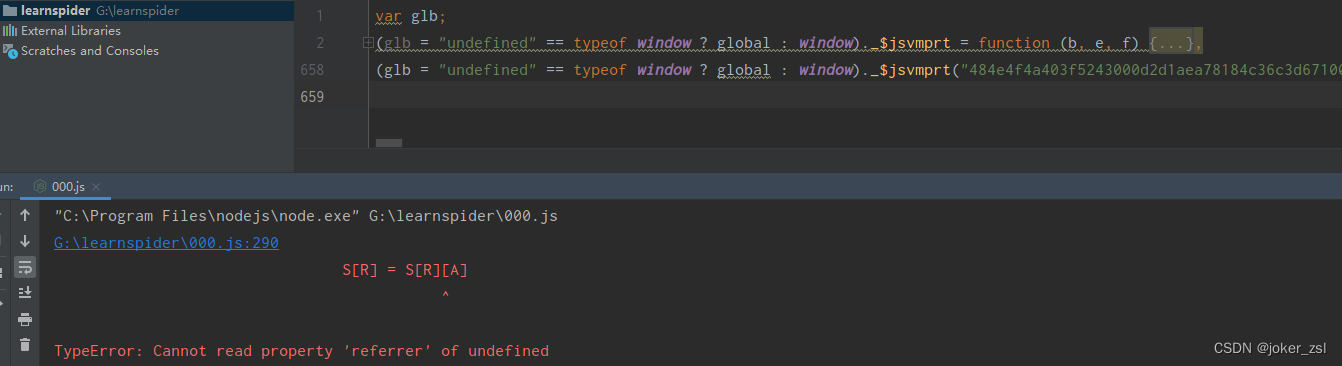
很明显,环境有问题,接下来开始‘愉快的’补环境环节。补环境的过程中会介绍两种断点调试的方法。
条件断点
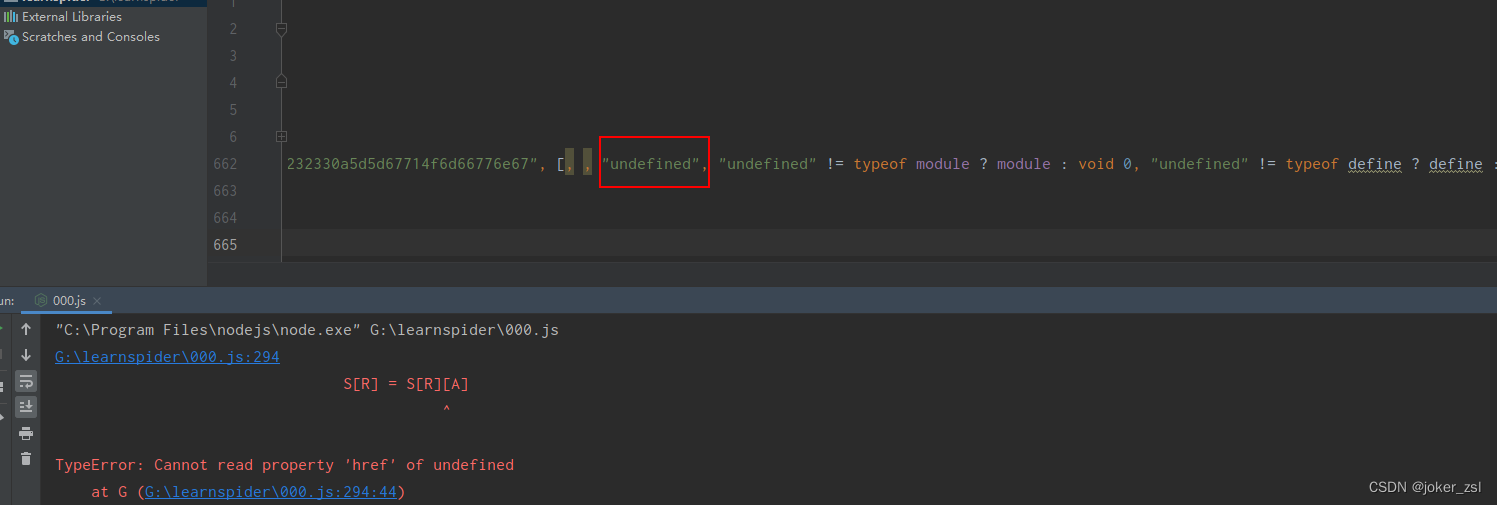
从报错可以看出是S[R]找A属性时报错,此时需要的A是referrer
我们可以在代码相应位置打上条件断点,让下次触发时直接停到A=referrer的地方
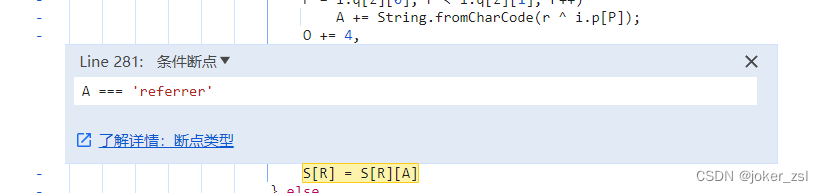
刷新页面,到断点时,可以看到此时的S[R]是document,referrer的值是''
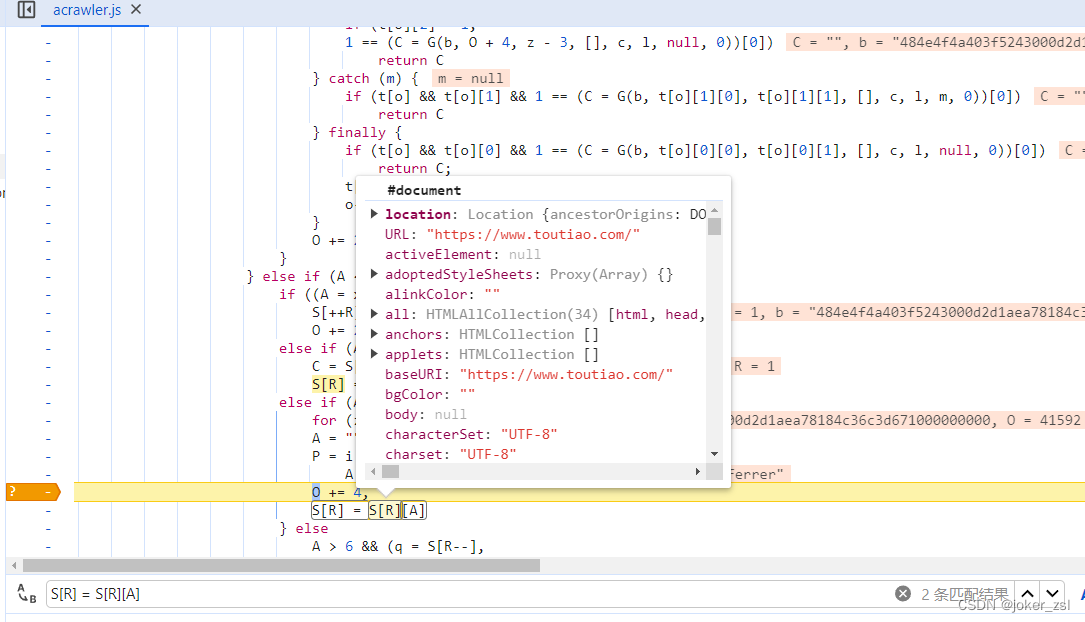
补上环境再试
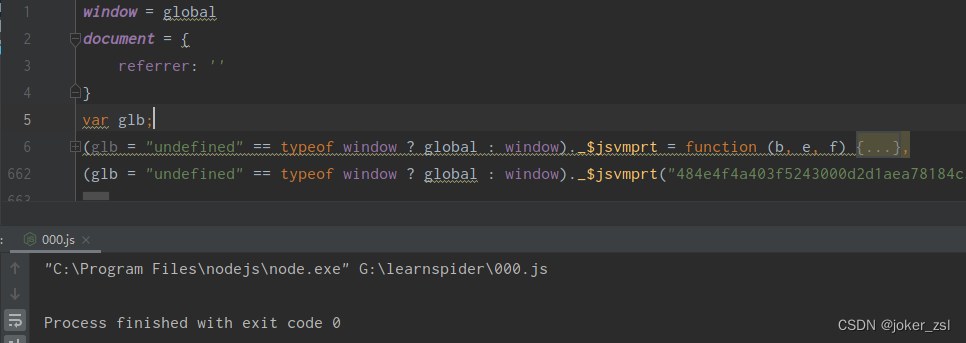
ok,此时扣下的jsvmp的部分不报错了,那加上需要的获取 _signature的代码,继续运行,继续补环境
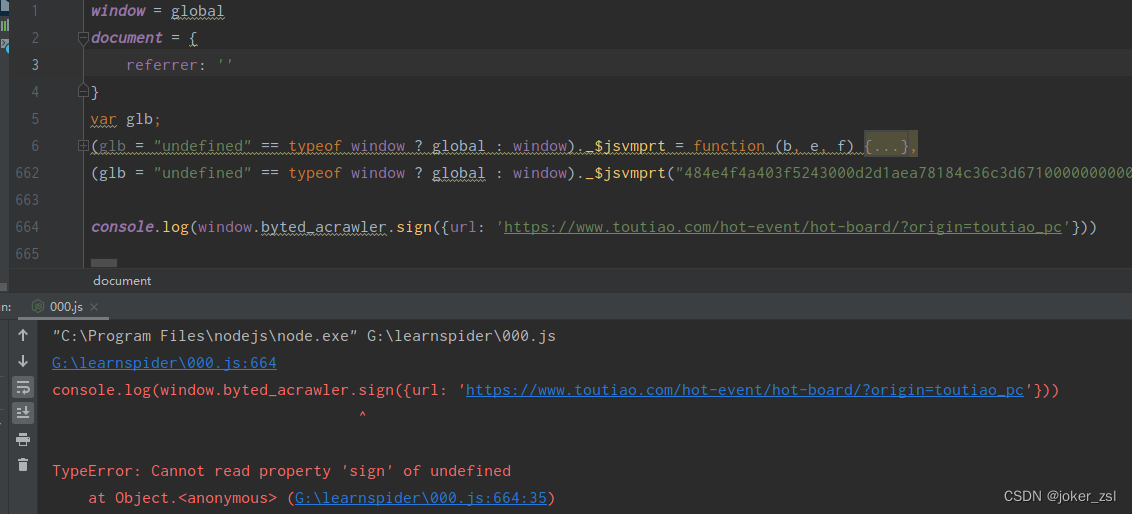
好了,新的报错已经出现,提示找不到sign
讲道理,解释器还原的代码中必会有 sign方法,但此时没有,原因会是什么呢?
原因是因为jsvmp的代码里加了很多环境检测的代码,用来检查代码是在浏览器中运行的,还是用node运行的。
比如 "undefined" == typeof window ? global : window 在浏览器中运行返回的是window对象,用node运行返回的是 global

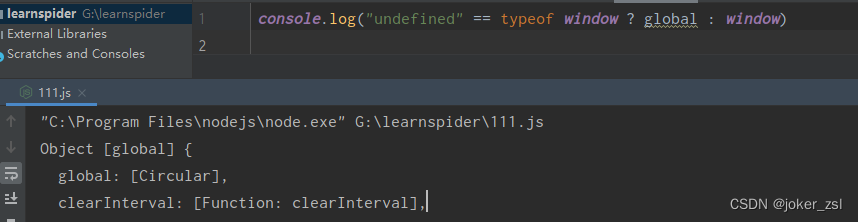
所以这一长串的环境检测的三元表达式中,我们应该把其表达式的值改成和浏览器中运行的一样
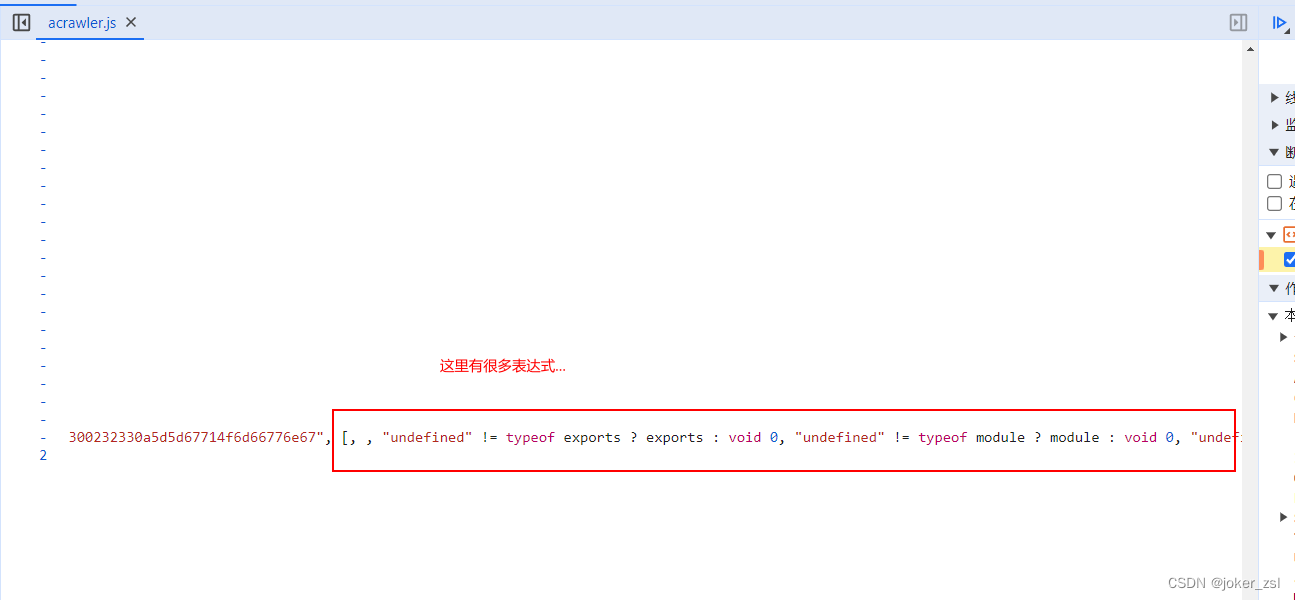
以第一句 "undefined" != typeof exports ? exports : void 0 为例
其值在浏览器中输出结果为undefined,那我们直接把这个表达式改成其结果

改过后跳到了下一个报错,说明是正确的
日志断点
现在报错又出现在了 S[R] = S[R][A],推测这段代码一直是在用不同的A找属性值,那我们每次都下条件断点就很麻烦了,此时需要下日志断点,直接输出经过这段代码的A和S[R]是什么,然后出现报错了就去输出的日志里找,就比较方便了
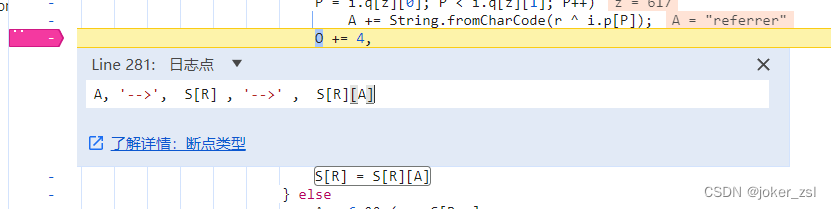
刷新页面,看控制台的日志输出
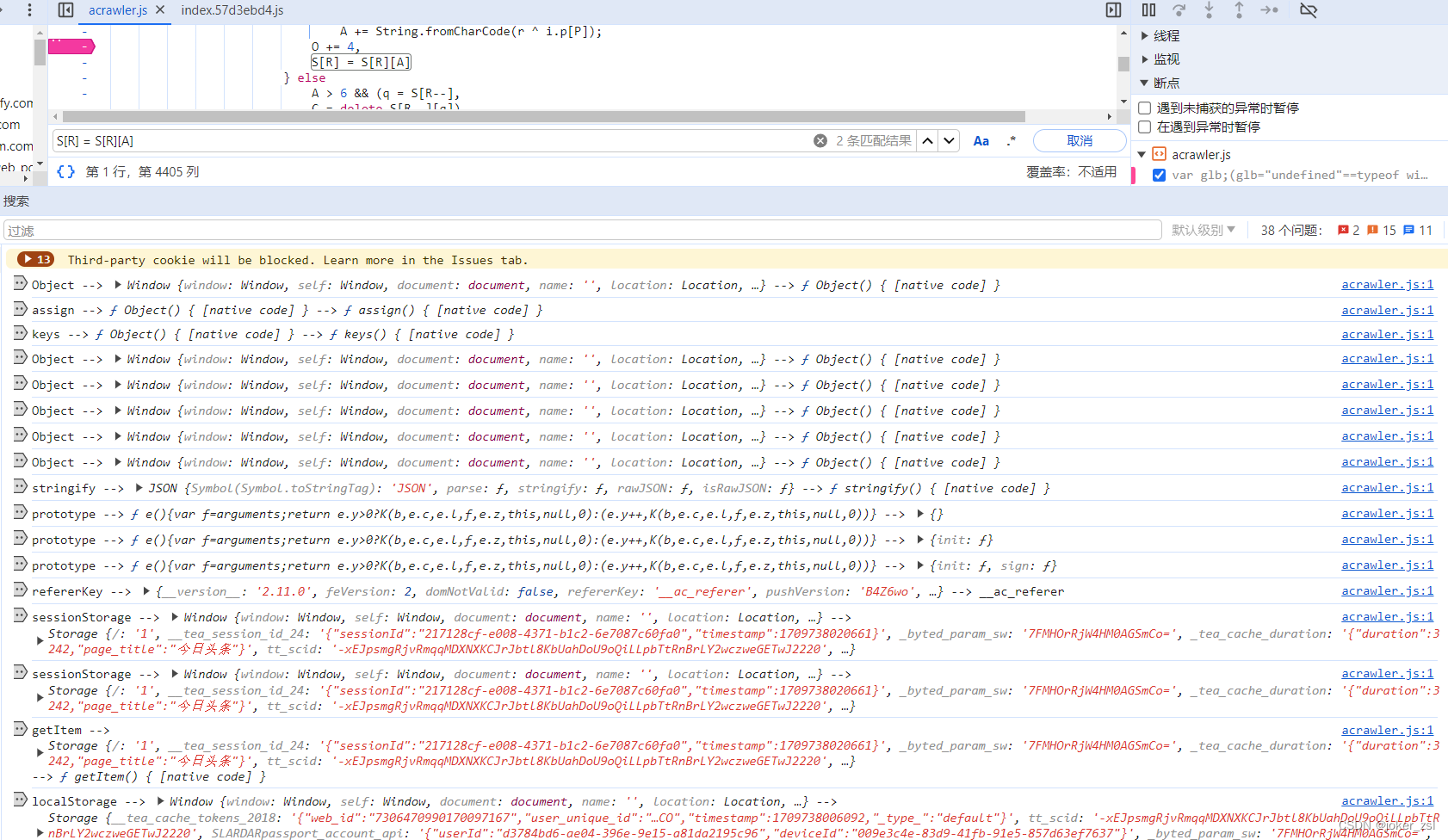
补上href之后,又出现了length的报错。length在日志中很难定位,需要在IDE中debug,逐步运行,看报length错误的时候,前一个A的值是什么
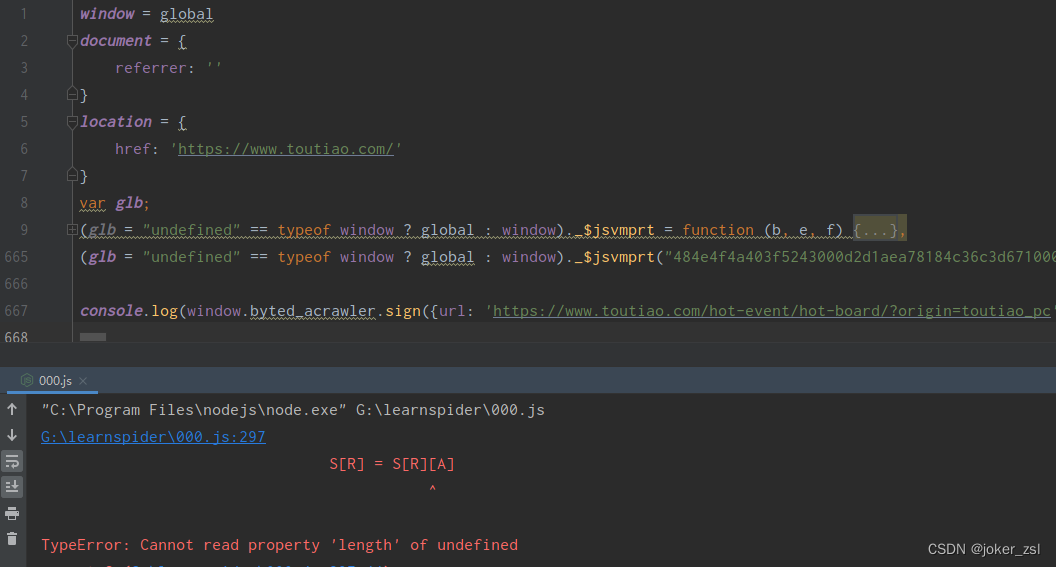
成果展示
按以上方法逐个补环境之后,运行会得到如下结果:
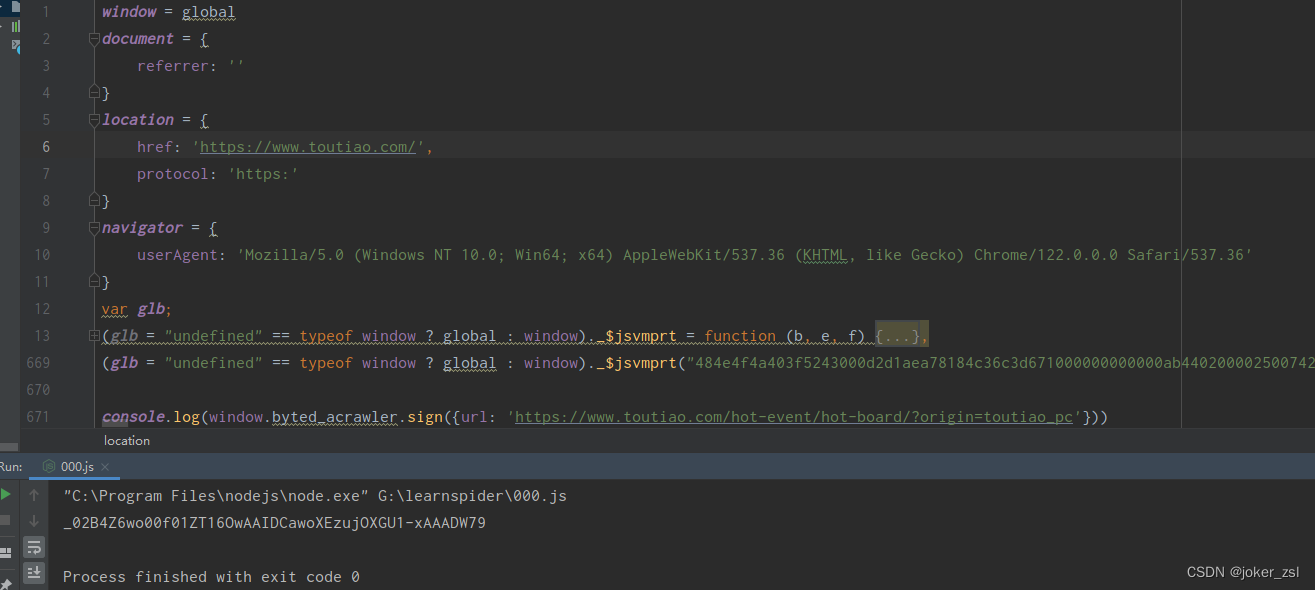
我们此时得到了_signature的值......但又好像没得到,这明显比正常的_signature短啊!

问题出现在哪呢???
一个小知识点:问题出现没有补cookie,如果环境中有用到cookie,那补它!补它!补它!
另一个小知识点:补cookie的位置,如果放前面没效果,那你放最后试试呢
好了,补上cookie的结果如下:
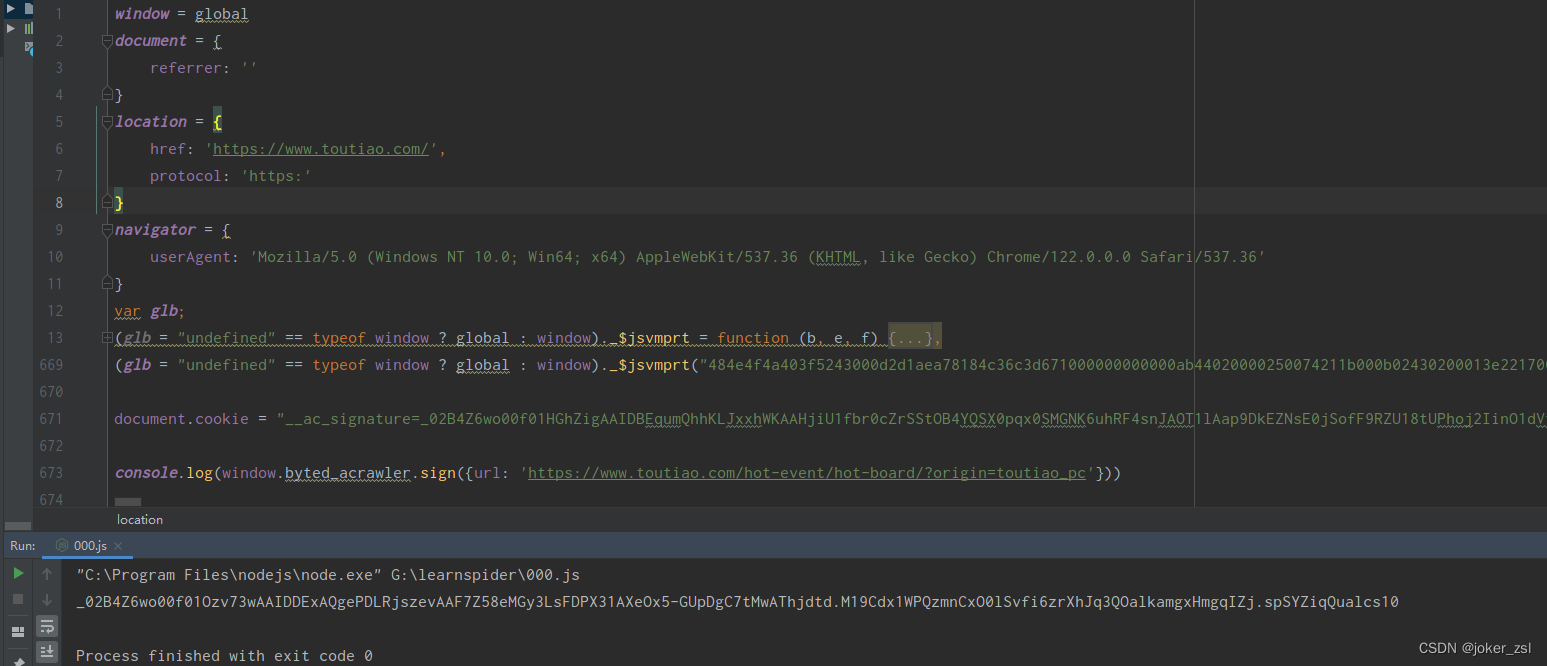
现在这个 _signature看着就正常了
彩蛋
正常情况,得到_signature之后,应该在接口中用下,看看值是不是对的
但是!
文中提到的这个接口,虽然传参用了_signature,但是它没有校验!
意思就是说,你哪怕没有_signature也能正常请求到结果
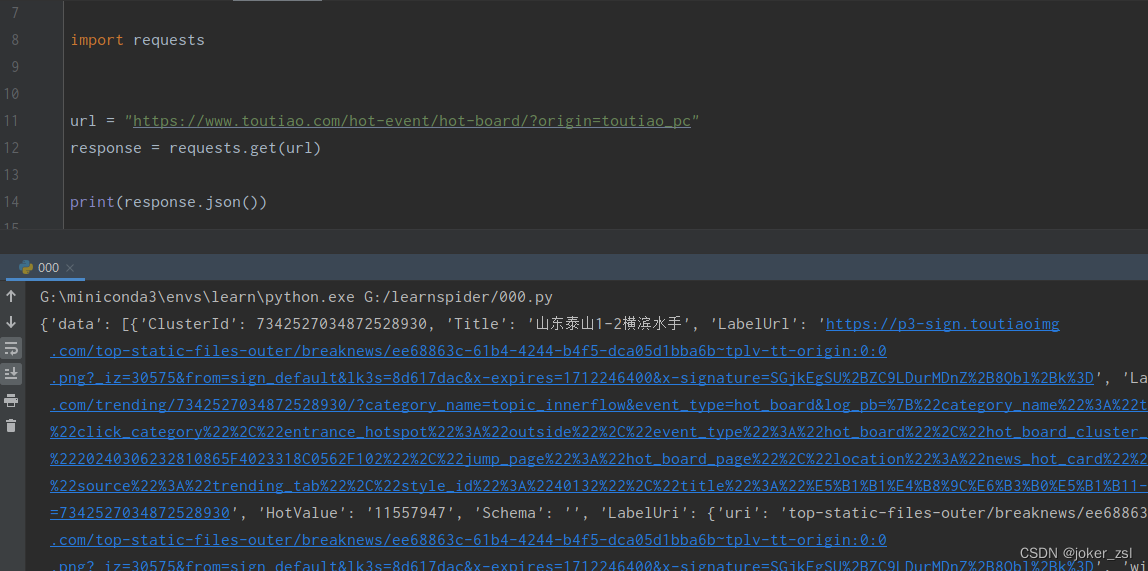
白忙活了,简直离了大谱 mdzz

















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









