






原文:Understanding caching in Postgres - An in-depth guide
作者: Madusudanan.B.N
译者:仲培艺,关注数据库领域,纠错、寻求报道或者投稿请致邮:zhongpy@csdn.net。
缓存
缓存对于数据库的系统性能有着重要意义。
本文虽以Postgres为例,但也可对应到其他数据库系统。
一、高速缓冲存储器是什么以及为什么需要它
不同的计算机部件有着不同的运行速度。人类在理解数字的规模上面,与计算机有着极大的差距。
对此,通过下面这张表格(截取自《文字间的无限空间》The Infinite Space Between Words),会有一个更直观的认识。
表中数据是从人类角度加以估算。
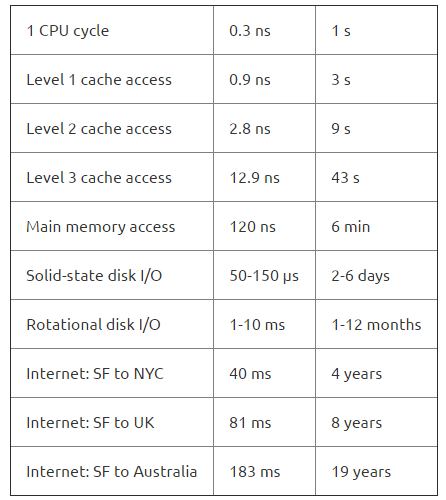
在数据库系统中,技术人员最关注的往往是硬盘的I/O问题。
与新的固态硬盘(SSD)相比,磁盘在随机I/O方面的性能较差。
大多数OLTP的工作负载都属于随机I/O,因此获取硬盘中信息时,速度就会极其缓慢。
为了克服这一劣势,Postgres利用随机存取存储器(RAM)来缓存数据,而这极大地提高了性能。即使对比SSD,RAM速度上也要快上很多。
上面是缓存处理器(cache)的普适原则,几乎适用于所有的数据库系统。
二、理解术语
在进一步拓展知识之前,先了解一些特定术语。
首先,可借助一篇优秀的文章展开阅读。
每当你读完一篇的时候,就接着换一篇难度更深一点的文章继续。这个过程中,要特别留意有关堆内存元组的部分。
另外,还可以看相关的官方文档,但这类相对难理解些。
不管内容是什么,Postgres都有一个抽象化存储,即计算机编程语言脚本(page,8kb)。
下幅图给出了一个简要介绍。
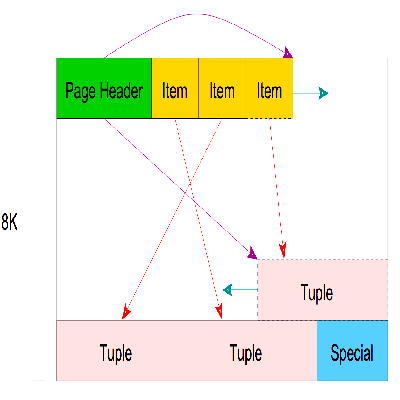
这一抽象概念是下文里将要重点解决的问题。
三、缓存的对象
Postgre缓存的内容如下:
表格数据
指表格的具体内容。
索引
索引亦存储至8k大小的块,即和表格数据存储位置一致,接着看下面的存储区域。
查询执行计划
看一条查询执行计划时,有一个计划阶段,主要用来挑选最适用于查询的计划。Postgres还可以储存这个计划,而这基于的是每一次会话,而一旦会话结束,存储的计划就会被删除。这导致其优化、分析变得棘手了起来,但从总体上来看这一点不是那么重要,除非处于执行中的查询非常复杂,并且/包含大量重复查询。
文档从细节着手对这些内容做出了很好的解释。我们可以通过查询
pg_prepared_statements来找出缓存了哪些东西。这里要注意的是,在结束的会话间无法获取缓存,有且仅对正在进行的会话可见。
下文将进一步研究表格数据和索引缓存的细节问题。
四、内存区
Postgres具有多个配置参数,则需要理解参数指代的含义。
对于缓存来说,最重要的配置当属shared_buffers。这在Postgres源代码内部,又称为NBuffers,用以存储共享数据至内存。
Shared_buffers也仅仅是由8kb大小的块所形成的数组。每个脚本内部都包含元数据,如前所言,在此处起到区分的作用。Progres在查看硬盘数据之前,会先查找shared_buffers内的脚本,若此处有hit参与,则其将在这一环节返回数据,从而避免硬盘的I/O问题。
五、LRU/Clock清理缓存算法
关于存储器内数据的缓存和清理的装置,受控制于Clock清理缓存算法。
因其被用以处理OLTP工作负载,故而几乎所有的信息传输都是在内存下进行的。
下面从细节处谈一谈每一项操作。
缓冲区分配
Postgres是一个基于过程的系统,换言之,每一次连接自身都含有一个本地操作系统进程,这源于Postgres的root进程(原称postmaster)。
若一个进程要求一个LRU高速缓冲存储器下的脚本(一旦该脚本经过一个经典的SQL查询而获得,则进程结束),它要求在缓冲区分配。若block已存于高速缓冲存储器,则其将被锁定并返回。而这个锁定过程也将提升下面将要讨论到的使用计数。而如果使用计数显示为0,则脚本将被解除锁定。
只有当所有缓冲区或slots都包含一个脚本之后,才会进行到缓存区清理环节。
缓存区清理
计算机学科学的一个经典问题就是确定哪些脚本应当从内存中删除,并写入硬盘。
由于对之前的运行没有记录,简单一个LRU(Least Recently Used,最近不常使用算法)在实际中很难很好地工作。
而Postgres保存了脚本使用计数的运行轨迹,因此如果一个脚本的使用计数是0,则其将从内存中被删除并写入硬盘。此外,在遇到脏页的情况下,也将被写入硬盘(详情见下文)。
暂且抛下具体细节不看的话,缓存算法本身几乎不需要调整,而且其智能程度远超于人的想象。
六、脏页和高速缓冲存储器失效
一直到这里我们都在讨论选择查询的问题,那DML查询呢?简单来说,二者写入相同的脚本。若为内存,则直接写入,否则先从内存中提取出来再写入。
这就是产生“脏页”这个概念的环节,也就是说,一个脚本已被修改还未写入硬盘的情况。
在我们继续之前,还有许多功课和研究要做,这里特别强调关于WAL日志和内部事件(checkpoints)。
WAL是一个重做日志,主要用以保存系统内部发生一切的轨迹。这是通过将所有的变化分别录入一个WAL日志来实现。Checkpointer就是一个在一个time setting的控制下,定时将所谓的脏页写入磁盘的进程。之所以如此操作,是因为考虑到数据库崩溃时从头开始重复所有操作的需要。
这是从内存中删除脚本最常见的方法,而在经典案例中LRU算法清理几乎没有出现过。
七、理解高速缓冲存储器(cache)
Explain是理解计算机内部正在进行写什么的好方法。这个方法甚至能够告诉你有多少数据块是来自磁盘的,又有多少是来自shared_buffers,即内存的。
例如下面这个查询计划:
performance_test=# explain (analyze,buffers) select * from users order by userid limit 10;
Limit (cost=0.42..1.93 rows=10 width=219) (actual time=32.099..81.529 rows=10 loops=1)
Buffers: shared read=13
-> Index Scan using users_userid_idx on users (cost=0.42..150979.46 rows=1000000 width=219) (actual time=32.096..81.513 rows=10 loops=1)
Buffers: shared read=13
Planning time: 0.153 ms
Execution time: 81.575 ms
(6 rows)共享读取指的是其取自磁盘且不被缓存。若该查询再次运行,且缓存配置正确的话(我们将在下面讨论),其将以共享hit的形式呈现。
performance_test=# explain (analyze,buffers) select * from users order by userid limit 10;
Limit (cost=0.42..1.93 rows=10 width=219) (actual time=0.030..0.052 rows=10 loops=1)
Buffers: shared hit=13
-> Index Scan using users_userid_idx on users (cost=0.42..150979.46 rows=1000000 width=219) (actual time=0.028..0.044 rows=10 loops=1)
Buffers: shared hit=13
Planning time: 0.117 ms
Execution time: 0.085 ms
(6 rows)通过这个方法,很容易从查询的角度来获知缓存的量,而无需通过OS/Postgres的Internals来完成。
八、全面扫描案例
全面扫描,在没有索引且Postgres必须从磁盘中提取所有数据的情况下,对于这类高速缓冲存储器来说归属问题区域。
由于单次扫描能清楚存储器内的所有数据,故而其操作方法有所不同。它选用一组共计256K.B大小的缓冲区,而非常规的LRU/Clock清理缓存算法。下面的查询展示了它的操作方法。
performance_test=# explain (analyze,buffers) select count(*) from users;
Aggregate (cost=48214.95..48214.96 rows=1 width=0) (actual time=3874.445..3874.445 rows=1 loops=1)
Buffers: shared read=35715
-> Seq Scan on users (cost=0.00..45714.96 rows=999996 width=0) (actual time=6.024..3526.606 rows=1000000 loops=1)
Buffers: shared read=35715
Planning time: 0.114 ms
Execution time: 3874.509 ms再次执行上述查询。
performance_test=# explain (analyze,buffers) select count(*) from users;
Aggregate (cost=48214.95..48214.96 rows=1 width=0) (actual time=426.385..426.385 rows=1 loops=1)
Buffers: shared hit=32 read=35683
-> Seq Scan on users (cost=0.00..45714.96 rows=999996 width=0) (actual time=0.036..285.363 rows=1000000 loops=1)
Buffers: shared hit=32 read=35683
Planning time: 0.048 ms
Execution time: 426.431 ms从中我们可以清楚地看到32个块清楚地转入了内存,即32*8= 256 KB。这在src、backend、storage、buffer和README中都有所说明/解释/体现。
九、内存流和OS缓存
Postgres是一个跨平台数据库,其缓存很大程度上依赖于操作系统。
实际上shared_buffers是在复制OS的操作。下面给出一张典型的数据在Postgres内部的流向图。
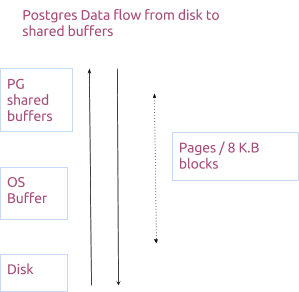
起初的确令人困惑,由于缓存是由OS和Postgres二者同时管理的,但这样操作也是有原因的。
谈及操作系统,高速缓冲存储器则需要一个独立的post,网上也有很多可供利用的资源。
要记住OS缓存数据是处于和上面提到的一样的原因,即为什么我们需要一个高速缓冲存储器那一部分内容。
我们可以把I/O分为两类,即读和写。简言之,数据从磁盘流入内存叫做读;数据由内存流入磁盘称为写。
读
参考上面的流程图,可以发现写指的是数据从磁盘到OS存储器再到
shared_buffers的转移过程。有时,OS存储器和
shared_buffers可以控制相同的脚本,而这可能导致空间浪费,但这里要记住,OS存储器所用的是简单的LRU算法而非数据库优化的clock sweep。一旦脚本页的共享缓冲功能减弱,OS存储器内则无法读取,且若有备份,也很容易被删除。在实际情况下,并不存在太多被同时储存于各内存区域的脚本页。这也是建议仔细规划
shared_buffers大小的原因之一。过分硬性的规定将有损其性能,例如让其承载最大份额的内存或是给其分配的过少。针对其优化问题,下文将详解。
写
写是由内存到磁盘的数据转移。这个环节正是脏页产生之处。一个脚本一旦被标记为脏页,则将被传输至OS存储器,随后则被写入磁盘。在这个环节,OS在输入通信量的基础上享有更大的调度输入输出的自由。
如上文所说,若OS存储器容量较小,则其不能对写入进行重新排序,也不能对输入输出进行优化。而这对于高工作负载的写来说是非常重要的。因此,OS存储器的大小也很重要。
十、初始配置
对于很多数据库系统来说,并不存在直接适用的万能配置。配有基础配置的PostgreSQL ships经过优化增强了其兼容性而非性能。
依据应用程序、工作负载来优化配置,是数据库管理员、开发者的责任。然而Postgres有一个很好的文档用以指示从何处开始。
一旦确立了默认、启动配置,即可通过负载、性能测试查看其操作情况。
要记住对初始配置的调整是为了更好的获取而不是性能的提高。通常情况下,最好能检测并选择更适宜其工作负载的配置。
十一、随时优化
对于不可检测的东西,自然也无法优化。
有了postgres,就有了两种可供检测的方法。
操作系统
对于在哪个平台上Postgres可以最好地工作这个问题的答案,并未得到普遍的共识,所以此处假设适用的是Linux家庭版操作系统。但这个想法类似。
首先,有一个叫做Io top的工具,可以用它来检测磁盘的输入输出。和top相似的是,它在检测磁盘输入输出时迟早会派上用场。这是只需要运行iotop指令来检测读取、写入。
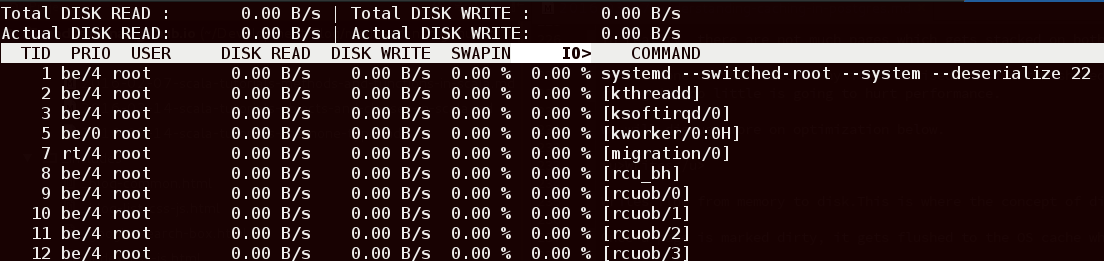
上图清楚地展示了在负载下Postgres是如何运行的,即哪些是针对磁盘的,又有哪些是来自RAM的,这些数据可通过产生的负载来获取。
- 直接来自Postgres
通常情况下,最好监测直接来源于Postgres的数据,而不是经历了OS路径传输的数据。
此外,通常只有在确认Postgres本身存在错误的条件下,才会执行OS层面的监测,但这种情况一般不常见。
伴随Postgres,有一些可供支配的工具,可以用来检测内存的性能。
-
默认是SQL explain。它能给出比其它数据库系统要更多的信息,但在理解上的难度也要相对高一些。故而需要通过练习来加以熟悉。不要错过那几个有用的flags,因为如前所见,他们将被特别缓存。
进入下面的链接来深入了解explain的相关内容:
-
查询日志是用以了解系统内部所发生的事件的另一途径。
我们无需事无巨细地全部记录,只需要记录特定时间间隔间的查询,或者运用
log_min_duration_statement参数以采用慢速查询日志。 -
这也可以帮助你利用慢速查询自动记录执行计划。它能够让你在无需手动运行explain的情况下进行调试。
-
上面提到的方案都很好,但是缺乏巩固的理念。
这是Postgres内部建立的模块,但是在默认情况下会产生缺陷。
可以通过创造
extension pg_stat_statements来使之工作。一旦其开始运行,经过一定量的查询之后,即可以展开如下查询。
SELECT
(total_time / 1000 / 60)::decimal as total_minutes,
(total_time/calls)::decimal as average_time,
query
FROM pg_stat_statements
ORDER BY 1 DESC
LIMIT 100;给出大量查询所消耗的时长及其平均值的细节信息。
这个方法的缺陷在于它消耗了部分性能,故而在生产系统中不常推荐这个方法。
-
如果想要获得更深入的了解,还有两个可以直接深入
shared_buffers和OS 存储器内部的模块。值得注意的是,explain(analyze,buffers)只显示出自
shared_buffers的工具,不包括出自OS存储器的。PG缓冲存储器
这帮助我们实时掌握共享缓冲区内的数据。收集来自shared_buffers的数据,并存至pg_buffercache内部方便查看。
下面给出一个查询样例,它列出了前一百的表格和存储的脚本的数量。
SELECT c.relname,count(*) AS buffers
FROM pg_class c INNER JOIN pg_buffercache b
ON b.relfilenode=c.relfilenode INNER JOIN pg_database d
ON (b.reldatabase=d.oid AND
d.datname=current_database())
GROUP BY c.relname ORDER BY 2 DESC LIMIT 100;PG fincore
这是一个外部模块,负责提供OS如何存储脚本的信息。这一层级较低且影响力较强。
这是一个内置模块,它确实能够负载数据到
shared_buffers或OS存储器或为二者共有。如果觉得内存预热是个问题的话,便可以借此来进行很好的调试。
虽然还有其它可以用以了解Postgres存储器的方法,但我这里已经列出了最为普遍以及最为便于使用的几项了。有了这些工具,就不会再出现由于内存问题导致的数据库运行缓慢。
参考文献















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









