







 本文探讨了深度学习的应用,如图像识别和自然语言处理,以及高效的计算基础,如Numpy和Scipy。重点讲解了图像识别的难点和KNN方法,然后转向线性分类器,介绍其得分函数和损失函数。最后,讨论了实践中的图像分类方法,如KNN、SVM和Softmax。
本文探讨了深度学习的应用,如图像识别和自然语言处理,以及高效的计算基础,如Numpy和Scipy。重点讲解了图像识别的难点和KNN方法,然后转向线性分类器,介绍其得分函数和损失函数。最后,讨论了实践中的图像分类方法,如KNN、SVM和Softmax。
七月算法5月深度学习班课程笔记——No.2
1. 深度学习与应用
1. 图像上的应用:可以根据图片,识别图片的内容,描述图像;模仿人的创造性生成画作;相册自动归类等。


2. NLP上的应用:用RNN学习某作家的文笔风格进行写作、学习代码写作等。下图为RNN学习了200M的代码量后自动生成的代码片段,代码的格式已经比较相似了。
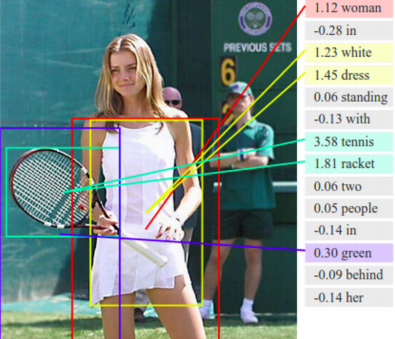
3. 综合应用:识别物体,再根据识别出来的物品组织成文本描述。
2. 高效计算基础
python基本类型、容器等基础的语言知识,请移步:python基础教程
Numpy:矩阵运算
Scipy:稀疏矩阵求距离。
科学计算库的安装与使用可以移步:Python及科学运算库的安装
3. 图像识别难点与KNN
图像识别的核心问题:一个图像给计算机输入的是一个矩阵,每一个像素点上都是一个RGB颜色值,根据矩阵去做图像识别,计算置信度。
难点:
1. 视角不同:每个事物旋转或者侧视最后的构图都完全不同
2. 尺寸大小不统一:相同内容的图片也可大可小
3. 变形:很多东西处于特殊的情形下, 会有特殊的摆放和形状
4. 光影等干扰/幻象重点内容
5. 背景干扰
6. 同类内的差异(比如椅子有靠椅/吧椅/餐椅/躺椅…)
图像识别的基本流程:
输入:我们的给定K个类别的N张图片, 作为计算机学习的训练集。
学习:让计算机逐张图片地『 观察』 和『 学习』
评估:就像我们上学学了东西要考试检测一样, 我们也得考考计算机学得如何, 于是我们给定一些计算机不知道
类别的图片让它判别, 然后再比对我们已知的正确答案。
K最邻近法(KNN):K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
KNN做图像识别有一些缺点,比如准确度不高,因为找不到图像合适的特征,而且KNN需要记录全部训练数据。那么可以试试线性分类器,用逻辑回归或者linearSVM。
4. 线性分类器
4.1 线性分类器
线性分类器会有一个得分函数,比如CIFAR-10数据集,数据集里有10个类别,每个图像的大小都是32x32,每个像素点有RDB的值,所以总共有32x32x3=3072 个数,线性分类器就是把这些数作为输入,即3072x1的向量,给定权重矩阵W[n*3072],n是要判定的类别的数量。通过矩阵相乘得到得分函数:
其中W是通过训练得到的。那么得到的得分高低就可以判定类别。
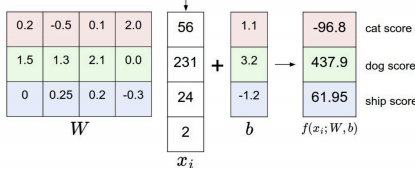
线性分类器的理解:
1. 空间划分:Wx+b是空间的点。
2. 模板匹配:W的每一行可以看做是其中一个类别的模板。每类得分,实际上是像素点和模板匹配度,模板匹配的方式是内积计算。
4.2 损失函数
损失函数:由得分函数我们知道,给定W,可以由像素映射到类目得分。损失函数用来评估W、b的好坏,衡量吻合度,可以通过调整参数/权重W, 使得映射的结果和实际类别吻合。有两种损失函数:
一是hinge loss/支持向量机损失。
对于训练集中的第i张图片数据
xi
,在W下会有一个得分结果向量
f(xi,W)
,第j类的得分为我们记作
f(xi,W)j
,则在该样本上的损失我们由下列公式计算得到:
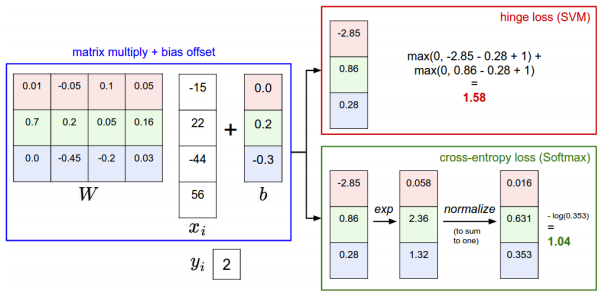
假如有猫、狗、船三个类别,得分函数计算某张图片的得分为 f(xi,W)=[13,−7,11] ,而实际的结果是第一类 yi=0 。假设 Δ=10 ,用上面的公式把错误类别 (j≠yi) 都遍历了一遍,则求值加和:
计算得到狗的损失函数为0,船的损失函数为8,所以被判定为船的概率还是比较高的。所以 Δ 可以看做一个超参数,规定一个警戒线用来平衡损失。

二是 互熵损失(softmax分类器)。
对于训练集中的第i张图片数据 xi ,在W下会有一个得分结果向量 fyi ,则损失函数记作:
把得分求exp再做归一化,计算损失。两种损失函数得到的结果会有些区别,实际的求解过程比较如下:
5. 实践
KNN分类器、用SVM和Softmax分类器做图像分类,详见ipython。















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









