







线性分类器
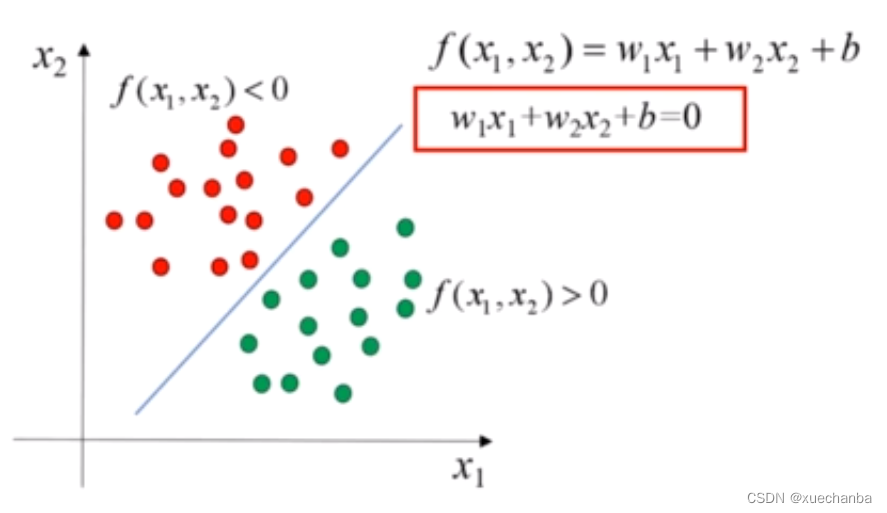
如上图所示,这是二维空间中的一个数据集,如果他正好能够被一条直线分成两类,那么我们称它为线性可分数据集,这条直线就是一个线性分类器。
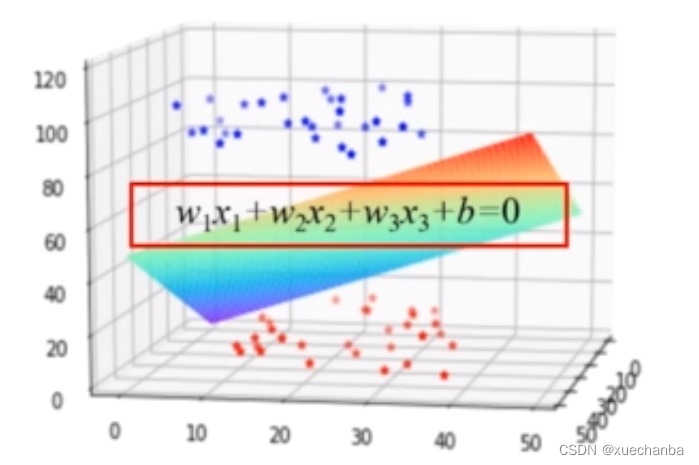
在三维空间中,如果数据集线性可分,是指能够被一个平面分为两类。
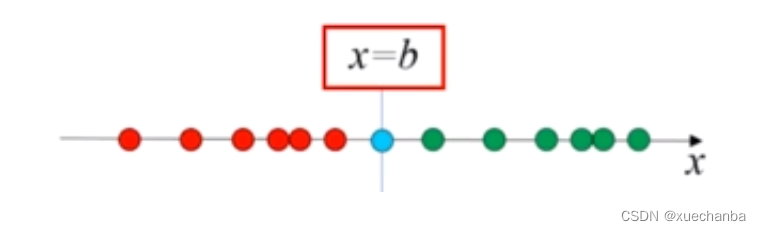
在一维空间中,所有的点都在一条直线上,如果线性可分。可以理解为它们能够被一个点分开。
这里的直线、平面、点被分为决策边界。
一个 m 维空间中的数据集,如果能够被一个超平面一分为二,那么这个数据集就是线性可分的,这个超平面就是决策边界。

例如,这是二维平面上的一条直线,
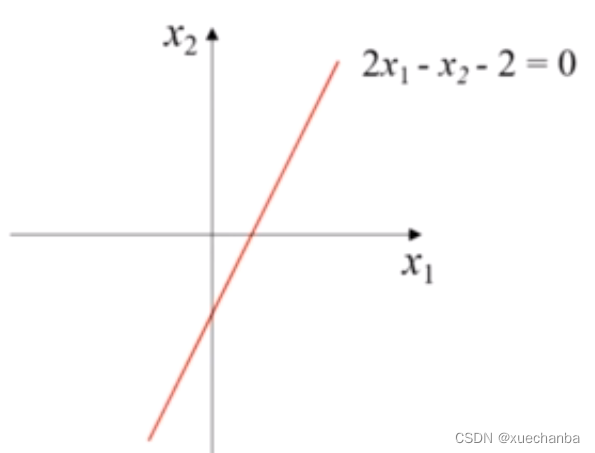
它可以把平面切分成两部分,也就是说将这个平面中的点分成了两类。
下图为这个分类器的表达式:
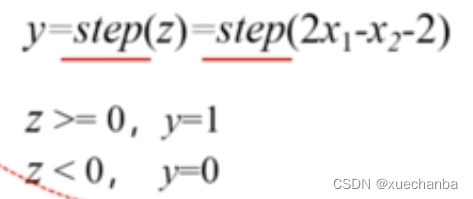
其中,z 代表线性组合,2x1 - x2 - 2,step是阶跃函数,当 z 大于 0 时,分类器的输出为1,当 z 小于 0 时,分类器的输出为0。
我们随机选取几个点,下图为这些点在图中的位置。
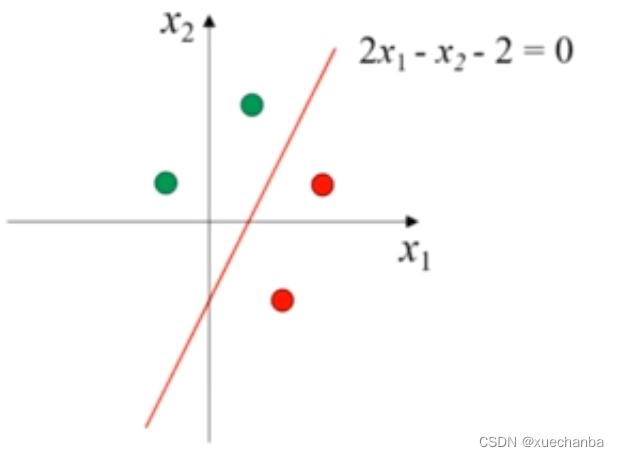
y是分类结果

这里的step函数还可以使用Sigmoid的函数来代替,可以发现这就是逻辑回归。
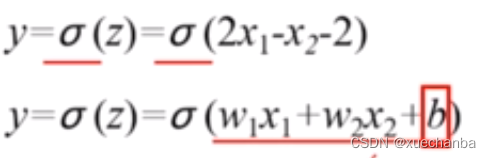
逻辑回归其实就是构造一个线性分类器。实现对线性可分数据集的划分,其中的线性模型就是决策边界。
从这个例子中,也可以看出来这个偏置项 b 的意义。如果没有这个 b ,那么所有的分类器都要经过原点。显然模型就丧失了一般性。
线性不可分
除了线性可分问题,还有线性不可分问题。如下图所示,
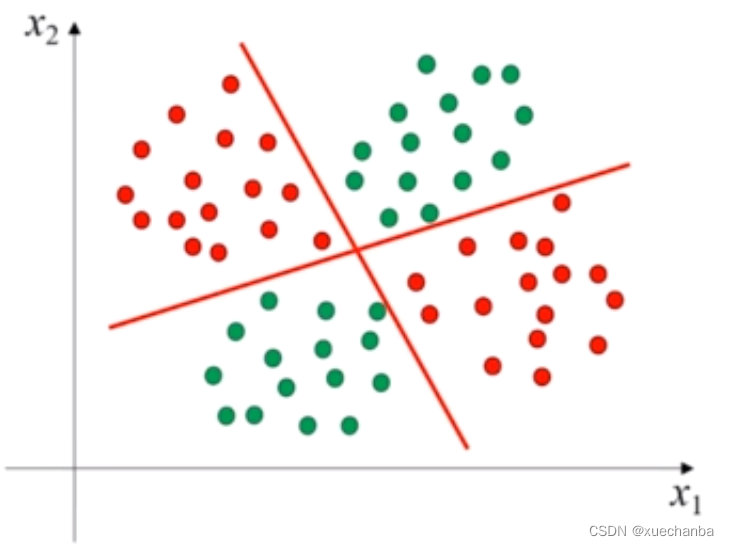
上图中的这个数据集中的两类样本点,就无法通过一条直线完全区分开。它需要两条直线才能分开。
下图中的这个数据集中的样本,
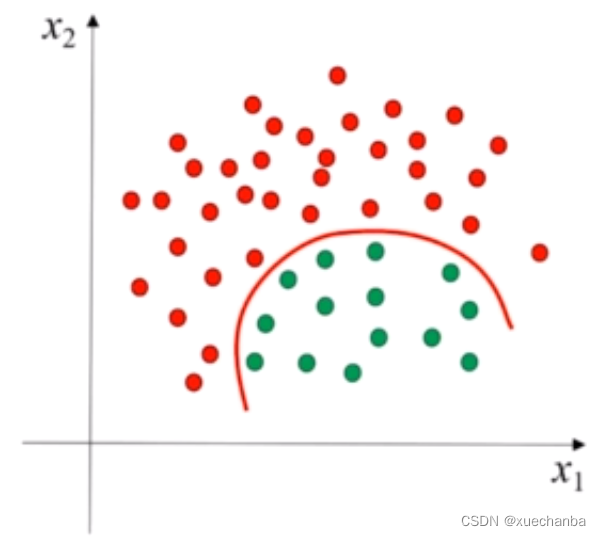
也无法通过一条直线区分开,它需要一条曲线分开。这些都是非线性可分的数据。
逻辑运算
在逻辑运算中,与或非运算都是线性可分的,而异或运算是非线性可分的。
与运算
在逻辑与运算中,只有当x1和x2都是1时,结果才为1,否则结果为0。
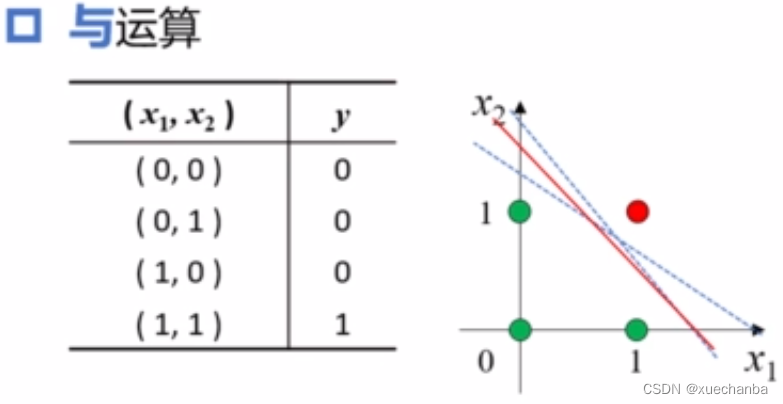
这四个点可以被分为两类,绿色的被分类为0,红色的点被分类为1,显然可以被一条直线分成两类,这根直线的参数可以通过训练得到,并且一定收敛,此外,可以看出这根直线并不是唯一的,这些直线也都可以区分这两类点,它们都可以作为与运算的分类器。
或运算
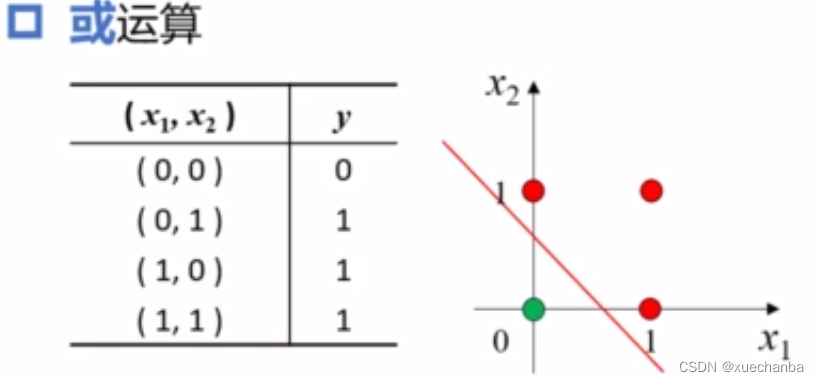
这四个点也可以被分为两类,绿色的被分类为0,红色的点被分类为1。
非运算
逻辑非的输入只有1个自变量,
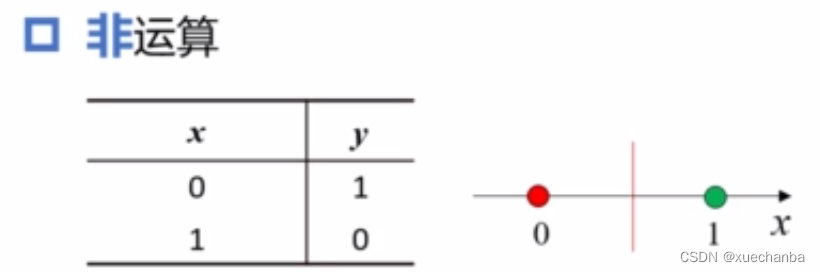
是一维的,它也是线性可分的。
异或运算
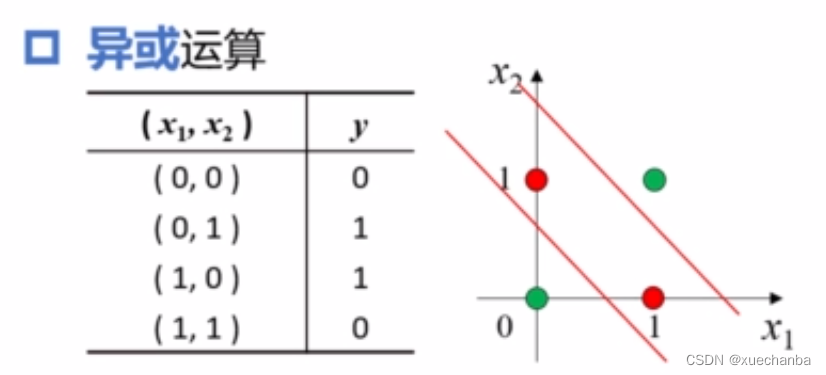
异或是指两个操作数相同,结果为0。而两个操作数不同,则结果不同。
显然,它不是线性可分的。


















 2108
2108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











