




论文笔记
预备知识
ablation study(消融研究) 就是为了研究模型中所提出的一些结构是否有效而设计的实验。如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study。也就是(控制变量法)
各向异性缩放:
这种方法很简单,就是不管图片的长宽比例,管它是否扭曲,进行缩放就是了,如下图D所示;
各向同性缩放:
1 先扩充后裁剪
直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;如下图B所示;
2 先裁剪后扩充
先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如下图C所示;
对于上面的异性、同性缩放,文献还有个padding处理,图中第1、3行就是结合了padding=0, 第2、4行结果图采用padding=16的结果。经过最后的试验,作者发现采用各向异性缩放、padding=16的精度最高

PASCAL VOC目标检测任务,共20类物体,加上背景21类
论文记录
时间:2014年
由于我们结合了Region proposals和CNNs,所以起名 R-CNN:Regions with CNN features
Q:为啥为什么RCNN用SVM做分类而不直接用CNN全连接之后softmax输出?
A:刚开始时只是用了ImageNet预训练了CNN,并用提取的特征训练了SVMs,此时用正负样本标记方法就是前面所述的0.3,后来刚开始使用fine-tuning时,也使用了这个方法,但是发现结果很差,于是通过调试选择了0.5这个方法,作者认为这样可以加大样本的数量,从而避免过拟合。然而,IoU大于0.5就作为正样本会导致网络定位准确度的下降,故使用了SVM来做检测,全部使用ground-truth样本作为正样本,且使用非正样本的,且IoU大于0.3的“hard negatives”,提高了定位的准确度
My理解:为了防止过拟合,需要保证一定的样本数量,因此IOU的标准比较宽松,正式因为IOU的标准比较宽松,因此继续用CNN直接分类的话准确率会下降,所以要用SVM来分类,SVM适合小样本训练。
在fine-tunning和SVM训练这两个阶段,我们定义得正负样例是不同的:
fine-tunning阶段是由于CNN对小样本容易过拟合,需要大量训练数据,故对IoU限制宽松: IoU>0.5的建议框为正样本,否则为负样本; SVM这种机制是由于其适用于小样本训练,故对样本IoU限制严格:Ground Truth为正样本,与Ground Truth相交IoU<0.3的建议框为负样本
Bounding-box回归用的是pool5的特征
在ImageNet上训练的模型直接拿到PASCAL数据集上跑,发现fc6和fc7层对性能的影响甚微,可见CNN的主要表达能力来自卷积层而不是全连接层,finetune之后的性能提升明显,fc6和fc7的提升明显优于pool5,说明pool5从ImageNet学习的特征通用性很强
思路:
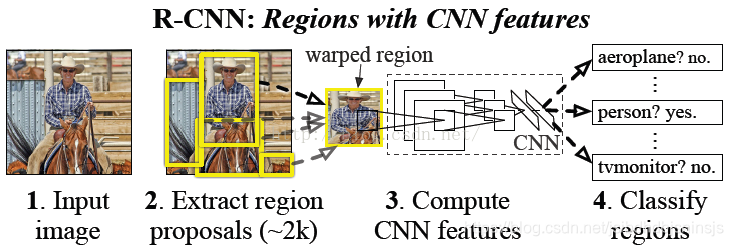
实现细节
对用SS方法提取出的2000个候选框缩放至统一大小,计算其与GT的IOU,若大于0.5则归为物体类别,否则归为背景类别
finetune:将AlexNet的最后一层替换为N+1个输出softmax层
,如果你不进行fine-tuning,也就是你直接把Alexnet模型当做万金油使用,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征最会训练的svm分类器的精度就会飙涨。
据此我们明白了一个道理,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
总结
看完之后似懂非懂,大体思路早就知道了,具体的实现细节还没有学习的很明朗
参考文档:
文档1

















 9074
9074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









