







每个卷积核的深度必须和上一层网络的深度相同,卷积核的数量为输出的深度,
例1:输入为
32
∗
32
32*32
32∗32,kernel size为
5
∗
5
5*5
5∗5,stride为1,
则输出的大小为
28
∗
28
(
32
−
5
+
1
=
28
)
28*28(32-5+1=28)
28∗28(32−5+1=28)
例2:输入为
227
∗
227
227*227
227∗227,kernel size为
11
∗
11
∗
96
11*11*96
11∗11∗96,stride为4,
则输出的大小为
55
∗
55
∗
96
55*55*96
55∗55∗96(如下图)

LeNet
提出者:Yan LeCun
时间:1986
应用:手写体字符识别
网络结构:共7层(2卷积+2池化+3全连接)
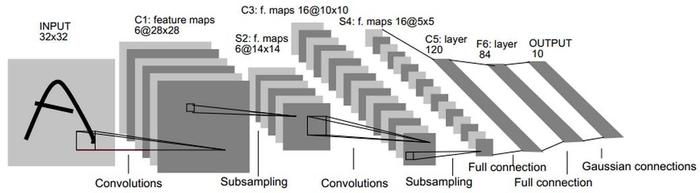
网络结构详解:
输入32*32
conv1的stride为1,卷积核为
5
∗
5
∗
6
5*5*6
5∗5∗6,feature map 为
6
∗
28
∗
28
6*28*28
6∗28∗28
pool2的输出为
6
∗
14
∗
14
6*14*14
6∗14∗14
conv3的stride为1,卷积核为
5
∗
5
∗
16
5*5*16
5∗5∗16,feature map 为
16
∗
10
∗
10
16*10*10
16∗10∗10
pool4的输出为
16
∗
5
∗
5
16*5*5
16∗5∗5
fc5也可以看作卷积层,120个和上一层输出同等大小的卷积核,输出为120
fc6输出为84
fc7输出为10
AlexNet
提出者:Alex Krizhevsky(Hinton的学生)
时间:2012
应用:R-CNN的特征提取器,目标分类,12年ILSVRC冠军
网络结构:共11层(5卷积+3池化+3全连接)
特点:更深的网络结构,dropout,Relu,多GPU训练

输入
224
∗
224
224*224
224∗224(需要pad成
227
∗
227
227*227
227∗227)
conv1的stride为4,卷积核为
11
∗
11
∗
96
11*11*96
11∗11∗96,feature map 为
55
∗
55
∗
96
55*55*96
55∗55∗96
pool2的stride为2,滤波器大小为
3
∗
3
3*3
3∗3,feature map 为
27
∗
27
∗
96
27*27*96
27∗27∗96
(55-3)/2=26, 26+1=27
conv3的stride为1,卷积核为
5
∗
5
∗
256
5*5*256
5∗5∗256,feature map 为
27
∗
27
∗
256
27*27*256
27∗27∗256
大小仍为27说明conv3前先上下左右各pad2
pool4的stride为2,滤波器大小为
3
∗
3
3*3
3∗3,feature map 为
13
∗
13
∗
256
13*13*256
13∗13∗256
(27-3)/2=12, 12+1=13
conv5的stride为1,卷积核为
3
∗
3
∗
384
3*3*384
3∗3∗384,feature map 为
13
∗
13
∗
384
13*13*384
13∗13∗384
conv6的stride为1,卷积核为
3
∗
3
∗
384
3*3*384
3∗3∗384,feature map 为
13
∗
13
∗
384
13*13*384
13∗13∗384
conv7的stride为1,卷积核为
3
∗
3
∗
256
3*3*256
3∗3∗256,feature map 为
13
∗
13
∗
256
13*13*256
13∗13∗256
pool8的stride为2,滤波器大小为
3
∗
3
3*3
3∗3,feature map 为
6
∗
6
∗
256
6*6*256
6∗6∗256
fc9输出为4096
fc10输出为4096
fc11输出为1000
VGG
提出者:Oxford的Visual Geometry Group
时间:2014
应用:Fast R-CNN的特征提取器,14年ILSVRC
网络结构:
VGG16包含了16个隐藏层(13个卷积层和3个全连接层)
VGG19包含了19个隐藏层(16个卷积层和3个全连接层)
特点:证明了增加网络的深度能够在一定程度上影响网络最终的性能,采用堆积的小卷积核代替大的卷积核,多保证具有相同感知野的条件下,提升了网络的深度,从而能让网络来学习更复杂的模型,而且代价还比较小(参数更少)。
不知道为啥想记录一句话,肖老师说的在测试集上的准确率可以训练到很高,这种意义并不大,真正的还是为了应用,以云类图像识别为例,还是要自己拍一些照片或者网上找一些图像取验证算法的可行性和准确性















 1633
1633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









