






- Data Mining的定义为从大规模的数据中抽取非一般、隐含的、先验未知和潜在有用的模式或者知识。JSMLAY:所以模式识别是知识发现的重要内容。
- 数据中的模式太多,难以一一枚举,我们要挖掘的是Closed Patterns.
说白了,就是相同的support的放在一起。例如,支持度都为2的就要放到一个集合中。
max pattern会损失数据信息。
另外一种是Max pattern,就是说只要超过一定support,不管support的差异,就算作一个patter。
Max Pattern注重一定support下的最大的模式,而Close Pattern注重不同support下的模式。 - Apriori算法:
Apriori算法本质上还是一种遍历,只不过在每次遍历的时候减少了一些已知不可行的部分,使得遍历的运算更加可行。
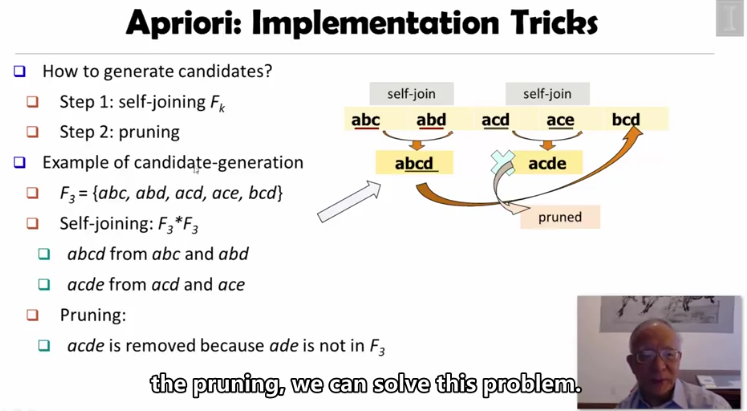
如何生成备选模式呢?使用Self-join + Pruning操作
- 垂直数据管理格式
所谓垂直数据格式,其基本思想是,将以 { 交易 = 对象集合 } 的数据形式,转变为{ 对象 = 交易集合 }的数据形式。
这样做会带来一些变化,如集合的交集就是两个对象的频繁集合,这个比较简便。
另外,交易的数据量大于集合数据,因此用于表示一个对象的集合将会很长。因此,引入diffset概念。




















 4354
4354
09-20
09-20

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









