







 本文深入探讨了机器学习中的有监督学习与无监督学习,重点介绍了聚类算法,如层次聚类、K均值聚类、基于密度的聚类和自组织映射。详细阐述了每种算法的原理、方法和适用场景,通过实例展示了如何应用这些算法,并分析了其优缺点。此外,还涵盖了决策树、贝叶斯分类和KNN等分类方法,以及SVM和支持向量机的分类原理和实践策略。
本文深入探讨了机器学习中的有监督学习与无监督学习,重点介绍了聚类算法,如层次聚类、K均值聚类、基于密度的聚类和自组织映射。详细阐述了每种算法的原理、方法和适用场景,通过实例展示了如何应用这些算法,并分析了其优缺点。此外,还涵盖了决策树、贝叶斯分类和KNN等分类方法,以及SVM和支持向量机的分类原理和实践策略。
有监督学习与无监督学习
有目标变量的研究,称为有监督学习,常用于预测未来。
无目标变量的研究,称为无监督学习,常用于描述现在。
根据具体问题和算法不同,常常分为以下六小类:
- 分类 Classification(有监督学习)
- 回归 Regression(有监督学习)
- 异常检测 Deviation Detection(有监督学习)
- 聚类 Clustering(无监督学习)
- 关联规则 Association Rule Discovery(无监督学习)
- 序列挖掘 Sequential Pattern Discovery(无监督学习)
一般挖掘流程
问题理解
首先是清晰地定义问题和目标其次是评估现有条件。根据资源和约束、判断挖掘项目的可行性制定初步规划和分析思路,将问题分解分解映射到后续的多个数据挖掘步骤中
数据理解
数据准备
数据建模
模型评价
模型部署
聚类
聚类目的是捕获数据的自然结构,从而将数据自动划分为有意义的几个组群,这些组群的特点在于组内的变异较小,而组间的变异较大。聚类分析还可以用来探索数据的结构,还可以用来对数据进行预处理,为进一步的数据挖掘工作起到压缩和降维的作用。
层次聚类
又称为系统聚类。聚类首先要清晰地定义样本之间的距离关系,远近为不同类。
过程: 首先将每个样本单独作为一类,然后将不同类之间的距离最近的进行合并,合并后重新计算类间距。这个过程一直持续到将所有样本归为一类为止。
6种距离计算方法: 最短距离法、最长距离法、类平均法、重心法、中间距离法、离差平方和法。
stats包hclust函数重要参数:样本的距离矩阵,及计算类间距离的方法。下面使用iris数据集来进行层次聚类分析,首先提取iris数据中的4个数值变量,标准化之后计算其欧式距离矩阵。
data <- iris[,-5]
means <- sapply(data, mean); SD <- sapply(data, sd)
scaledata <- scale(data, means, SD)
Dist <- dist(scaledata, method = 'euclidean')
然后根据矩阵绘制热图。从图可看到,颜色越深表示样本间距越近,大致上可以区分出三到四个区块,其样本之间距离比较接近。
heatmap(as.matrix(Dist), labRow = F, labCol = F)
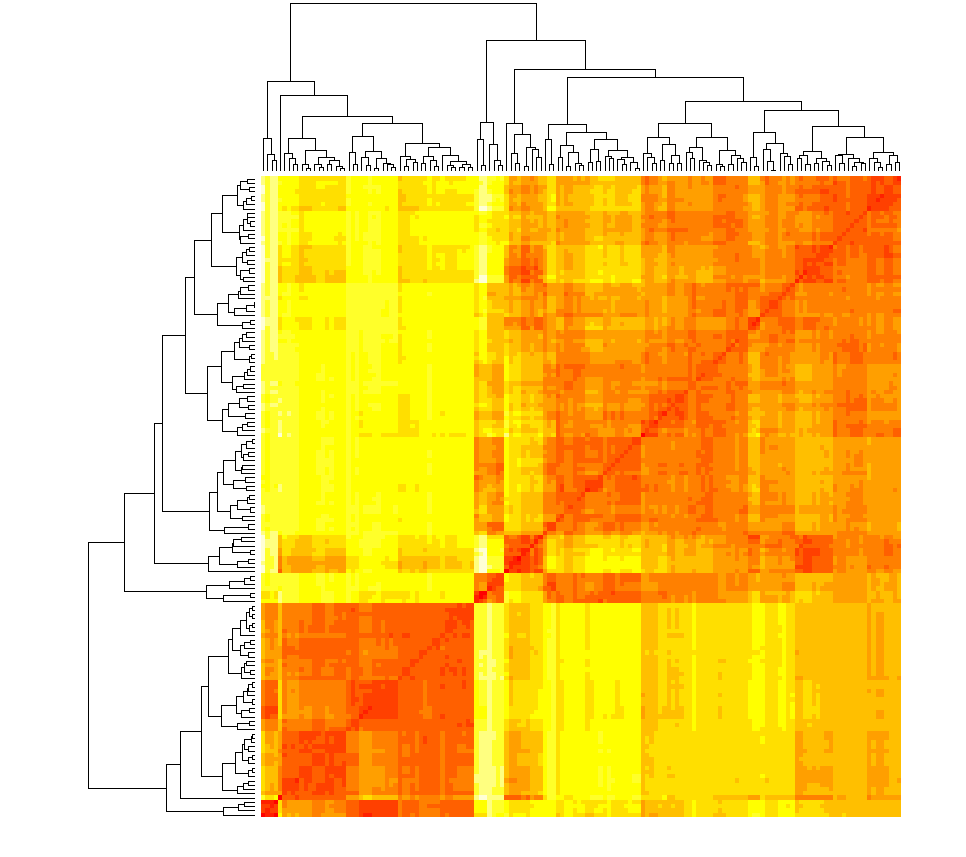
最后使用hclust函数建立聚类模型,结果存在clusteModel变量中,其中ward参数是将类间距离计算方法设置为离差平方和法。如果我们希望将类别设为3类,可以使用cutree函数提取每个样本所属的类别。观察真实的类别和聚类之间的差别,发现virginica类错分了23个样本
clustemodel <- hclust(Dist, method = 'ward.D2')
result <- cutree(clustemodel, k=3)
table(iris[,5], result) **观察聚类和真实的分类对比**
> table(iris[,5], result)
1 2 3
setosa 49 1 0
versicolor 0 27 23
virginica 0 2 48
plot(clustemodel) **聚类树图**
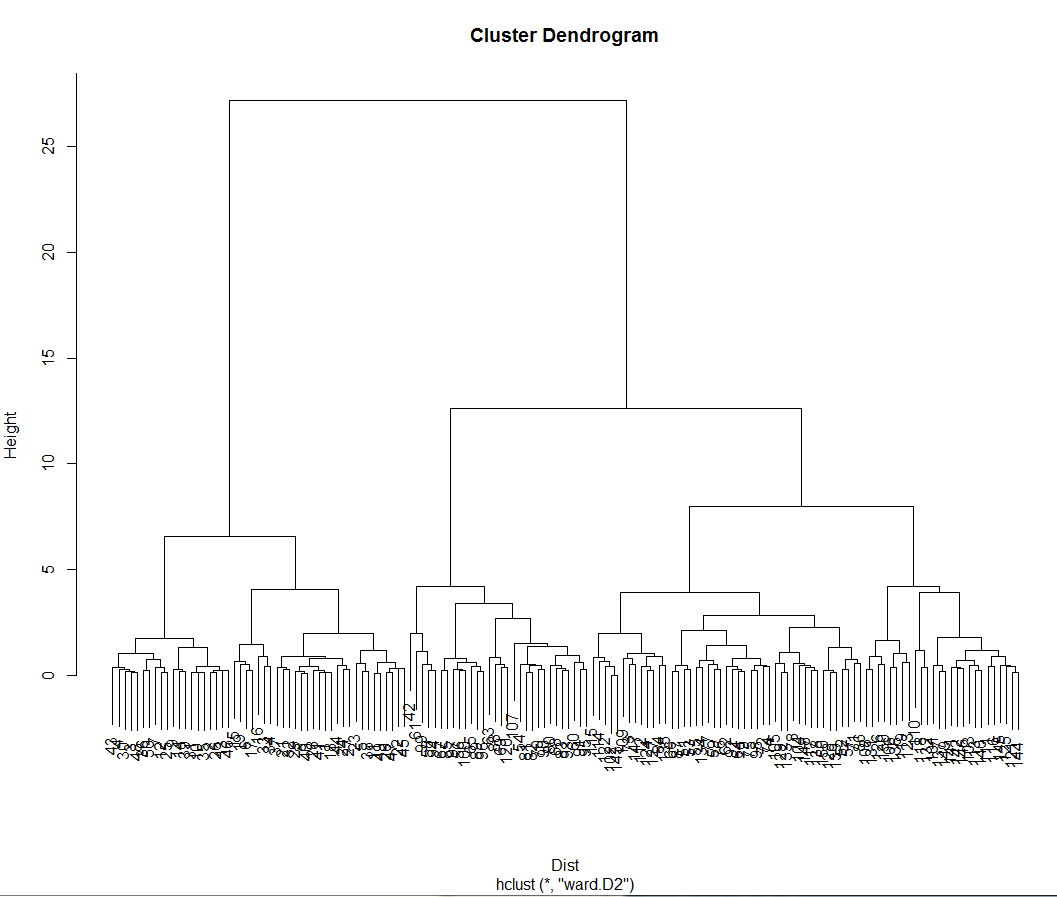
层次聚类的特点是:基于距离矩阵进行聚类,不需要原始数据。可用于不同形状的聚类,但它对于异常点比较敏感,对于数据规模较小的数据比较合适,否则计算量会相当大,聚类前无需确定聚类个数,之后切分组数可根据业务知识,也可以根据聚类树图的特征。
如果样本量很大,可以尝试用fastcluster包进行快速层次聚类。包加载之后,其hclust函数会覆盖同名函数,参数和方法都一样。
library(fastcluster)
clustemodel <- hclust(Dist, method = "ward.D2")
聚类需要将距离矩阵作为输入,所以聚类的关键是距离计算方法的选择,这种选择会极大的影响聚类的结果,而这种选择往往依赖于具体的应用场景。可用于定义“距离”的度量方法包括了常见的欧式距离(euclidean)、曼哈顿距离(manhattan)、两项距离(binary)、闵可夫斯基(minkowski),以及更为抽象的相关系数和夹角余弦等。另外如果特征的量纲不一,还需要考虑适当的标准化和转换方法,或者使用马氏距离。用户也可以输入自定义的距离矩阵。
常规的距离可以通过dist函数得到,其他一些特殊的距离可以加载proxy包。例如余弦距离。
library(proxy)
res <- dist(data,method = 'cosine')
前面计算距离时处理的均为数值变量,如果是二分类变量,可采用杰卡德(Jaccard)方法计算它们之间的距离。例如,x和y样本各有6个特征加以描述,二者取1的交集合个数为3,取1的并集合个数为5,因此相似程度为3/5,那么二者之间的距离可以认为是2/5。
> res <- dist(data,method = 'cosine')
> x <- c(0,0,1,1,1,1)
> y <- c(1,0,1,1,0,1)
> dist(rbind(x,y), method = 'Jaccard')
x
y 0.4
如果是处理多个取值的分类变量,可以将其转为多个二分类变量,其方法和线性回归中将因子变量转为哑变量是一样的作法。
还有一种特殊情况的距离计算,就是分类变量和数值变量混合在一起的情况。下例的两个样本中的第3和5个特征为数值变量,其他为二分类变量,另外还有一个缺失值。我们可以先用离差计算单个特征的距离,再进行合并计算。
x <- c(0,0,1.2,1,0.5,1,NA)
y <- c(1,0,2.3,1,0.9,1,1)
d <- abs(x-y)
dist <- sum(d[!is.na(d)])/6
K均值聚类
K均值聚类又称为动态聚类,它的计算方法快速简便。首先要指定聚类的分类个数N,先随机取K个点作为初始的类中心或者说是质心。计算个样本点与类中心的距离并就近归类。所有样本归类完成后,重新计算类中心,重复迭代这个过程直到类中心不再变化。
使用kmeans函数进行K均值聚类,重要参数如下:
x: 设置要聚类的数据对象,并非距离矩阵。
centers: 用来设置分类个数。
nstart: 用来设置取随机初始中心的次数,其默认值为1,取较多的次数可以改善聚类效果。
下面仍是使用标准化后的iris数据集来聚类,之后提取每个样本所属的类别。
clustemodel <- kmeans(dataScale, centers = 3, nstart = 10)
class(clustemodel)
K均值聚类计算仍然要考虑距离,这里kmeans函数缺省使用欧式距离来计算,如果需要使用其他距离定义,可以采用cluster包中的pam函数,配合proxy包来计算。例如下面我们使用了马氏距离。
library(proxy)
library(cluster)
clustmodel <- pam(dataScale, k = 3, metric = 'Mahalanobis')
clustmodel$medoids
table(iris$Species, clustmodel$clustering)
下两图显示了两项轮廓系数图和主成分散点图以观察聚类效果。轮廓图中各样本点的条状长度为silhouette值,值越大表示聚类效果越好,值越小标书此样本位于两个类的边缘交界地带。
par(mfcol = c(1 ,2))
plot(clustmodel, which.plots = 2, main = '')
plot(clustmodel, whic 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1883
1883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









