







 本文详细探讨了OkHttp网络请求框架的源码,从初识OkHttp到深入其同步请求流程,尤其关注了OkHttpClient、RealCall、Dispatcher以及拦截器链的各个组件,如重试、缓存、连接池等,是理解OkHttp内部工作机制的重要参考资料。
本文详细探讨了OkHttp网络请求框架的源码,从初识OkHttp到深入其同步请求流程,尤其关注了OkHttpClient、RealCall、Dispatcher以及拦截器链的各个组件,如重试、缓存、连接池等,是理解OkHttp内部工作机制的重要参考资料。
OkHttp是一个非常优秀的网络请求框架,已被谷歌加入到Android的源码中。目前比较流行的Retrofit也是默认使用OkHttp的。所以OkHttp的源码是一个不容错过的学习资源,学习源码之前,务必熟练使用这个框架,否则就是跟自己过不去。
use -> running source code -> reading & learning the source code.
1、初识
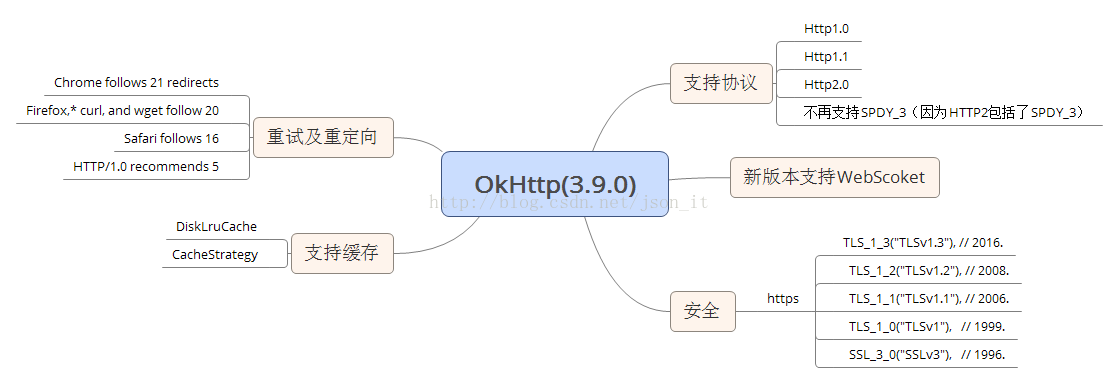
在早期的版本中,OkHttp支持Http1.0,1.1,SPDY协议,但是Http2协议的问世,导致OkHttp也做出了改变,OkHttp鼓励开发者使用HTTP2,不再对SPDY协议给予支持。另外,新版本的OkHttp还有一个新的亮点就是支持WebScoket,这样我们就可以非常方便的建立长连接了。
关于Http各个版本的异同,可以查看这篇博客:http://blog.csdn.net/json_it/article/details/78312311
作为一个优秀的网络框架,OkHttp同样支持网络缓存,OkHttp的缓存基于DiskLruCache,对这个类不熟悉的可以
这里学习。DiskLruCache虽然没有被收入到Android的源码中,但也是谷歌推荐的一个优秀的缓存框架。有时间可以自己学习源码,这里不再叙述。
在安全方便,OkHttp目前支持了如上图所示的TLS版本,以确保一个安全的Socket连接。
重试及重定向就不再说了,都知道什么意思,左上角给出了各浏览器或Http版本支持的重试或重定向次数。
2、流程(以同步请求为例)
2.1、基本使用
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder().url("http://www.baidu.com")
.build();
try {
Response response = client.newCall(request).execute();
if (response.isSuccessful()) {
System.out.println("成功");
}
} catch (IOException e) {
e.printStackTrace();
}2.2、同步请求流程
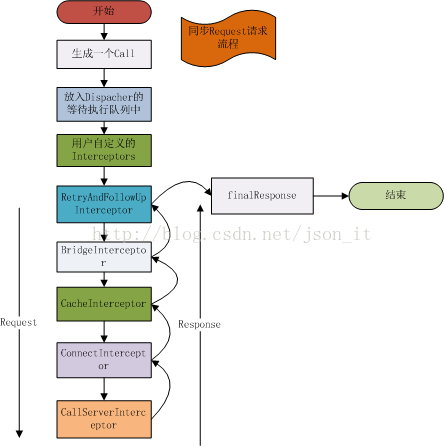
在开始流程讲解之前,先了解一下三个概念的含义(以下来自源码注释):
Connections:连接远程服务器的物理连接;
Streams:基于Connection的逻辑Http请求/响应对。一个连接可以承载多少个Stream都是有限制的,Http1.x连接只能承载一个Stream,而一个Http2.0连接可以承载多个Stream(支持并发请求,并发请求共用一个Connection);
Calls:逻辑Stream序列,典型的例子是一个初始请求及其后续的请求。We prefer to keep all streams of a single call on the same connection for better behavior and locality.
对于同步和异步请求,唯一的区别就是异步请求会放在线程池(ThreadPoolExecutor)中去执行,而同步请求则会在当前线程中执行,注意:同步请求会阻塞当前线程。
对于Http1.1,call - 1:1 - Stream - 1:1 - connection;
对于http2.0,call - 1:1 - Stream - N:1 - connection;
由上述流程图,我们可以直观的了解到一次基本的请求包括如下两个部分:call+interceptors。
call:最终的请求对象;
interceptors:这是OkHttp最核心的部分,一个请求会经过OkHttp的若干个拦截器进行处理,每一个拦截器都会完成一个功能模块,比如CacheInterceptor完成网络请求的缓存。一个Request经过拦截器链的处理之后,会得到最终的Response。
interceptors里面包括的东西很多东西,后续的源码分析就是以拦截器为主线来进行分析。
3、源码分析
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder().url("http://www.baidu.com")
.build();
try {
Response response = client.newCall(request).execute();
if (response.isSuccessful()) {
System.out.println("成功");
}
} catch (IOException e) {
e.printStackTrace();
}3.1、OkHttpClient
首先,我们生成了一个OKHttpClient对象,注意OKHttpClient对象的生成有两种方式:一种是我们使用的方式,另一种是使用建造者(Builder)模式 -- new OkHttpClient.Builder()....Build()。那么这两种方式有什么区别呢?
第一种:
public OkHttpClient() {
this(new Builder());
}
public Builder() {
dispatcher = new Dispatcher();
protocols = DEFAULT_PROTOCOLS;
connectionSpecs = DEFAULT_CONNECTION_SPECS;
eventListenerFactory = EventListener.factory(EventListener.NONE);
proxySelector = ProxySelector.getDefault();
cookieJar = CookieJar.NO_COOKIES;
socketFactory = SocketFactory.getDefault();
hostnameVerifier = OkHostnameVerifier.INSTANCE;
certificatePinner = CertificatePinner.DEFAULT;
proxyAuthenticator = Authenticator.NONE;
authenticator = Authenticator.NONE;
connectionPool = new ConnectionPool();
dns = Dns.SYSTEM;
followSslRedirects = true;
followRedirects = true;
retryOnConnectionFailure = true;
connectTimeout = 10_000;
readTimeout = 10_000;
writeTimeout = 10_000;
pingInterval = 0;
}
dispatcher:直译就是调度器的意思。主要作用是通过双端队列保存Calls(同步&异步Call),同时在线程池中执行异步请求。后面会详细解析该类。
protocols:默认支持的Http协议版本 -- Protocol.HTTP_2, Protocol.HTTP_1_1;
connectionSpecs:OKHttp连接(Connection)配置 -- ConnectionSpec.MODERN_TLS, ConnectionSpec.CLEARTEXT,我们分别看一下:
/** TLS 连接 */
public static final ConnectionSpec MODERN_TLS = new Builder(true)
.cipherSuites(APPROVED_CIPHER_SUITES)
.tlsVersions(TlsVersion.TLS_1_3, TlsVersion.TLS_1_2, TlsVersion.TLS_1_1, TlsVersion.TLS_1_0)
.supportsTlsExtensions(true)
.build();
/** 未加密、未认证的Http连接. */
public static final ConnectionSpec CLEARTEXT = new Builder(false).build();
eventListenerFactory :一个Call的状态监听器,注意这个是okhttp新添加的功能,目前还不是最终版,在后面的版本中会发生改变的。
proxySelector :使用默认的代理选择器;
cookieJar:默认是没有Cookie的;
socketFactory:使用默认的Socket工厂产生Socket;
hostnameVerifier、 certificatePinner、 proxyAuthenticator、 authenticator:安全相关的设置;
connectionPool :连接池;后面会详细介绍;
dns:这个一看就知道,域名解析系统 domain name -> ip address;
pingInterval :这个就和WebSocket有关了。为了保持长连接,我们必须间隔一段时间发送一个ping指令进行保活;
第二种:默认的设置和第一种方式相同,但是我们可以利用建造者模式单独的设置每一个属性;
注意事项:OkHttpClient强烈建议全局单例使用,因为每一个OkHttpClient都有自己单独的连接池和线程池,复用连接池和线程池能够减少延迟、节省内存。
3.2、RealCall(生成一个Call)
在我们定义了请求对象request之后,我们需要生成一个Call对象,该对象代表了一个准备被执行的请求。Call是可以被取消的。Call对象代表了一个request/response 对(Stream).还有就是一个Call只能被执行一次。执行同步请求,代码如下(RealCall的execute方法):
@Override public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
try {
client.dispatcher().executed(this);
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
client.dispatcher().finished(this);
}
}
解析:首先如果executed等于true,说明已经被执行,如果再次调用执行就抛出异常。这说明了一个Call只能被执行。注意此处同步请求与异步请求生成的Call对象的区别,执行
异步请求代码如下(RealCall的enqueue方法):
@Override public void enqueue(Callback responseCallback) {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
接着上面继续分析,如果可以执行,则对当前请求添加监听器等操作,然后将请求Call对象放入调度器Dispatcher中。最后由拦截器链中的各个拦截器来对该请求进行处理,返回最终的Response。
3.3、Dispatcher(调度器)
Dispatcher是保存同步和异步Call的地方,并负责执行异步AsyncCall。
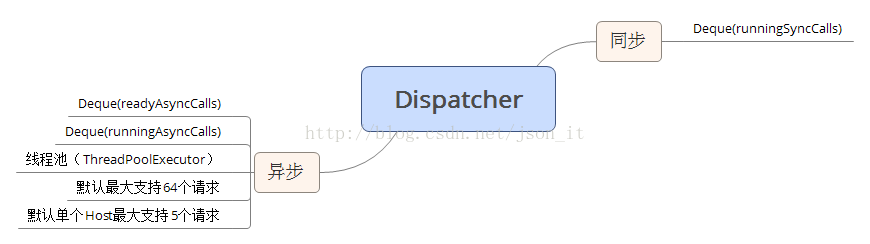
如上图,针对同步请求,Dispatcher使用了一个Deque保存了同步任务;针对异步请求,Dispatcher使用了两个Deque,一个保存准备执行的请求,一个保存正在执行的请求,为什么要用两个呢?因为Dispatcher默认支持最大的并发请求是64个,单个Host最多执行5个并发请求,如果超过,则Call会先被放入到readyAsyncCall中,当出现空闲的线程时,再将readyAsyncCall中的线程移入到runningAsynCalls中,执行请求。先看Dispatcher的流程,跟着流程读源码:
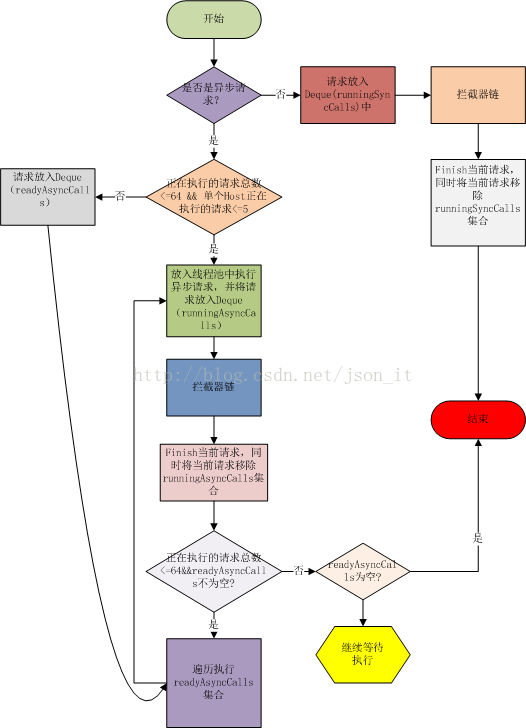
在3.2小节中,当一个请求是同步请求的请求的,可以看到执行了这句代码:client.dispatcher().executed(this);根据Dispatcher源码,看一下到底发生了什么?
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}
在经过拦截器的处理之后,得到了响应的Response,最终会执行finally语句块:
void finished(RealCall call) {
finished(runningSyncCalls, call, false);
}
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");//将请求移除集合
if (promoteCalls) promoteCalls();
...
}
...
}
Dispatcher中,同步请求的逻辑还是比较简单的。异步请求的逻辑相对麻烦一些,但也不是很复杂。
在3.2小节,第二处代码是执行异步请求的逻辑,最关键的是最后依据代码:client.dispatcher().enqueue(new AsyncCall(responseCallback));紧跟着看一下enqueue方法中到底发生了什么:
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
} @Override protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain();//拦截器链
if (retryAndFollowUpInterceptor.isCanceled()) {//重试失败,回调onFailure方法
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCal 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









