






Python爬虫案例--- 王者荣耀英雄主页图片爬取
***跟着小库老师学python***
王者荣耀英雄连招视频数据爬取:
目标网址:https://pvp.qq.com/web201605/herolist.shtml
1.爬取王者荣耀所有英雄主页背景图片。
2.保存本地!一、爬虫项目步骤:
1. 找数据对应的地址
分析网页性质<静态网页/动态网页>
通过开发者工具找地址
2. 模拟请求, 得到地址返回的数据
3. 数据提取
4. 保存数据
-----------------------------------------
通过https://pvp.qq.com/web201605/herolist.shtml
获取每个英雄的详情页地址 ---> 通过详情页地址 ---> 获得英雄主页图片 ---> 在保存本地二、项目实现:
1.找数据分析对应地址 ----- 分析网页性质<静态地址 / 动态地址>
通过F12我们可以观察到,网页数据的存储样式。
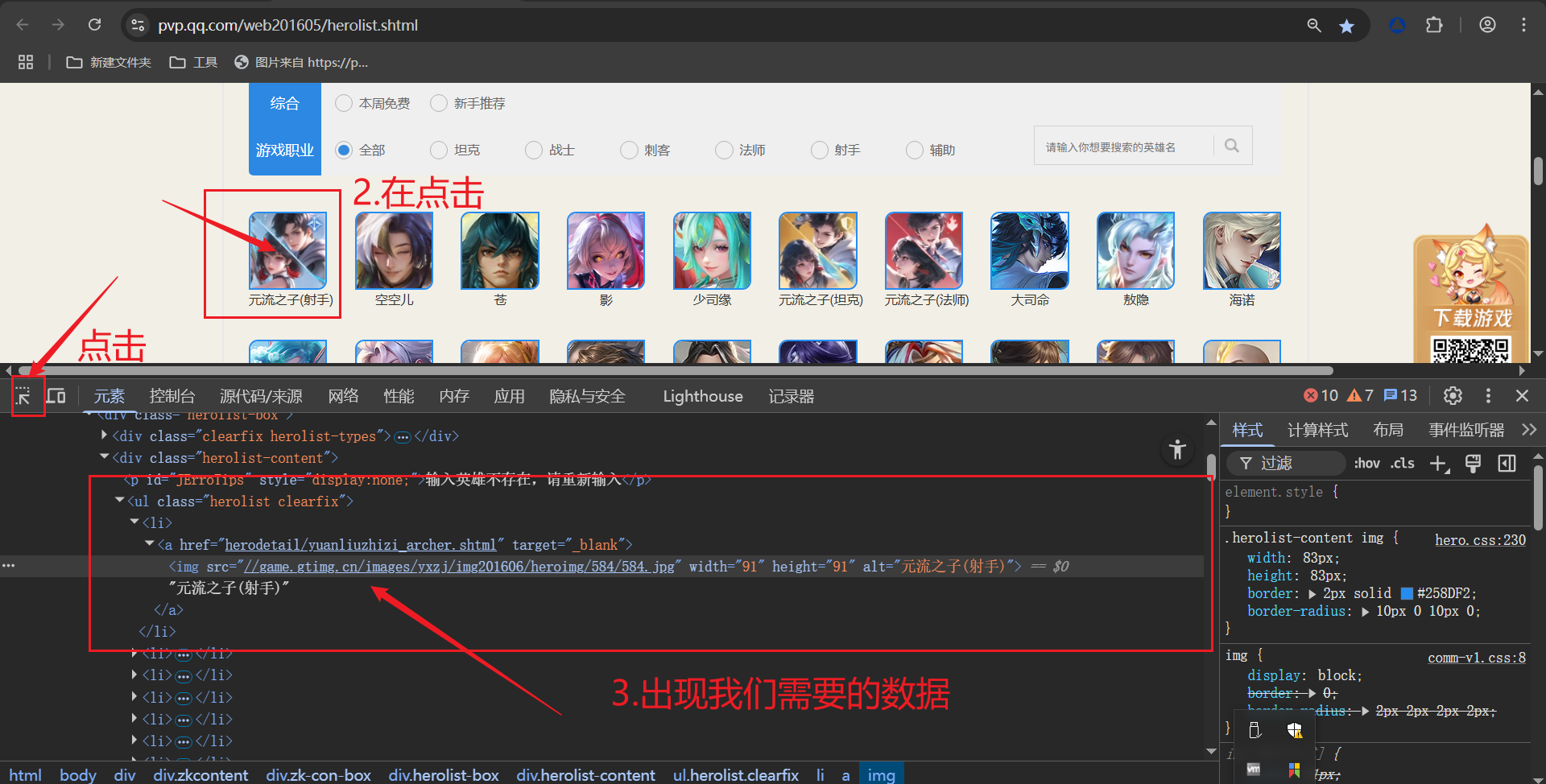
通过我们以上3个步骤,可以分析出网页是静态地址,我们通过对英雄资料列表页-英雄介绍-王者荣耀官方网站-腾讯游戏进行发送请求,就可以获取响应数据,可以获得a标下的href属性,里面的部分地址就是每个英雄的详情页地址,在进行拼接。请求详情页地址,获取英雄视频。
2.模拟请求, 得到地址返回的数据
# 构建请求地址
url = 'https://pvp.qq.com/web201605/herolist.shtml'
# 构建请求头
headers = {
'authority': 'pvp.qq.com',
'cookie': 'RK=IgvApl1vXH; ptcz=1e8c2bd3121cd84466bc72c220ee927b2e51ff79d20e48ab58ce06b00d27dd50; qq_domain_video_guid_verify=37b40fce745a5fcc; _qimei_uuid42=194160c0528100f382d74962bb18a56dd35a847462; _qimei_q36=; _qimei_h38=e147e2f782d74962bb18a56d02000006319416; pgv_pvid=575201997; tvfe_boss_uuid=91932577be73fa6c; PTTuserFirstTime=1746316800000; PTTosSysFirstTime=1746316800000; PTTosFirstTime=1746316800000; ts_refer=www.baidu.com/link; ts_uid=7155029640; eas_sid=KGrJR7YaCsRRxSrk6Et1Fp4ATe; isHostDate=20229; isOsSysDate=20229; isOsDate=20229; pgv_info=ssid=s1030317722; weekloop=0-19-0-21; eas_entry=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DtaKRMa9ChYdniiE2bHWxBlzo6P0sNHeH_AdSLPlL4ZS%26wd%3D%26eqid%3D88349544000ccf7100000002682d8b2f; _qimei_fingerprint=028b7fa18ed5105d5b39de5290ba5d91; ieg_ingame_userid=hTQZMZEUF6bNKbTxAHnfZPFTKIo9DRUx; ts_last=pvp.qq.com/v/detail.shtml; pvpqqcomrouteLine=index_herolist_herodetail_videoDetail; tokenParams=%3FG_Biz%3D18%26tid%3D902409; PTTDate=1747815251305',
'referer': 'https://pvp.qq.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
}
# 发送请求,获取响应数据 --> 2. 模拟请求, 得到地址返回的数据
html = requests.get(url=url, headers=headers)
html.encoding = 'gbk' # 设置字体
html_data = html.text
# print(html_data)通过请求地址,返回数据发现网页数据字体编码有问题,手动设置字体编码:html.encoding = 'gbk' # 设置字体。不知道字体编码,可以在网页中查看字体编码。

可以获取到响应数据,HTML数据。我们通过获取到的数据,进行数据分析。
3. 数据提取,解析数据
3.1 获取详情页地址
我们通过导入parsel库(用 pip install parsel安装库),用parsel库对我们提取到的HTML数据进行解析。首先获取每一个一个英雄的详情页对应的url 地址,在获得对应英雄名字。如下图所示,通过对网页的分析可以,得到具体网页对应的地址。
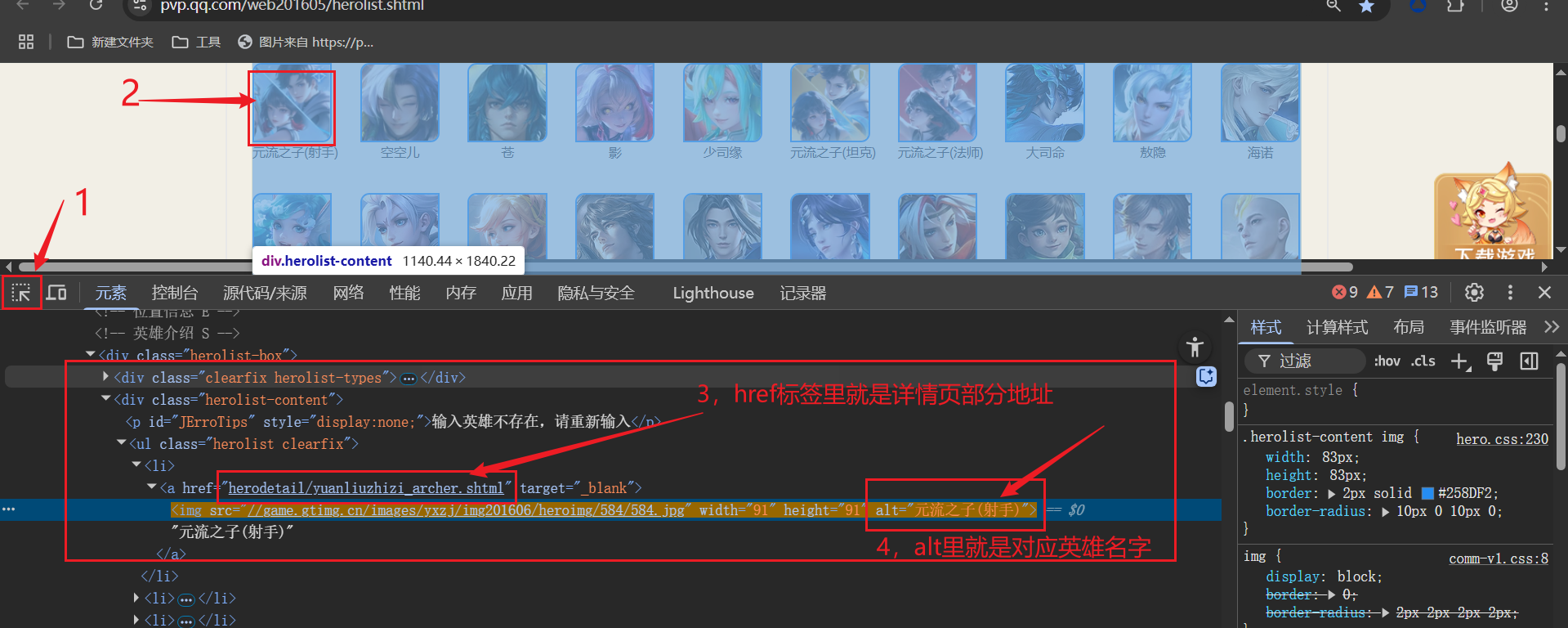
通过上面的四个步骤,你已经定位了,具体网页的URL地址,接下来只需要通过代码获取下来,我们通过parsel进行css检索。F12打开搜索,通过标签一级一级获取,标签,就可以得到详情页地址URL
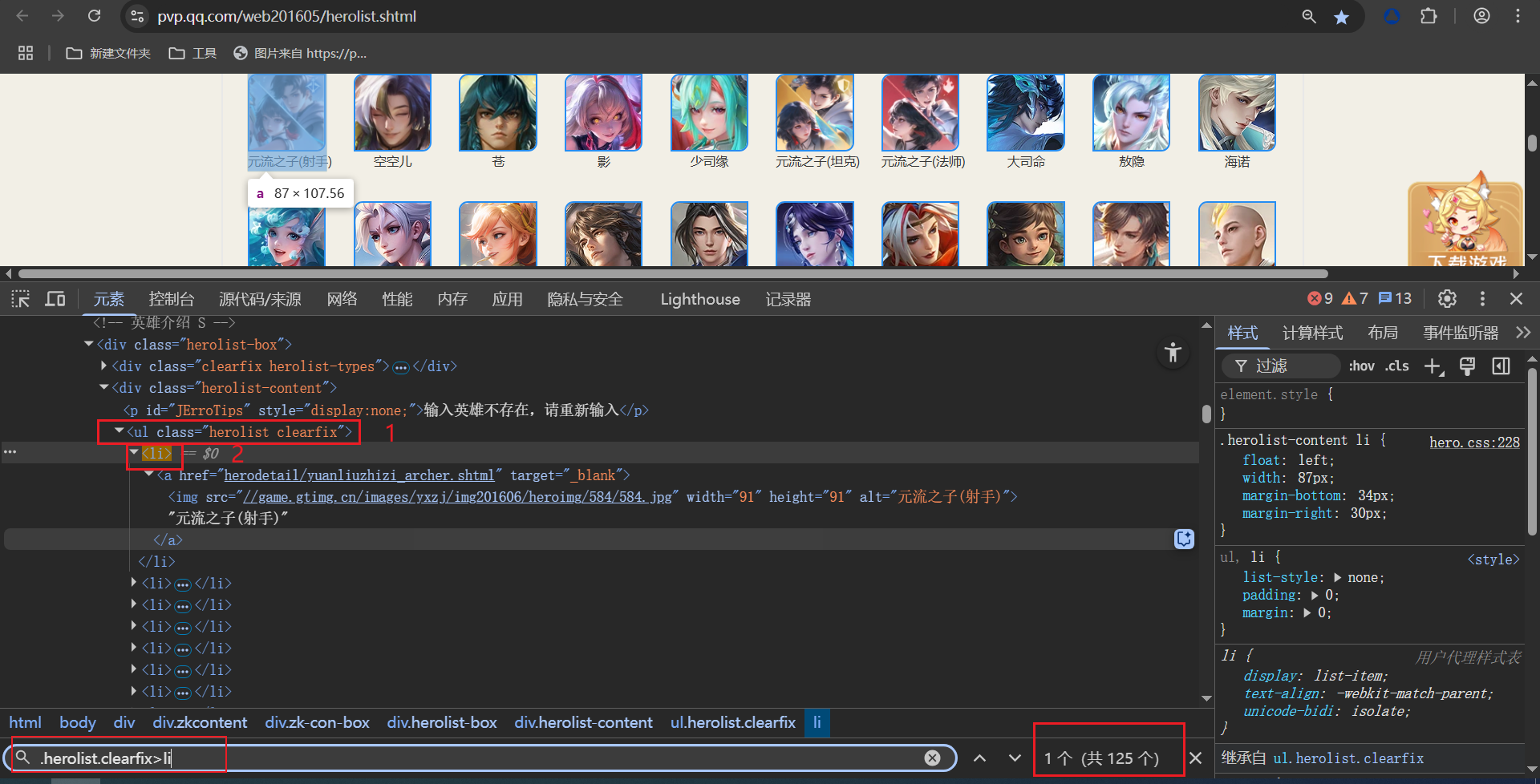
打开F12,通过前面的步骤我们已经确定好了,我们所需要的数据位置,接下来我们通过CSS语法来定位数据位置。选择父级标签.herolist.clearfix>li 我们可以看见每一个英雄的数据都是以列表的方式呈现。注意:.herolist clearfix复制过来中间会有空格,我们需要将空格,替换英文状态下的.这样才可以定位到我们需要的数据。
我们将通过两次筛选,最终获得我们需要的数据。第一次筛选我们将获得所有游戏的列表,在通过for遍历,第二次获取具体数据。代码实现如下:
# 3.数据提取 抓换数据 -->然后利用CSS语法 ---> 分析数据
select = parsel.Selector(html_data)
# 数据第一次提取
lis = select.css('.herolist.clearfix>li')
# 第二次提取
for li in lis:
name = li.css('a>img::attr(alt)').getall()[0]
info_url = li.css('a::attr(href)').getall()[0] # 获得详细界面部分地址,
info_url = 'https://pvp.qq.com/web201605/' + info_url # 拼接完整地址
print(name, info_url)因为我们获取到的地址,只有一部分,我们通过网页点击英雄进入,详情页,在浏览器获取完整地址:王者荣耀元流之子(射手)-王者荣耀官网网站-腾讯游戏在进行拼接。
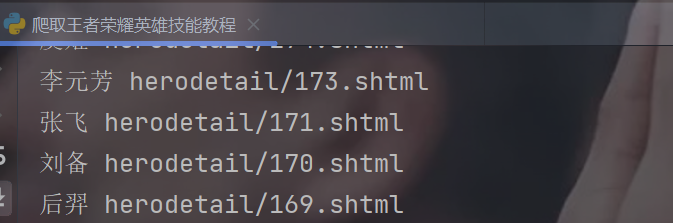
3.2 请求详情页地址,获取响应数据
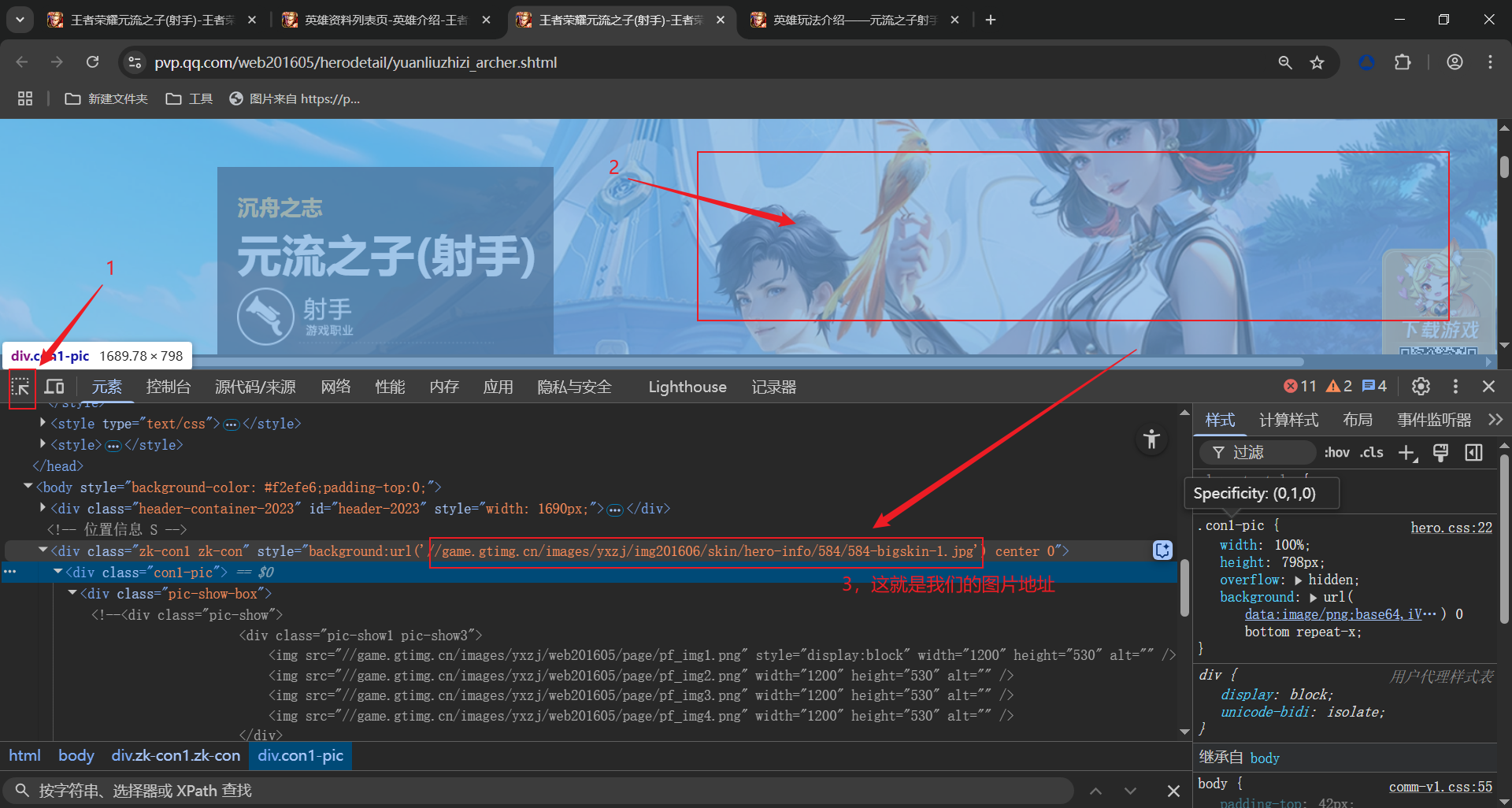
我们通过在浏览器点击进入,详情页后。我们就可以发现视频位置。F12通过下面的三个步骤,你就可以发现图片的地址,重复上面的CSS语法原理,我们就可以得图片的部分地址,最后进行拼接就可以获得完整地址。具体如下:
# 请求详情页数据
info = requests.get(url=info_url, headers=headers)
info.encoding = 'gbk'
info_data = info.text
# 数据转换
select2 = parsel.Selector(info_data)
jpg_data = select2.css('.zk-con1.zk-con::attr(style)').getall()[0]
# print(jpg_data)
# 获取到的数据:background:url('//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/506/506-bigskin-1.jpg') center 0
# 我们通过分割提取我们需要的
jpg_url = jpg_data.split("'")[1]
jpg_url_data = 'https:' + jpg_url # 拼接图片地址
print(jpg_url_data)这样就可以获得我们的完整图片地址,接下来就可以保存本地。
4.数据保存
# 4. 保存数据
with open(f'图片/{name}.png', mode='wb') as f:
# 对图片地址发送请求,以二进制方式保存
png_data = requests.get(url=jpg_url_data, headers=headers).content
f.write(png_data)
print(f'{name}图片保存成功!')这样数据就成功保存本地。注意:这里你需要自己创建一个保存图片的文件夹 with open(f'图片/{name}.png', mode='wb') as f: 将里面的图片文件夹,替换为你自己的。
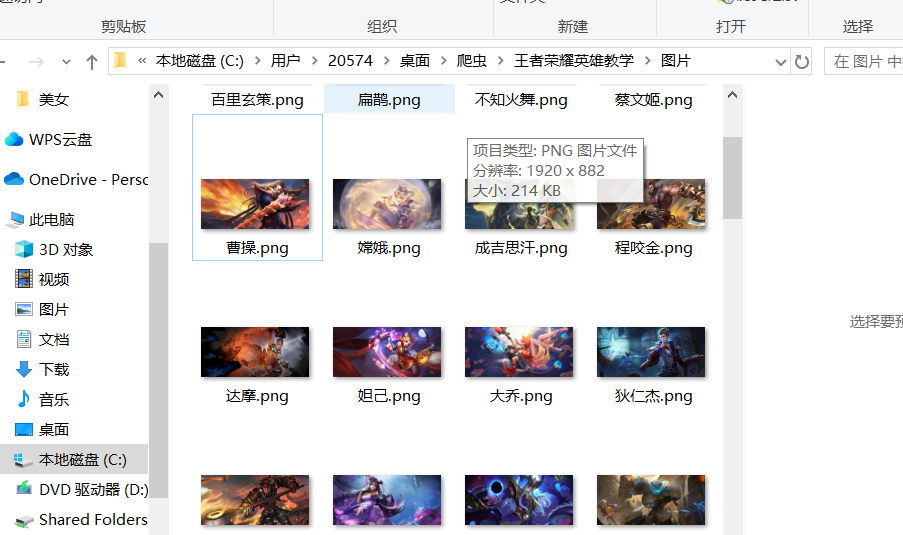
经过上面的步骤,你就可以获取到你想要的所有英雄的图片。
以上仅供参考,转载表面作者出处。
完整代码如下:
import parsel
import requests
# 构建请求地址
url = 'https://pvp.qq.com/web201605/herolist.shtml'
# 构建请求头
headers = {
'authority': 'pvp.qq.com',
'cookie': 'RK=IgvApl1vXH; ptcz=1e8c2bd3121cd84466bc72c220ee927b2e51ff79d20e48ab58ce06b00d27dd50; qq_domain_video_guid_verify=37b40fce745a5fcc; _qimei_uuid42=194160c0528100f382d74962bb18a56dd35a847462; _qimei_q36=; _qimei_h38=e147e2f782d74962bb18a56d02000006319416; pgv_pvid=575201997; tvfe_boss_uuid=91932577be73fa6c; PTTuserFirstTime=1746316800000; PTTosSysFirstTime=1746316800000; PTTosFirstTime=1746316800000; ts_refer=www.baidu.com/link; ts_uid=7155029640; eas_sid=KGrJR7YaCsRRxSrk6Et1Fp4ATe; isHostDate=20229; isOsSysDate=20229; isOsDate=20229; pgv_info=ssid=s1030317722; weekloop=0-19-0-21; eas_entry=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DtaKRMa9ChYdniiE2bHWxBlzo6P0sNHeH_AdSLPlL4ZS%26wd%3D%26eqid%3D88349544000ccf7100000002682d8b2f; _qimei_fingerprint=028b7fa18ed5105d5b39de5290ba5d91; ieg_ingame_userid=hTQZMZEUF6bNKbTxAHnfZPFTKIo9DRUx; ts_last=pvp.qq.com/v/detail.shtml; pvpqqcomrouteLine=index_herolist_herodetail_videoDetail; tokenParams=%3FG_Biz%3D18%26tid%3D902409; PTTDate=1747815251305',
'referer': 'https://pvp.qq.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
}
# 发送请求,获取响应数据 --> 2. 模拟请求, 得到地址返回的数据
html = requests.get(url=url, headers=headers)
html.encoding = 'gbk' # 设置字体
html_data = html.text
# print(html_data)
# 3.数据提取 抓换数据 -->然后利用CSS语法 ---> 分析数据
select = parsel.Selector(html_data)
# 数据第一次提取
lis = select.css('.herolist.clearfix>li')
# 第二次提取
for li in lis:
name = li.css('a>img::attr(alt)').getall()[0]
info_url = li.css('a::attr(href)').getall()[0] # 获得详细界面部分地址,
info_url = 'https://pvp.qq.com/web201605/' + info_url # 拼接完整地址
# print(name, info_url)
# 请求详情页数据
info = requests.get(url=info_url, headers=headers)
info.encoding = 'gbk'
info_data = info.text
# 数据转换
select2 = parsel.Selector(info_data)
jpg_data = select2.css('.zk-con1.zk-con::attr(style)').getall()[0]
# print(jpg_data)
# 获取到的数据:background:url('//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/506/506-bigskin-1.jpg') center 0
# 我们通过分割提取我们需要的
jpg_url = jpg_data.split("'")[1]
jpg_url_data = 'https:' + jpg_url # 拼接图片地址
# print(jpg_url_data)
# 4. 保存数据
with open(f'图片/{name}.png', mode='wb') as f:
# 对图片地址发送请求,以二进制方式保存
png_data = requests.get(url=jpg_url_data, headers=headers).content
f.write(png_data)
print(f'{name}图片保存成功!')
















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









