







 本文介绍了使用Python爬虫抓取BOSS直聘上的职位描述信息,详细讲解了如何分析详情页、使用requests和BeautifulSoup库,以及数据清洗过程,包括校正发布日期、处理薪水信息和划分工作经验等级等。此外,还讨论了职位职责与任职要求的划分难题,并分享了项目开源地址。
本文介绍了使用Python爬虫抓取BOSS直聘上的职位描述信息,详细讲解了如何分析详情页、使用requests和BeautifulSoup库,以及数据清洗过程,包括校正发布日期、处理薪水信息和划分工作经验等级等。此外,还讨论了职位职责与任职要求的划分难题,并分享了项目开源地址。
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
零、致谢
感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅。
由于爬虫持续爬取 www.zhipin.com 网站,以致产生的服务器压力,本人深感歉意,并没有 DDoS 和危害贵网站的意思。
2017-12-14 更新
在跑了一夜之后,服务器 IP 还是被封了,搞得本人现在家里、公司、云服务器三线作战啊
一、抓取详细的职位描述信息
1.1 前提数据
这里需要知道页面的 id 才能生成详细的链接,在 Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息 中,我们已经拿到招聘信息的大部分信息,里面有个 pid 字段就是用来唯一区分某条招聘,并用来拼凑详细链接的。
是吧,明眼人一眼就看出来了。
1.2 详情页分析
详情页如下图所示
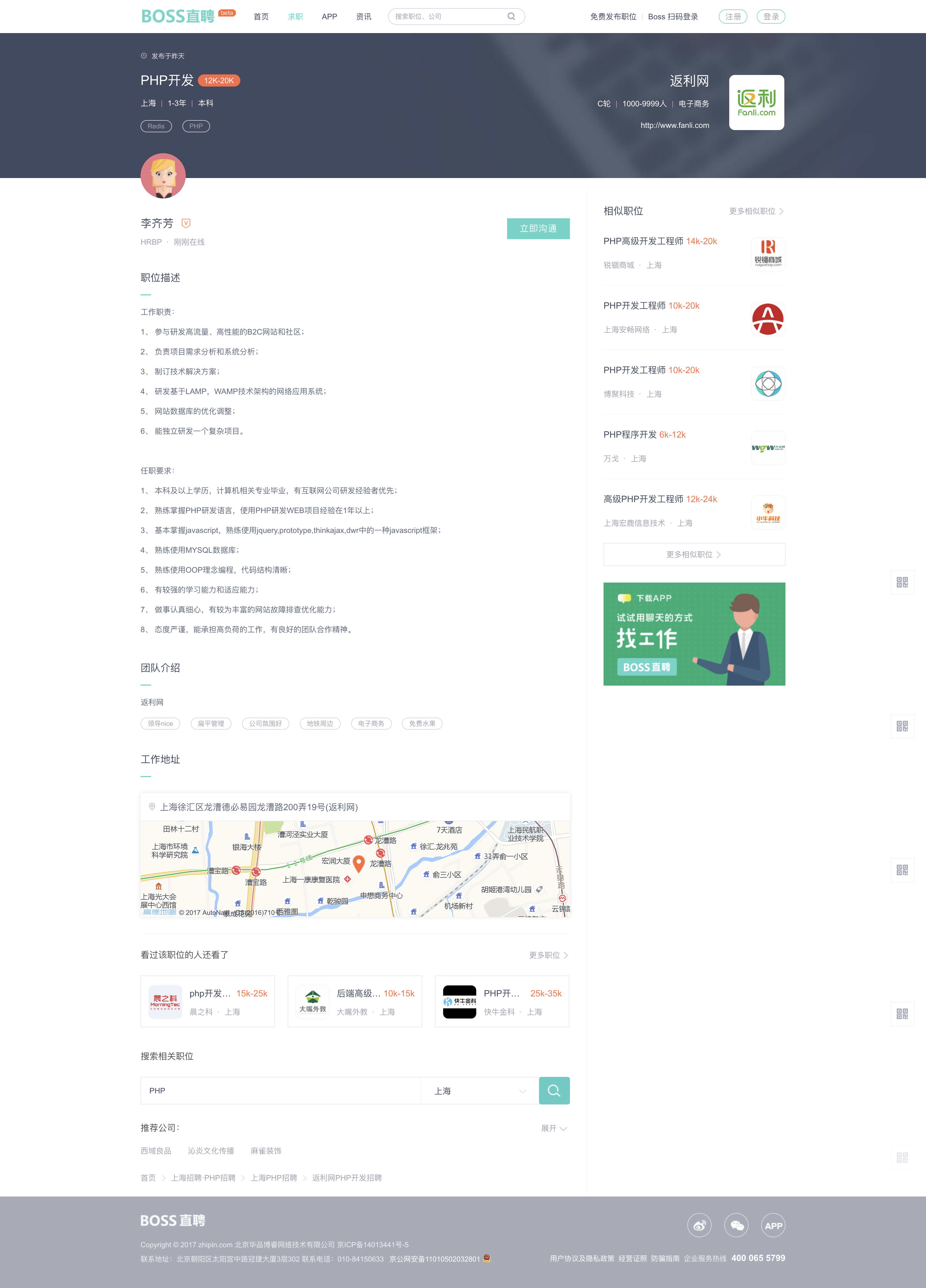
在详情页中,比较重要的就是职位描述和工作地址这两个
由于在页面代码中岗位职责和任职要求是在一个 div 中的,所以在抓的时候就不太好分,后续需要把这个连体婴儿,分开分析。
1.3 爬虫用到的库
使用的库有
- requests
- BeautifulSoup4
- pymongo
对应的安装文档依次如下,就不细说了
1.4 Python 代码
"""
@author: jtahstu
@contact: root@jtahstu.com
@site: http://www.jtahstu.com
@time: 2017/12/10 00:25
"""
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
from pymongo import MongoClient
headers = {
'x-devtools-emulate-network-conditions-client-id': "5f2fc4da-c727-43c0-aad4-37fce8e3ff39",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'dnt': "1",
'accept-encoding': "gzip, deflate",
'accept-language': "zh-CN,zh;q=0.8,en;q=0.6",
'cookie': "__c=1501326829; lastCity=101020100; __g=-; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l=%2F; __a=38940428.1501326829..1501326829.20.1.20.20; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502948718; __c=1501326829; lastCity=101020100; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502954829; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l=%2F; __a=38940428.1501326829..1501326829.21.1.21.21",
'cache-control': "no-cache",
'postman-token': "76554687-c4df-0c17-7cc0-5bf3845c983 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









