







 本文详细解析了Word2Vec模型的训练流程,包括词汇如何在多个线程中迭代处理,以及神经网络训练过程中词向量的计算与更新机制。探讨了通过Huffman树进行概率计算的方法,解释了sigmoid函数的离散化处理方式。
本文详细解析了Word2Vec模型的训练流程,包括词汇如何在多个线程中迭代处理,以及神经网络训练过程中词向量的计算与更新机制。探讨了通过Huffman树进行概率计算的方法,解释了sigmoid函数的离散化处理方式。
1. TrainModelTread的流程图
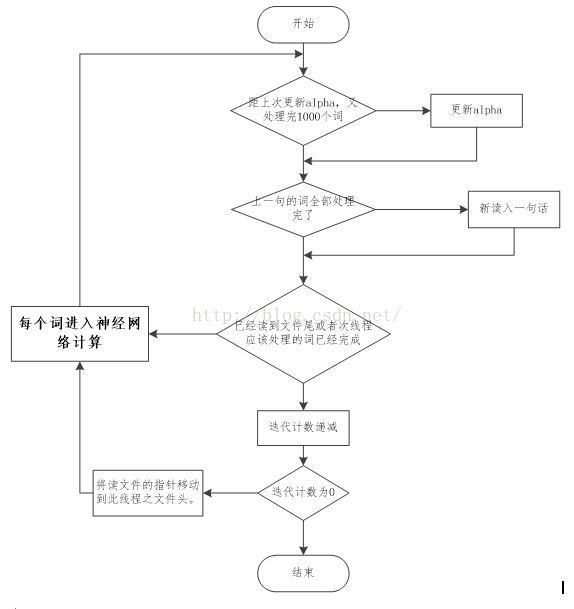
总的来说是这样的:
(1).所有训练集中的词被等分成n份(n为线程数),所有的词都会迭代5次(5次是默认值,这个可以在参数中设置),因此,每个线程会反复读5次自己管辖内的词。
(2).每次按照句子来读入词,一次读入一句,一句读入后,逐个词进入神经网络训练。等这句话的所有词都训练完成后,再读入下一句。
(3).当读到线程管辖文件尾时,迭代计数器自减,如果减为0了,则跳出最外层循环,整个训练结束;如果还没有减到0,则将读文件的指针移到线程管辖文件的头部。重新开始下一次迭代。
(4).每处理10000个词,就需要更新1次alpha。
(5). 逐个词进入神经网络训练,虽然设置了window,但是,并不是5个词进行一次神经网络训练,而是在in->hidden做向量累加时,随机计算窗口量,窗口数量有window这么多种(3-11个之间),以当前输入词为中心,累加其前后的词的向量。
(窗口大小随机,但有范围,以当前词为中心,(除最开始,和最末尾))。
2. 神经网络对应程序推导
以下推导是根据神经网络中主要的算式为主线,红色为其后备推导过程,以此来分析整个神经网络。
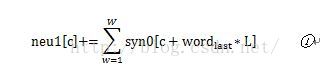
这里,首先,在intiNet()定义syn0是一个V*L维度的大矩阵,L为每个词的向量维度。它存的是vocab中所有词的L维的向量,已经给此矩阵负了随机初始值。Word是词在vocab中的位置。
在上一节提到,在做in->hidden的累加时,词窗口大小是随机的。这里neu1[c]就是窗口中词的向量累加。(c为维度计数,L范围内循环,W为窗口词个数)。
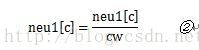
cw是窗口中词的数量,这里相当于是把做成平均值。
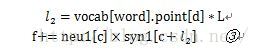
其中piont为词在huffman树中到根结点的路径,point[d]是其往上推的第d个父结点。这个内积和为其自身向量与各父结点的内积和,取这样一个内积和的好处目前还没有搞清楚。
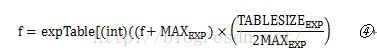
这是求f的sigmoid函数输出。这里没有直接计算,而是换成了查表的方式,应该是为了加快速度。但是查表就意味着把这个函数离散化了,就会存在离散误差。这里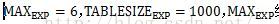
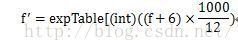
这个公式怎么就是sigmoid函数了呢?
首先来看看,
for (i = 0; i < EXP_TABLE_SIZE; i++) {
expTable[i] = exp((i / (real)EXP_TABLE_SIZE * 2 - 1) * MAX_EXP); // Precompute the exp() table
expTable[i] = expTable[i] / (expTable[i] + 1); // Precompute f(x) = x / (x + 1)
}也就是
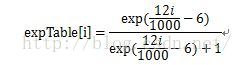
再来看看sigmoid函数的定义
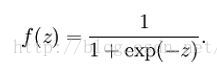
其取值范围为(0,1)。可转化为
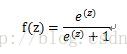
那么
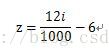
i的范围(0,1000),z的范围为(-6,6),离散化后步长为12/1000。
那么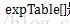
接下来令P=(f+6)*1000/12,f取值范围(-6,6),P的取值范围正好是(0,1000),覆盖表中所有的元素。
因此,④就是sigmoid函数的离散化形式。

code是父结点的标签,1为右结点,0为左结点。d依然是往上推的第d个父结点。这是梯度计算公式。由于0<f<1,>0,这样的话,父结点为左结点对应的梯度为正,为右结点的梯度为负。
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c];更新向量。Neu1e[],每个词的向量误差为各父结点各次迭代向量乘梯度的和。然后把父结点的向量叠加到该词当前向量值中,实际上,向量误差就是自己前面d次迭代出来的向量参数乘梯度。
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c];
}把误差叠加到每个词的向量当中。这个误差实际上是各父结点的向量乘梯度,包含了该父结点所有叶子结点的向量,因此,不但同一个父结点下来的两个子结点有关联了,连与叶子结点出现在同一个句子,且位置相近的词也关联起来了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









