






最近在用 C 做项目,之前用惯了 C++ ,转回头来用C 还真有点不适应。 C++ 语言中自带面向对象支持,如封装、继承、多态等面向对象的基本特征。 C 原本是面向过程的语言,自身没有内建这些特性,但我们还是可以利用 C 语言本身已有的特性来实现面向对象的一些基本特征。接下来我们就一一来细说封装、继承、多态、纯虚类等面向对象特性在 C 语言中如何实现,并且给出实例。
这篇文章中我们先说封装和继承。
先来看封装。
所谓封装,通俗地说,就是一个姑娘化了妆,只给你看她想让你看的那一面,至于里面是否刮了骨、垫了东西,不给你看。说到封装就得说隐藏,这是对兄弟概念;其实我理解隐藏是更深的封装,完全不给你看见,而封装可能是犹抱琵琶半遮面。封装在 C++ 语言中有 protected 、 private 关键字在语言层面上支持,而 C 语言中没有这些。 C 有结构体( struct ),其实可以实现封装和隐藏。
在 QT 中,为了更好的隐藏一个类的具体实现,一般是一个公开头文件、一个私有头文件,私有头文件中定义实现的内部细节,公开头文件中定义开放给客户程序员的接口和公共数据。看看 QObject (qobject.h ),对应有一个 QObjectPrivate (qobject_p.h ) ,其他的也类似。而代码框架如下:
- QObject{
- public:
- xxx
- xxx
- private:
- QObjectPrivate * priv;
- };
- struct st_abc_private;
- struct st_abc {
- int a;
- xxx;
- void (*xyz_func)(struct st_abc*);
- struct st_abc_private * priv;
- };
这样做的好处是显而易见的,除了预定义好的接口,客户程序员完全不需要知道实现细节,即便实现经过重构完全重来,客户程序员也不需要关注,甚至相应的模块连重新编译都不要——因为 abc.h 自始至终都没变过。
上面代码有个问题,客户程序员如何得到 struct st_abc 的一个实例,他不知道 struct st_abc_private 如何实现的呀。 C 中没有构造函数,只好我们自己提供了:我们可以在 abc.h 中声明一个类似构造函数的函数来生成 struct st_abc 的实例,名字就叫作 new_abc() ,函数原型如下:
- struct st_abc * new_abc();
- void delete_abc(struct st_abc *);
到现在为止,封装和隐藏就实现了,而且很彻底。接下来看继承。
什么是继承?在面向对象层面上不讲了,只说语法层面。语法层面上讲,继承就是派生类拥有父类的数据、方法,又添了点自己的东西,所谓子承父业,发扬光大。在 C 语言中可以用结构体的包含来实现继承关系。代码框架如下:
- struct st_base{
- xxx;
- };
- struct st_derived{
- struct sb_base base;
- yyy;
- };
继承在语法层面上看,有数据成员、函数,数据成员通过上面的方法自动就“继承”了,至于函数,在结构体表示为函数指针,其实也是一个数据成员,是个指针而已,也会自动“继承”。之所以还要在这里列出来说明,是因为 C++ 中有一个很重要的概念:重载。要在 C 中完整实现有点儿麻烦。
重载,我们常说的重载大概有三种含义:
- 其一,函数重载,指函数名字一样,参数个数、类型不一样的函数声明和实现。由于 C 编译器的缘故,不支持。不过这个影响不大。
- 其二,重定义或者说覆盖,指派生类中定义与基类签名一样(名字、返回值、参数完全一样)的非虚函数,这样派生类的中的函数会覆盖基类的同签名函数,通过成员操作符访问时无法访问基类的同签名函数。
- 其三,虚函数重写,指在派生类中实现基类定义的虚函数或纯虚函数。虚函数是实现多态的关键,可以在结构体中使用函数指针来表达,但要完全实现,也很麻烦。
我们平常在交流时通常不明确区分上面三种类型的重载,这里出于习惯,也不作区分。
好了,第一篇就到这里,有时间会往下续。
在 C 语言面向对象编程(一)里说到继承,这里再详细说一下。
C++ 中的继承,从派生类与基类的关系来看(出于对比 C 与 C++,只说公有继承):
- 派生类内部可以直接使用基类的 public 、protected 成员(包括变量和函数)
- 使用派生类的对象,可以像访问派生类自己的成员一样访问基类的成员
- 对于被派生类覆盖的基类的非虚函数,在派生类中可以通过基类名和域作用符(::)来访问
- 当使用基类指针调用虚函数时,会调用指针指向的实际对象实现的函数,如果该对象未重载该虚函数,则沿继承层次,逐级回溯,直到找到一个实现
先看 C 语言中通过“包含”模拟实现继承的简单代码框架:
- struct base{
- int a;
- };
- struct derived{
- struct base parent;
- int b;
- };
- struct derived_2{
- struct derived parent;
- int b;
- };
上面的示例只有数据成员,函数成员其实是个指针,可以看作数据成员。 C 中的 struct 没有访问控制,默认都是公有访问(与 java 不同)。
下面是带成员函数的结构体:
- struct base {
- int a;
- void (*func1)(struct base *_this);
- };
- struct derived {
- struct base parent;
- int b;
- void (*func2)(struct derived* _this;
- };
为了像 C++ 中一样通过类实例来访问成员函数,必须将结构体内的函数指针的第一个参数定义为自身的指针,在调用时传入函数指针所属的结构体实例。这是因为 C 语言中不存在像 C++ 中那样的 this 指针,如果我们不显式地通过参数提供,那么在函数内部就无法访问结构体实例的其它成员。
下面是在 c 文件中实现的函数:
- static void base_func1(struct base *_this)
- {
- printf("this is base::func1\n");
- }
- static void derived_func2(struct derived *_this)
- {
- printf("this is derived::func2\n");
- }
C++ 的 new 操作符会调用构造函数,对类实例进行初始化。 C 语言中只有 malloc 函数族来分配内存块,我们没有机会来自动初始化结构体的成员,只能自己增加一个函数。如下面这样(略去头文件中的声明语句):
- struct base * new_base()
- {
- struct base * b = malloc(sizeof(struct base));
- b->a = 0;
- b->func1 = base_func1;
- return b;
- }
好的,构造函数有了。通过 new_base() 调用返回的结构体指针,已经可以像类实例一样使用了:
- struct base * b1 = new_base();
- b1->func1(b1);
到这里我们已经知道如何在 C 语言中实现一个基本的“类”了。接下来一一来看前面提到的几点。
第一点,派生类内部可以直接使用基类的 public 、protected 成员(包括变量和函数)。具体到上面的例子,我们可以在 derived_func2 中访问基类 base 的成员 a 和 func1 ,没有任何问题,只不过是显式通过 derived 的第一个成员 parent 来访问:
- static void derived_func2(struct derived *_this)
- {
- printf("this is derived::func2, base::a = %d\n", _this->parent.a);
- _this->parent.func1(&_this->parent);
- }
- struct derived d;
- printf("base::a = %d\n",d.parent.a);
- struct derived *p = new_derived();
- ((struct base *)p)->func1(p);
第三点,对于被派生类覆盖的基类的非虚函数,在派生类中可以通过基类名和域作用符(::)来访问。其实通过前两点,我们已经熟悉了在 C 中访问“基类”成员的方法,总是要通过“派生类”包含的放在结构体第一个位置的基类类型的成员变量来访问。所以在 C 中,严格来讲,实际上不存在覆盖这种情况。即便定义了完全一样的函数指针,也没有关系,因为“包含”这种方式,已经从根本上分割了“基类”和“派生类”的成员,它们不在一个街区,不会冲突。
下面是一个所谓覆盖的例子:
- struct base{
- int a;
- int (*func)(struct base * b);
- };
- struct derived {
- struct base b;
- int (*func)(struct derived *d);
- };
- /* usage */
- struct derived * d = new_derived();
- d->func(d);
- d->b.func((struct base*)d);
第四点,虚函数。虚函数是 C++ 里面最有意义的一个特性,是多态的基础,要想讲明白比较困难,我们接下来专门写一篇文章讲述如何在 C 中实现类似虚函数的效果,实现多态。
回顾一下:
在《 C++ 编程思想》一书中对虚函数的实现机制有详细的描述,一般的编译器通过虚函数表,在编译时插入一段隐藏的代码,保存类型信息和虚函数地址,而在调用时,这段隐藏的代码可以找到和实际对象一致的虚函数实现。
我们在这里提供一个 C 中的实现,模仿 VTABLE 这种机制,但一切都需要我们自己在代码中装配。
之前在网上看到一篇描述 C 语言实现虚函数和多态的文章,谈到在基类中保存派生类的指针、在派生类中保存基类的指针来实现相互调用,保障基类、派生类在使用虚函数时的行为和 C++ 类似。我觉得这种方法有很大的局限性,不说继承层次的问题,单单是在基类中保存派生类指针这一做法,就已经违反了虚函数和多态的本意——多态就是要通过基类接口来使用派生类,如果基类还需要知道派生类的信息……。
我的基本思路是:
- 在“基类”中显式声明一个 void** 成员,作为数组保存基类定义的所有函数指针,同时声明一个 int 类型的成员,指明 void* 数组的长度。
- “基类”定义的每个函数指针在数组中的位置、顺序是固定的,这是约定,必须的
- 每个“派生类”都必须填充基类的函数指针数组(可能要动态增长),没有重写虚函数时,对应位置置 0
- “基类”的函数实现中,遍历函数指针数组,找到继承层次中的最后一个非 0 的函数指针,就是实际应该调用的和对象相对应的函数实现
好了,先来看一点代码:
- struct base {
- void ** vtable;
- int vt_size;
- void (*func_1)(struct base *b);
- int (*func_2)(struct base *b, int x);
- };
- struct derived {
- struct base b;
- int i;
- };
- struct derived_2{
- struct derived d;
- char *name;
- };
注意,derived 和 derived_2 并没有定义 func_1 和 func_2 。在 C 的虚函数实现中,如果派生类要重写虚函数,不需要在派生类中显式声明。要做的是,在实现文件中实现你要重写的函数,在构造函数中把重写的函数填入虚函数表。
我们面临一个问题,派生类不知道基类的函数实现在什么地方(从高内聚、低耦合的原则来看),在构造派生类实例时,如何初始化虚函数表?在 C++ 中编译器会自动调用继承层次上所有父(祖先)类的构造函数,也可以显式在派生类的构造函数的初始化列表中调用基类的构造函数。怎么办?
我们提供一个不那么优雅的解决办法:
每个类在实现时,都提供两个函数,一个构造函数,一个初始化函数,前者用户生成一个类,后者用于继承层次紧接自己的类来调用以便正确初始化虚函数表。依据这样的原则,一个派生类,只需要调用直接基类的初始化函数即可,每个派生类都保证这一点,一切都可以进行下去。
下面是要实现的两个函数:
- struct derived *new_derived();
- void initialize_derived(struct derived *d);
- struct derived *new_derived()
- {
- struct derived * d = malloc(sizeof(struct derived));
- initialize_base((struct base*)d);
- initialize_derived(d);/* setup or modify VTABLE */
- return d;
- }
说完了构造函数,对应的要说析构函数,而且析构函数要是虚函数。在删除一个对象时,需要从派生类的析构函数依次调用到继承层次最顶层的基类的析构函数。这点在 C 中也是可以保障的。做法是:给基类显式声明一个析构函数,基类的实现中查找虚函数表,从后往前调用即可。函数声明如下:
- struct base {
- void ** vtable;
- int vt_size;
- void (*func_1)(struct base *b);
- int (*func_2)(struct base *b, int x);
- void (*deletor)(struct base *b);
- };
说完构造、析构,该说这里的虚函数表到底是怎么回事了。我们先画个图,还是以刚才的 base 、 derived 、derived_2 为例来说明,一看图就明白了:
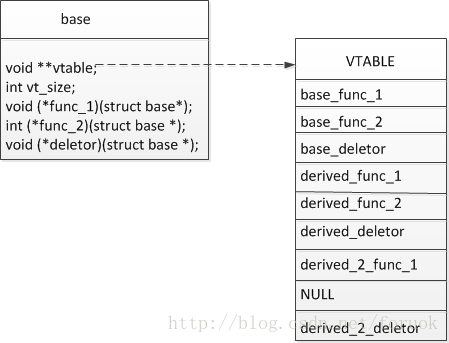
我们假定 derived 类实现了三个虚函数, derived_2 类实现了两个,func_2 没有实现,上图就是 derived_2 的实例所拥有的最终的虚函数表,表的长度( vt_size )是 9 。如果是 derived 的实例,就没有表中的最后三项,表的长度( vt_size )是 6 。
必须限制的是:基类必须实现所有的虚函数,只有这样,这套实现机制才可以运转下去。因为一切的发生是从基类的实现函数进入,通过遍历虚函数表来找到派生类的实现函数的。
当我们通过 base 类型的指针(实际指向 derived_2 的实例)来访问 func_1 时,基类实现的 func_1 会找到 VTABLE 中的 derived_2_func_1 进行调用。
好啦,到现在为止,基本说明白了实现原理,至于 初始化函数如何装配虚函数表、基类的虚函数实现,可以根据上面的思路写出代码来。按照我的这种方法实现的虚函数,通过基类指针访问,行为基本和 C++ 一致。
回顾一下:
Java 中有 interface 关键字,C++ 中有抽象类或纯虚类可以与 interface 比拟,C 语言中也可以实现类似的特性。
在面试 Java 程序员时我经常问的一个问题是:接口和抽象类有什么区别。
很多编程书籍也经常说要面向接口编程,我的理解是,接口强制派生类必须实现基类(接口)定义的契约,而抽象类则允许实现继承从而导致派生类可以不实现(重写)基类(接口)定义的契约。通常这不是问题,但在有一些特定的情况,看起来不那么合适。
比如定义一个 Shape 基类,其中定义一个 draw() 方法,给一个什么都不做的默认实现(通常是空函数体),这实际没有任何意义。
再比如基类改变某个方法的实现,而派生类采用实现继承并没有重写这个方法,此时可能会导致一些奇怪的问题。以鸟为例,基类为 Bird ,我们可能会定义一个 fly() 方法,一个 walk() 方法,因为有的人认为鸟既可以走又可以飞。开始时我们在 walk() 的实现里作了假定,认为双脚交叉前进才是 walk ,可是后来发现有些鸟是双脚一齐蹦的,不会交叉前进。这个时候怎么办?基类 Bird 的 walk() 方法是否要修改、如何修改?
在 C++ 中,没有接口关键字 interface ,同时为了代码复用,经常采用实现继承。在 C 语言中,我们前面几篇文章讨论了封装、隐藏、继承、虚函数、多态等概念,虽然都可以实现,但使用起来总不如自带这些特性的语言(如 C++ 、Java )等得心应手。一旦你采用我们前面描述的方法来进行面向对象编程,就会发现,在 C 语言中正确的维护类层次是一件非常繁琐、容易出错的事情,而且要比面向对象的语言多写很多代码(这很容易理解,面向对象语言自带轮子,而 C 要自己造轮子,每实现一个类都要造一遍)。但有一点,当我们使用 C 语言作面向对象编程时,比 C++ 有明显的优势,那就是接口。
接口强制派生类实现,这点在 C 中很容易做到。而且我们在编程中,实际上多数时候也不需要那么多的继承层次,一个接口类作为基类,一个实现类继承接口类,这基本就够了。在 C 语言中采用这种方式,可以不考虑析构函数、超过 3 层继承的上下类型转换、虚函数调用回溯、虚函数表装配等等问题,我们所要做的,就是实现基类接口,通过基类指针,就只能操作继承层次中最底层的那个类的对象;而基类接口,天生就是不能实例化的(其实是实例化了没办法使用,因为结构体的函数指针没人给它赋值)。
一个示例如下:
- struct base_interface {
- void (*func1)(struct base_interface* b);
- void (*func2)(struct base_interface* b);
- int (*func_3)(struct base_interface* b, char * arg);
- };
- struct derived {
- struct base_interface bi;
- int x;
- char ch;
- char *name;
- };
上面是头文件,derived 结构体通过包含 base_interface 类型的成员 bi 来达到继承的效果;而 base_interface 无法实例化,我们没有提供相应的构造函数,也没有提供与 func_1 , func_2 等函数指针对应的实现,即便有人 malloc 了一个 base_interface ,也无法使用。
derived 类可以提供一个构造函数 new_derived ,同时在实现文件中提供 func_1 , func_2 ,func_3 的实现并将函数地址赋值给 bi 的成员,从而完成 derived 类的装配,实现 base_interface 定义的契约。
示例实现如下:
- static void _derived_func_1(struct base_interface *bi)
- {
- struct derived * d = (struct derived*)bi;
- d->x *= 2;
- printf("d->name = %s\n", d->name);
- }
- /* _derived_func_2 impl */
- /* _derived_func_3 impl */
- struct derived *new_derived()
- {
- struct derived *d = malloc(sizeof(struct derived));
- d->bi.func_1 = _derived_func_1;
- d->bi.func_2 = _derived_func_2;
- d->bi.func_3 = _derived_func_3;
- d->x = 0;
- d->ch = 'a';
- d->name = NULL;
- return d;
- }
我们可以这么使用 base_interface 接口:
- void do_something(struct base_interface *bi)
- {
- bi->func_1(bi);
- }
- int main(int argc, char **argv)
- {
- struct derived * d = new_derived();
- do_something((struct base_interface*)d);
- return 0;
- }
上面的代码中 do_something 函数完全按照接口编程,而 bi 可以实际指向任意一个实现了 base_interface 接口的类的实例,在一定程序上达到多态的效果,花费的代价相当小,却可以让我们的程序提高可扩展性,降低耦合。
这种简单的方法也是我在自己的项目中使用的方法,效果不错。
好啦,C 语言面向对象编程系列的基础性介绍就告一段落,下面是前几篇的链接,有兴趣的可以回头看看:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









