






pandas数据结构:
Series 和一维数组一样。
import pandas as pd
ser_obj = pd.Series(range(10, 20))
print(ser_obj.index)
print(ser_obj.values)实验运行的结果:
RangeIndex(start=0, stop=10, step=1)
[10 11 12 13 14 15 16 17 18 19]
0 10
1 11
2 12
3 13
dtype: int64
# 通过list构建Series
ser_obj = pd.Series(range(10, 20))
print(type(ser_obj))
DataFrame数据类型:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
# 通过dict构建DataFrame
dict_data = {'A': 1.,
'B': pd.Timestamp('20161217'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["Python", "Java", "C++", "C#"]),
'F': 'ChinaHadoop'}
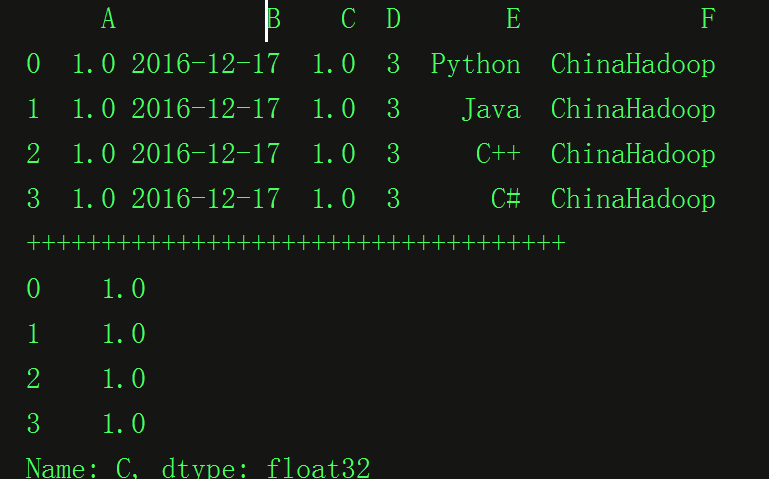
df_obj2 = pd.DataFrame(dict_data)
print df_obj2
print "++++++++++++++++++++++++++++++++++++"
print(df_obj2.icol(2))代码运行的结果:
通过索引选择:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
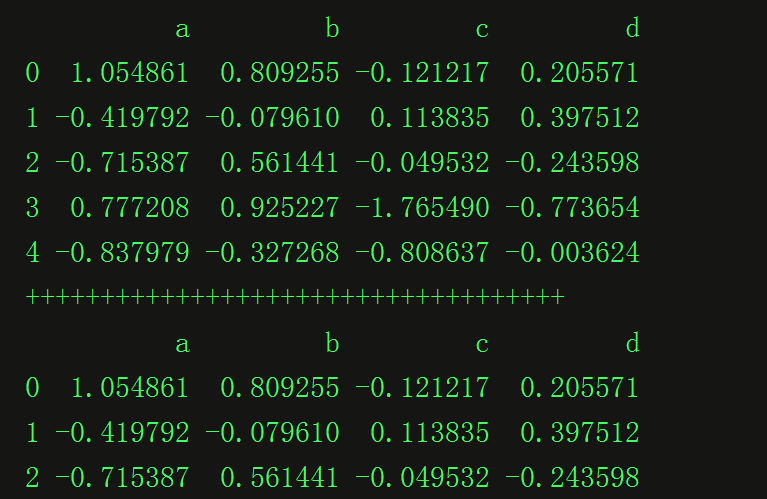
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df_obj.head())
print '++++++++++++++++++++++++++++++++++++'
print(df_obj.loc[0:2, 'a':'d'])
要指定好类型:

实验运行的结果:
使用函数的代码:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame(np.random.randn(5, 4), columns = ['a', 'b', 'c', 'd'])
print(df_obj)
print '***********************************'
print df_obj.mean()
print '***********************************'
print df_obj.max(axis=1)程序运行的结果:
a b c d
0 0.204254 2.634199 0.431409 1.273850
1 -0.471006 1.616832 -0.079988 -0.071020
2 0.825332 1.210095 -1.032459 -1.154600
3 -1.795636 -0.192036 2.129457 -1.324958
4 -0.575655 -0.592030 1.721074 0.631608
a -0.362542
b 0.935412
c 0.633898
d -0.129024
dtype: float64
***********************************
0 2.634199
1 1.616832
2 1.210095
3 2.129457
4 1.721074
dtype: float64
df4 = pd.DataFrame(np.random.randn(3, 4),
index=np.random.randint(3, size=3),
columns=np.random.randint(4, size=4))
print(df4)随机生成索引和列名。
1 0 3 2 2 -0.411452 -0.229687 0.975326 1.093240 1 -0.826130 -0.275579 -0.794847 -0.014010 1 1.026999 -0.467548 0.121314 -0.294583



df1.sub(df2, fill_value = 2)
s3_filled = s3.fillna(-1)
df = pd.DataFrame(np.random.randn(5,4) - 1)
print(np.abs(df))
print(df.apply(lambda x : x.max()))
df_data.isnull()
df_data.dropna()
df_data.fillna(-100)
多索引的一些操作
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
ser_obj = pd.Series(np.random.randn(12),
index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],
[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]])
print(ser_obj)
print '*********************************'
print ser_obj[:, 2]
print "**********************************"
#交换分层顺序
print(ser_obj.swaplevel())
#交换并排序分层
print("###################################")
print ser_obj.swaplevel().sortlevel()
a 0 -1.426302
1 0.832818
2 -0.347128
b 0 -0.015447
1 -0.656397
2 -1.546606
c 0 -0.384454
1 -1.382357
2 0.949415
d 0 1.362732
1 0.294885
2 0.522406
dtype: float64
*********************************
a -0.347128
b -1.546606
c 0.949415
d 0.522406
dtype: float64
**********************************
0 a -1.426302
1 a 0.832818
2 a -0.347128
0 b -0.015447
1 b -0.656397
2 b -1.546606
0 c -0.384454
1 c -1.382357
2 c 0.949415
0 d 1.362732
1 d 0.294885
2 d 0.522406
dtype: float64
###################################
0 a -1.426302
b -0.015447
c -0.384454
d 1.362732
1 a 0.832818
b -0.656397
c -1.382357
d 0.294885
2 a -0.347128
b -1.546606
c 0.949415
d 0.522406
dtype: float64
分组:
对数据进行分组,然后对每组数据进行分分组,然后对每组进行统计分析
SQL能够对数据进行过滤,分组聚合
pandas能利用groupby进行更复杂的分组运算
分组运算过程
split->apply->combine
拆分:进行分组的根据
应用:每个分组运行的计算规则
合并:把每个分组的计算结果合并起来
*GroupBy对象:DataFrameGroupBy, SeriesGroupBy
*GroupBy对象没有进行实际运算,只是包含分组的中间数据
*对GroupBy对象进行分组运算/多重fenugreek运算,如mean()
size()返回每个分组的元素个数
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print("*******************************")
print(type(df_obj.groupby('key1')))
print(type(df_obj['data1'].groupby(df_obj['key1'])))
运行的实验结果:

# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print("*******************************")
print(type(df_obj.groupby('key1')))
print(type(df_obj['data1'].groupby(df_obj['key1'])))
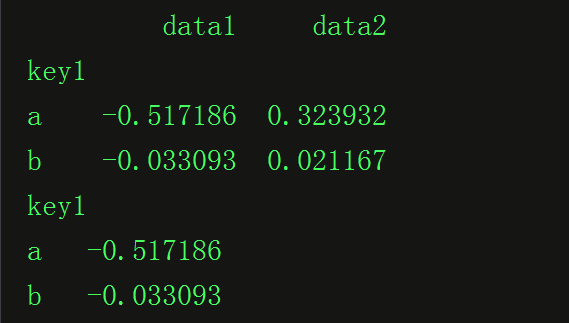
grouped1 = df_obj.groupby('key1')
print(grouped1.mean())
grouped2 = df_obj['data1'].groupby(df_obj['key1'])
print(grouped2.mean())其中运行的结果:
自定义分组:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print("*******************************")
# 按自定义key分组,列表
self_def_key = [1, 1, 2, 2, 2, 1, 1, 1]
print(df_obj.groupby(self_def_key).size())

按多个列多层分组:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print("*******************************")
# 按多个列多层分组
print(df_obj.groupby(['key1', 'key2']).size())

GroupBy对象的分组迭代:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
grouped1 = df_obj.groupby('key1')
print("*******************************")
# 按多个列多层分组
for group_name, group_data in grouped1:
print(group_name)
print(group_data)

# GroupBy对象转换list
list(grouped1)
# GroupBy对象转换dict
dict(list(grouped1))
自定义函数
实战项目:
# -*- coding: utf-8 -*-
"""
项目名称:全球食品数据分析(World Food Facts)
项目参考:https://www.kaggle.com/bhouwens/d/openfoodfacts/world-food-facts/how-much-sugar-do-we-eat/discussion
"""
import zipfile
import os
import pandas as pd
import matplotlib.pyplot as plt
def unzip(zip_filepath, dest_path):
"""
解压zip文件
"""
with zipfile.ZipFile(zip_filepath) as zf:
zf.extractall(path=dest_path)
def get_dataset_filename(zip_filepath):
"""
获取数据库文件名
"""
with zipfile.ZipFile(zip_filepath) as zf:
return zf.namelist()[0]
def run_main():
"""
主函数
"""
# 声明变量
dataset_path = './data' # 数据集路径
zip_filename = 'open-food-facts.zip' # zip文件名
zip_filepath = os.path.join(dataset_path, zip_filename) # zip文件路径
dataset_filename = get_dataset_filename(zip_filepath) # 数据集文件名(在zip中)
dataset_filepath = os.path.join(dataset_path, dataset_filename) # 数据集文件路径
print('解压zip...', end='')
unzip(zip_filepath, dataset_path)
print('完成.')
# 读取数据
data = pd.read_csv(dataset_filepath, usecols=['countries_en', 'additives_n'])
# 分析各国家食物中的食品添加剂种类个数
# 1. 数据清理
# 去除缺失数据
data = data.dropna() # 或者data.dropna(inplace=True)
# 将国家名称转换为小写
# 课后练习:经过观察发现'countries_en'中的数值不是单独的国家名称,
# 有的是多个国家名称用逗号隔开,如 Albania,Belgium,France,Germany,Italy,Netherlands,Spain
# 正确的统计应该是将这些值拆开成多个行记录,然后进行分组统计
data['countries_en'] = data['countries_en'].str.lower()
# 2. 数据分组统计
country_additives = data['additives_n'].groupby(data['countries_en']).mean()
# 3. 按值从大到小排序
result = country_additives.sort_values(ascending=False)
# 4. pandas可视化top10
result.iloc[:10].plot.bar()
plt.show()
# 5. 保存处理结果
result.to_csv('./country_additives.csv')
# 删除解压数据,清理空间
if os.path.exists(dataset_filepath):
os.remove(dataset_filepath)
if __name__ == '__main__':
run_main()















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









