






《Backdoor Learning: A Survey》阅读笔记
联邦学习后门攻击总结(2019-2022)
How To Backdoor Federated Learning
Federated Learning
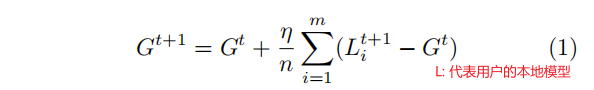
Adversarial Model Replacement
Threat model
联邦学习使攻击者能够完全控制一个或几个参与者,例如,那些学习软件被恶意软件破坏的智能手机:
(1)攻击者控制任何妥协参与者的局部训练数据;(2)控制局部训练过程和epoch数和学习速率等超参数;(3)可以在提交模型进行聚合之前修改结果模型的权重;(4)可以自适应地将局部训练从一轮改变到另一轮。
攻击者不控制用于将参与者的更新合并到联合模型中的聚合算法,也不控制良性参与者训练的任何方面。我们假设他们通过正确地将联邦学习规定的训练算法应用到他们的局部数据中来创建他们的局部模型。这种设置和传统的中毒攻击(见第2节)之间的主要区别是,后者假设攻击者控制了很大一部分的训练数据。相比之下,在联邦学习中,攻击者控制着整个训练过程——但只针对一个或几个参与者。
攻击的目标: 我们的攻击者希望联合学习产生一个联合模型,在其主要任务和攻击者选择的后门子任务上都达到较高的准确性,并在攻击后的多轮后门子任务上保持较高的准确性。相比之下,传统的数据中毒的目的是改变模型在大部分输入空间上的性能,而拜占庭攻击的目的是防止收敛
安全漏洞是危险的,即使它不能每次被利用,并且在开发后一段时间。出于同样的原因,如果一个模型替换攻击有时引入后门(即使有时失败),那么它是成功的,只要模型在至少一轮中显示出较高的后门精度。在实践中,攻击表现得更好,后门停留了很多回合
我们提出了一种新型的后门,即语义后门,与像素后门不同,它会导致模型在未经修改的数字输入上产生攻击者选择的输出。例如,一个反向的图像分类模型为所有具有特定特征的图像分配攻击者选择的标签,例如,所有紫色汽车或所有带有赛车条纹的汽车都被错误归类为鸟类(或攻击者选择的任何其他标签)。一个落后的单词预测模型表明,一个攻击者选择的单词来完成某些句子。
Constructing the attack model
Naive approach:The attacker can simply train its model on backdoored inputs. 继Gu等人(2017)之后,每个training patch应该包括一个混合的正确标记输入和反向输入,以帮助模型学习识别双错误。攻击者还可以改变local learning rate and the number of local epochs to,以最大限度地提高对the backdoored data的过拟合。
The naive approach does not work against federated learning. 聚合抵消了大部分反向模型的贡献,联合模型很快就忘记了后门。攻击者需要经常被选择,即使这样,中毒的速度也非常慢。在我们的实验中,我们使用朴素的方法作为基准。
Model replacement:在这种方法中,攻击者雄心勃勃地尝试用等式中的恶意模型X替换新的全局模型Gt+1
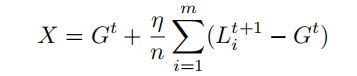
因为“non-i.i.d.”,训练数据时每个局部模型可能都远离Gt。当全局模型收敛时,这些偏差开始被抵消。

模型替换确保攻击者的贡献平均存活,并转移到全局模型。Model replacement ensures that the attacker’s contribution survives averaging and is transferred to the global model
这是一种单次攻击:全局模型在被中毒后对后门任务立即显示出很高的准确性。
Improving persistence and evading anomaly detection
因为攻击者可能只被选中进行一轮训练,所以他希望在模型被替换后,后门能在模型中尽可能多地保留一轮。防止良性参与者更新模型时的后门被遗忘,类似于多任务学习中的灾难性遗忘问题
我们的攻击涉及双任务学习,全局模型在正常训练中学习主要任务,只有在攻击者被选择的回合中学习后门任务。攻击者的目标是对这两个任务都保持高精度。根据经验,EWC损失 并没有改善我们的结果,但我们使用了其他技术,如在攻击者的训练中降低学习速率 l r a d v lr_{adv} lradv,以提高联合模型中后门的持久性。
联邦学习使用安全聚合 防止聚合器检查参与者提交的模型。因此,无法检测聚合是否包含恶意模型,也无法检测是谁提交了该模型。
如果没有安全的聚合,隐私就会丢失,但是聚合器可能会试图过滤掉“异常”的贡献。因为使用等式3创建的模型的权重被显著放大了,这样的模型似乎很容易检测和过滤掉。然而,联邦学习的主要动机是利用non-i.i.d.参与者的多样性培训数据,包括不寻常或低质量的本地数据,如智能手机照片或短信历史记录。因此,通过设计,聚合器甚至应该接受精度较低且与当前全局模型有显著不同的局部模型。在附录C.1中,我们具体展示了 how the fairly wide distribution of benign participants’ 良性参与者models enables the attacker to create backdoored models that do not appear anomalous.
Constrain-and-scale:我们现在描述了一种通用的方法,它使对手能够产生一个在主要任务和后门任务上都具有较高精度的模型,但不会被聚合器的异常检测器拒绝。直观地说,我们通过使用一个目标函数将逃避异常检测纳入到训练中,该函数(1)奖励模型的准确性,(2)惩罚它偏离聚合器认为的“正常”。根据Kerckho↵的原理,我们假设攻击者知道异常检测算法。

因为攻击者的训练数据包括良性输入和后门输入,所以
L
c
l
a
s
s
L_{class}
Lclass捕获了主任务和后门任务的准确性,原始参数和新参数之间的均方误差MSE。
L
a
n
o
L_{ano}
Lano可以解释任何类型的异常检测,如权值矩阵之间的p-范数距离
Train-and-scale: 只考虑模型权重大小的异常探测器(Shenetal.,2016)可以使用一种更简单的技术来规避。攻击者训练反向模型直到它收敛,然后将模型的权重由γ扩展到异常检测器允许的边界S
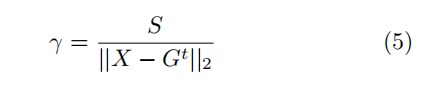
算法流程:

Experiments
Image classification
我们使用CIFAR-10数据集进行图像分类任务,训练一个包含100名参与者的全局模型,每轮随机选择10人。我们使用轻量级的ResNet18CNN模型(Heetal.,2016),具有27万个参数。要模拟non-i.i.d.训练数据并向每个参与者提供来自每个类的不平衡样本,我们使用超参数为0.9的狄利克雷分布来分割50,000张训练图像。每个参与者选择2个局部阶段,学习率为0.1。
Backdoors: 作为运行示例,假设攻击者希望联合模型将具有某些特征的汽车图像错误分类为鸟类,同时将其他输入正确分类为鸟类。攻击者可以选择一个自然发生的功能后门,如果他想完全控制后门触发时,选择一个特性不发生在自然界(因此,不是良性参与者的训练图像),如一个不寻常的汽车颜色或一个特殊的对象的存在。攻击者可以使用后门特性生成他自己的图像来训练他的本地模型。
在我们的实验中,我们选择了三个特征作为后门:绿色汽车(CIFAR数据集中的30张图片),带有赛车条纹的汽车(21张图片),以及背景中带有垂直条纹墙壁的汽车(12张图片)——见图2(a).我们选择这些特性是因为CIFAR已经包含了可以用于训练反向模型的图像。我们将数据进行分割,以便只有攻击者拥有具有后门特征的训练图像,但这不是必要的:如果后门特征与良性参与者的数据集中出现的一些特征相似,那么攻击仍然成功, 但联合模型更快地忘记了后门。
在训练攻击者的模型时,我们遵循Gu等人(2017),在每个训练批中混合后门图像和良性图像(c=20个后门图像尺寸为64号)。这有助于模型学习后门任务,而不影响其在主要任务上的准确性。参与者的训练数据非常多样化,后门图像只代表了很小的一部分,因此引入后门对联合模型的主任务精度几乎没有影响。我们的攻击也使用像素模式的后门(见附录↵.5)。在攻击者的训练过程中,我们为一批64张图像中的5张图像添加一个特殊的像素模式,并将它们的标签更改为鸟。与语义后门不同,这种后门同时需要训练时间和推理时间的攻击
Word prediction
Word预测对于联邦学习是一项很好的任务,因为训练数据(例如,用户在手机上输入什么)是敏感的,排除了集中收集。它也是NLP任务的代理,如问题回答、翻译和总结。
Experimental results
我们进行了100轮联邦学习的所有实验。如果在给定的一轮中选择了多个攻击者控制的参与者,他们将划分更新,使其加起来成为一个反向模型。对于基线攻击,所有攻击者控制的参与者提交如4.2节中训练的单独模型。
总结
我们发现并评估了联邦学习中的一个新的脆弱性。通过模型平均,联邦学习给出了成千上万甚至数百万的参与者,其中一些参与者将不可避免地是恶意的,直接影响联合学习模型的权重。这使得恶意的参与者能够在联合模型中引入一个后门子任务。联邦学习是为了利用参与者的non-i.i.d.本地训练数据,并使用安全聚合来保持这些数据的隐私,因此异常检测不能被部署,无论如何也不会被使用。
我们开发了一种新的模型替换方法,利用这些漏洞,并证明了其在标准的联邦学习任务上的有效性,如图像分类和单词预测。即使在先前提出的数据中毒攻击失败或需要大量恶意参与者时,模型替换也能成功地注入后门。另一个导致后门攻击成功的因素是现代深度学习模型的巨大能力。传统的模型质量度量衡量模型学习主要任务的程度,而不是它学到的其他东西。这种额外的容量可以用来引入隐蔽的后门,而不会对模型的精度产生显著影响。
联邦学习不仅仅是标准机器学习的分布式版本。它是一个分布式系统,因此必须对任意行为不当的参与者非常健壮。不幸的是,当参与者的训练数据不是i.i.d.时,现有的拜占庭容忍分布式学习技术并不适用,而这正是联邦学习的激励场景。如何设计鲁棒的联邦学习系统是未来研究的一个重要课题。
此外,我们通过对来自多个选定“目标客户”的示例进行分组来形成后门任务。由于来自不同目标客户端的示例遵循不同的分布,因此我们将目标客户端的数量称为“后门任务数量”,并探讨其对攻击成功率的影响。 直观地讲,我们拥有的后门任务越多,攻击者试图破坏的功能空间就越丰富,因此,攻击者越难成功地对模型进行后门而不破坏其在主要任务上的性能。
BACKDOOR ATTACK
指poisoning-based backdoor attack towards image classification, where attackers can only modify the dataset instead of other training components(e.g., training loss)
Poison-Label Backdoor Attack
这是目前最常见的攻击范式,其中目标标签不同于有毒样本的地面真实标签。BadNets (Guetal.,2019)是第一个也是最具代表性的毒药标签攻击。具体来说,它从原始良性数据集中随机抽取几个样本,通过将后门触发器踩到(良性)图像上来生成有毒样本,并使用攻击者指定的目标标签更改其标签。生成的与剩余良性样本相关的中毒样本合并,形成中毒训练数据集,并交付给用户。之后,(Chenetal.,2017)认为中毒的图像应该与良性的硬性图像相似,并在此基础上提出了混合攻击。最近,(Xueetal.,2020;Li等人,2020b;2021c)进一步探索了如何更偷偷地进行毒药标签的后门攻击。最近,提出了一种更隐秘、更有效的攻击,WaNet(Nguyen&Tran,2021)被提出。WaNet采用图像扭曲作为后门触发器,它可以变形但保留了图像内容
Clean-Label Backdoor Attack
由毒药标签攻击产生的有毒图像可能与良性版本相似,但用户仍然可以通过检查图像-标签关系来注意到攻击。为了解决这个问题,Turner等人(2019)提出了清洁标签攻击范式,其中目标标签与中毒样本的地面真实标签一致。具体来说,他们首先利用对抗性扰动或生成模型来修改目标类中的一些良性图像,然后进行标准的触发注入过程。这一想法被推广到(Zhao视频分类etal.,2020b)中的攻击,他们采用了针对性的通用对抗扰动(mosavi-Dezfololi等人,2017)作为触发模式。尽管与有毒标签的后门攻击相比,干净标签的后门攻击更隐秘,但它们通常性能相对较差,甚至可能无法创建后门(Lietal.,2020c)。
选择了BadNets(Gu等人,2019C++ 写的)、混合策略的后门攻击(称为“混合”)(Chen等人,2017)、WaNet(Nguyen&Tran,2021)和对抗性扰动的标签一致攻击(称为“标签一致”)(Turner等人,2019)进行评估。它们分别是基于补丁的可见的和不可见的毒药标签攻击、非基于补丁的毒药标签攻击和清洁标签攻击的代表
如果攻击者大致知道全局模型的状态,那么一个简单的权重重新缩放操作就会导致模型替换。我们注意到,这些模型替换攻击要求:(i)模型接近收敛,? 并且(ii)对手对其他一些系统参数(即用户数量、数据集大小等)有近乎完美的知识。
我们研究了插入这些攻击的两种方法:数据中毒和模型中毒。在数据中毒(即黑盒)设置中,对手只被允许用他们的偏好之一替换他们的本地数据集。与[13,33,34]类似,在这种情况下,在攻击者的数据集中插入一个干净的和后门的数据点的混合物;后门数据点针对特定的类,并使用首选的目标标签。在模型中毒(即白盒)设置中,允许攻击者向服务提供商发送他们喜欢的任何模型。这是[13,14]所关注的设置。在[14]中,作者在训练过程中采取对抗的观点,用针对特定子任务的度量取代本地攻击者的度量,并使用基于近端的方法来近似这些任务。在这项工作中,我们采用了一种类似但在算法上不同的方法。我们用投影梯度下降(PGD)来训练一个模型,这样在每一轮FL中,攻击者的模型就不会明显偏离全局模型。PGD攻击的效果,在[27]中也表明比 vanilla model-replacement更强,对一系列防御机制表现出更强的抵抗力。
我们通过一系列预测任务(图像分类、OCR、情绪分析和文本预测)、数据集(CIFAR10/ImageNet/EMNIST/Reddit/Sentiment140),和模型(VGG-9/VGG-11/LeNet/LSTMs)显示,我们的边缘案例攻击可以在FL模型中被固定连接,只要0.5-1%的边缘用户总数是对抗性的。我们进一步证明,这些攻击对于基于差异隐私(DP)[27,35]、范数剪切[27]和Krum和Multi-Krum[17]等鲁棒聚合器的防御机制具有鲁棒性。我们注意到,我们并没有声称我们的攻击对任何防御机制都是强大的,并把一个防御机制的存在作为一个开放的问题。
边缘箱后门的含义。边缘案例后门的影响并不意味着它们很可能频繁发生,或影响到一个庞大的用户群。相反,一旦表现出来,它们可能会导致失败,不成比例地影响小用户群体,例如,特定种族的图像,在不寻常的环境中发现的语言或在美国不常见的书写风格,大多数数据可能被绘制。高容量模型错误预测分类子任务的倾向,特别是那些可能在训练集中代表不足的任务,并不是一个新的观察结果。例如,最近的几份报告表明,神经网络可以通过附加攻击性标签[36]来错误地预测代表不足的少数民族个体的输入。涉及边缘案例输入的故障也是自动驾驶汽车安全的一个严重问题。
我们的工作表明,不幸的是,这种方式的边缘情况故障可以通过后门硬连接到FL模型。此外,正如我们所展示的,试图过滤掉插入这些后门的潜在攻击者,也有不利影响,过滤掉仅仅包含足够多样数据集的用户,呈现出未探索的公平性和鲁棒性权衡,这是在[12]中提出的。我们相信,我们的研究结果对FL系统在其目前形式下的公平和稳健预测的可行性提出了严重的怀疑。至少,FL系统提供商和相关的研究社区必须认真地重新考虑如何在存在边缘情况故障的情况下保证稳健和公平的预测
资料
后门攻击资料汇总
https://blog.csdn.net/weixin_42561013/article/details/118641259 Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
其复现:https://blog.csdn.net/weixin_44338712/article/details/113704644














 2812
2812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









