







这篇论文提出了一种提出了一种在联邦学习环境下有效攻击训练模型的后门攻击方法——model replacement。并针对这种方法存在的问题提出了改进方法。同时,作者还总结了一些联邦学习在安全方面的问题,并结合联邦学习环境,对现有关于训练过程以及训练模型保护方法优缺点进行了分析。
一、Federated Learning 联帮学习
联帮学习(FL)是一种分布式学习方法。在这种方法中,成千上万的参与者(client)利用本地的训练数据,在本地完成local model的训练,再将各自的local model呈交给server。Server整合来自各个client的local model,更新global model。如此反复,直至global model收敛。由于在整个训练过程中,client的训练数据并没有离开client设备本身,因此联邦学习在一定程度上保护了数据隐私。
与普通的分布式学习相比,联邦学习有以下特点:
- 参与者数量庞大;
- 数据异质性,即各个client提供的训练数据在数据量、分布、质量等方面都存在差异;
- 系统异质性,例如各个client设备对抗外来攻击的能力有所不同。
此外还有其他特点,由于与本文不太相关,就不再赘述。
二、Backdoor Attack 后门攻击
后门攻击是指在模型训练过程中,向模型植入后门(backdoor),使得模型在实现自身本职功能的同时,还能实现后门功能。
三、Poisoning Attack
Poisoning attack分为两种:Data poisoning与Model poisoning。
1.Data Poisoning
顾名思义,这种攻击方法是对训练数据动手脚,导致训练得到模型在测试时的准确率降低,达到攻击目的。例如在图片分类模型的训练数据中加入污渍,降低训练数据的质量,从而影响训练结果。
后文中提到的adversarial transformation就是一种data poisoning方法。
2.Model Poisoning
顾名思义,这种攻击方法是对训练模型动手脚。例如在后门攻击中,攻击者分别用原始训练数据和backdoored训练数据训练模型,使模型学习两者的区别。得到的模型同时具备本职功能与后门功能。
本文所提的model replacement是一种model poisoning方法。
四、相关抵御攻击的方法
本节介绍了一些帮助训练模型在训练过程中抵御外部攻击的方法,当这些方法要么不适用于联邦学习的模式,要么难以抵御后门攻击。
1. 对训练过程中攻击的抵御
Fine-pruning、filtering、clustering这些方法都需要获取到训练数据或是结果模型(resulting model)后才能提供保护。这违背了FL不可获取到训练数据的设定,因此不能应用于FL。
2.对测试过程中攻击的抵御
由于后门攻击的特点,模型的本职功能并不会受到影响,因此不会在检测过程中造成准确率波动大的结果,所以后门攻击不会被发现。
3.Secure ML
Secure multi-party computation虽然能够在训练过程中保护数据的隐私,但是并不能保护模型的完整性(model integrity)。具体的解决方法,例如training secret models on encrypted、vertically partitioned data,并不能应用于FL。
此外,由于secure aggregation和异常检测(anomaly detection)两种防御方法之间存在冲突,采用secure aggregation就必然意味着放弃了对异常情况的检测。
4.参与者级差分隐私(participant-level differential privacy)
差分隐私的一些常用方法并不能在未标签的数据集上实现knowledge transfer。
FL中,训练数据由clients收集,数据集的规范性有很大的问题。因此,目前差分隐私与FL的结合还有很大的局限性。
5.拜占庭容错分布式学习(Byzantine-tolerant distributed learning)
在拜占庭容错分布式学习中一条关键的假设便是:训练数据独立同分布,或是未被改动和同等分布(equally distributed)。
这个假设与FL中训练数据的特征完全背离,因此不适用于FL。
6.异常检测(Anomaly detection)
Data-based的异常检测是根据参与者提交上来的local model与当前global model之间的差异来判断是否异常的。但是在FL中,各个client的训练数据存在异质性,因此较大的差异难以避免,server对于这些local model通常也只能采取接收对待。
以上的这些保护方法都存在的各自的缺点,再加之FL环境中,参与者数量庞大,鱼l龙混杂,不可能保证所有的参与者都是诚信友善的。者都给予了攻击者可乘之机。
五、Adversarial Model Replacement
本文所提出的model replacement是在普通model poisoning的基础上进行了改进。我在第二小节中总结了data poisoning、model poisoning、model replacement三种攻击方式的区别。
1.Model replacement原理
由于攻击者能够控制的参与者数量要比参与者的总数小得多,尽管model poisoning不会影响测试准确率,从而躲避异常检测,但是在生成global model的averaging过程中,攻击效果会被逐渐冲淡。
Model replacement就是针对这一点提出了改进方法。
在分布式学习中,有local models整合得到global model的方式如下:
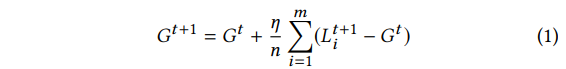
而在model replacement中,攻击者想要用恶意模型X替换新得到的全局模型G<t+1>:
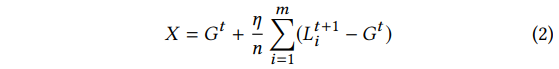
由于各个client上的数据并非是独立同分布的,因此这些local model与当前的个global model有很大的偏差,但是随着个global model的收敛,偏差逐渐减小,即: 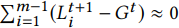
因此,攻击者可以通过下述方式得到准备提交的backdoored local model:
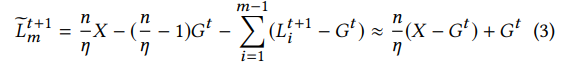
L 表示local model
G 表示global model
X 表示恶意模型
t 表示当前迭代周期
此处假设m号为攻击者控制的client。
我们可以观察到,通过上述方式获得的模型,并不会影响模型的本职功能的效果,也不至于与当前global model有难以接受的差异。因此可以有效躲避异常检测。
此外,我们可以通过扩大 γ=n/η 来保障后门backdoored model在averaging过程中存活下来,以至取代global model。
(对于不知道n和η的攻击者可以通过每轮迭代增加比例因子γ并测量后门任务模型的精度来近似该比例因子γ)
Model replacement是一种single-shot attack,即单次攻击便可使攻击效果持续多次迭代周期。并且随着攻击者的多次参与,攻击效果叠加。
2.三种攻击方式的区别
Data poisoning的攻击目标是训练数据,通过对模型训练数据进行修改,从而导致训练数据质量下降或植入恶意信息,导致分类错误、准确率下降。这种攻击方式在异常检测阶段和模型整合阶段都会被比较容易识别出来,导致攻击失效。
Model poisoning的攻击目标则是学习模型,并不会对原始训练数据做任何修改,最普遍的做法是同时用原始数据集与backdoored数据集同时训练模型,是模型学习两者的区别。这样并不会导致模型在本职功能上的准确率有较大的波动,从而躲避异常检测。但是在模型整合过程中,攻击效果仍然会被其余良性模型的贡献抵消。
Model replacement是在model poisoning的基础上,针对模型整合提出了一种有效的获取backdoored model的方法。这种方法对于异常检测和模型整合都能有效规避。
六、Model Replacement的改进
本文在攻击效果持久性和规避异常检测两方面对model replacement提出了改进方法。
1.提高持久性
我们需要知道,FL的参与者数量众多,attacker控制的clients并非每次迭代都有机会参与,在attacker没有参与的迭代中,攻击效果仍然会被削弱。因此提高功攻击效果的持久性至关重要!
在本文中,采用在攻击者训练中减缓学习率的方式来提高攻击效果的持久性。
2.规避异常检测
这里我们假设server端异常检测方法对于攻击者是已知的。
1)Constrain-and-scale方法
这种方法是在模型训练时应用的损失函数中加入一个异常检测项:
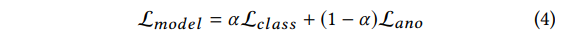
这个异常检测项奖励提高模型准确率的行为,惩罚提高暴露风险的操作。训练得到的模型因此具有规避异常检测能力。我们可以通过参数α控制异常检测项的重要性。

2)Train-and-scale方法
对于data-based的异常检测方法,我们可以通过一种十分简单的方法进行规避。攻击者训练后门模型直至收敛,然后通过扩大参数γ来提高这个模型的权重,直至异常检测器允许的界限S:
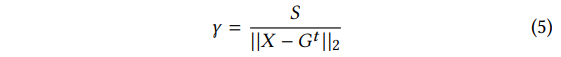
上述两种规避异常检测的方法中,train-and-scale适用于对付比较简单的data-based异常检测方法;而constrain-and-scale适用于对付较为复杂的异常检测方法。
(上述总结可能存在问题,敬请大家指正!万分感谢!)















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









