







1、python的安装与使用环境
1)可以单纯的安装python,它有自带的集成开发环境,方法是到官网下载安装程序,按提示安装即可:Python Releases for Windows | Python.org(根据自己电脑的配置选,如Windows x86-64 executable installer),安装的时候,最好把“Add Python 3.6 toPATH”勾选上,这样自动设置好用户变量了。在cmd中执行python-V(大写V)可以看到安装成功的版本。
安装成功后,在开始菜单里,找到 Python IDLE,双击运行,就可以开始调试代码了,需要什么包,可以到官网上去下载安装。
通常Linux系统,如:Ubuntu、CentOS都已经默认随系统安装好python程序了,在linux类系统中,这个idle叫做Python解释器,它是从终端模拟器中,输入“python”这个命令启动的。
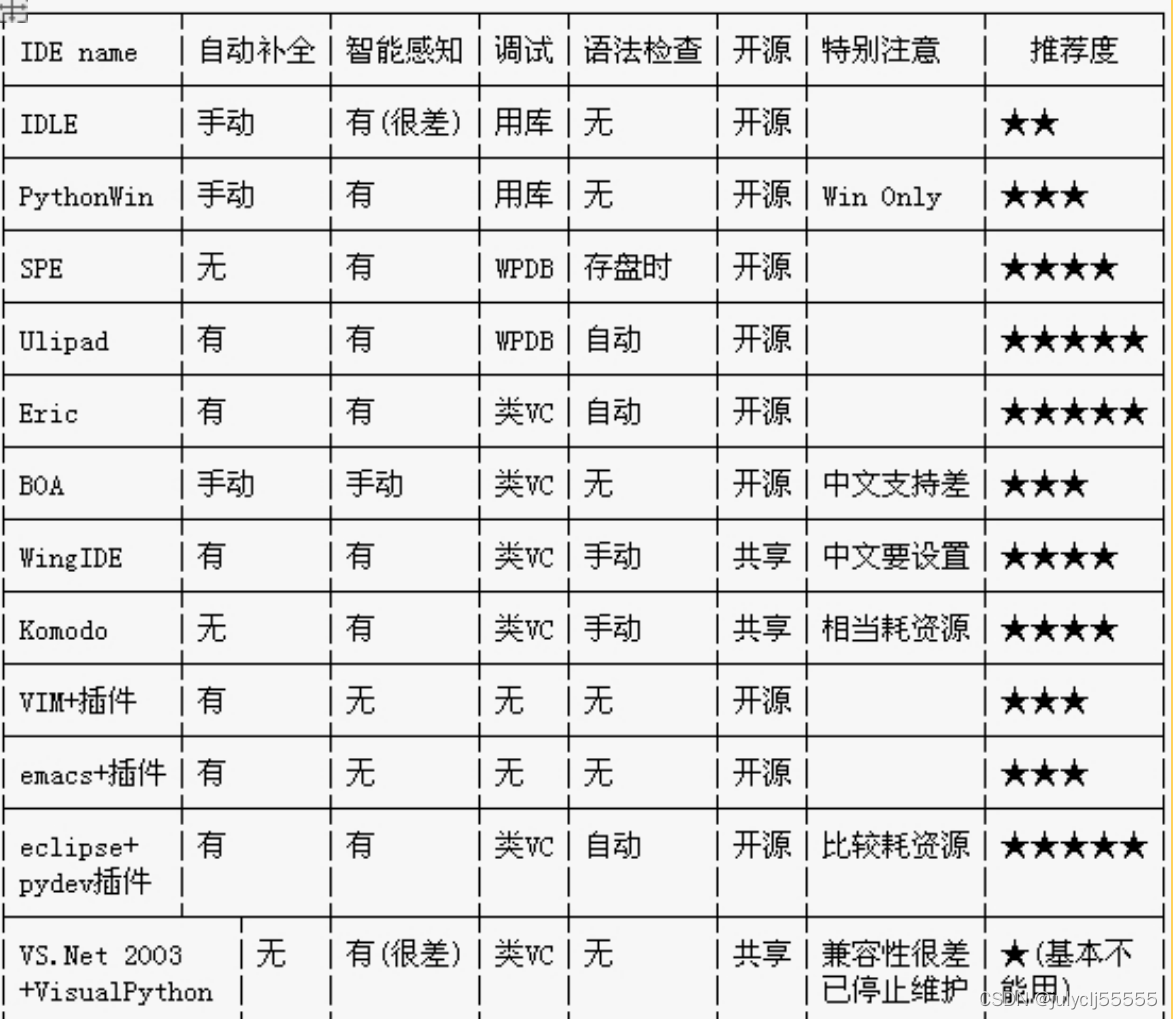
2)其他封装好了的集成开发环境(IDE),界面更友好,已封装好大部分包
PyCharm:
PyDev:
Wing IDE:
Komodo IDE:
Eric:
Eclipse:
Spyder:
PyScripter:
Geany:
以上环境,据说是几个有名的python集成开发环境,但是有些开源有些闭源,有些对操作系统有限制,而且我只听过Eclipse和Spyder。
身边人常用的集成环境是Anaconda,安装好后,开始菜单里,其下面有Spyder环境
官网下载地址Anaconda | Individual Edition
已安装了一个旧版本,需要添加一个新版本,方法是,在cmd命令行中输入:
conda create -n py35 python=3.5 anaconda (此操作可以在网站:
Getting started with conda — conda 4.11.0.post8+f60f0f16 documentation 进行查询)
控制台输入:conda info –envs 可以看已安装好的PYTHON环境,标*的是当前使用版本
控制台输入:python --version,可以看到当前的版本:
控制台输入:activate py35,可以启动其他版本(前提是有安装,例如py35)
jupyter notebook:编写python程序的地方
3)Ubuntu搭建虚拟机,主要使用sklearn和keras开源模块
4)Google开发的深度神经网络python开源模块tensorflow目前不支持windows系统,因此强烈建议使用linux操作系统,而redhat虽然是Linux系统中比较成熟的一种,但是其yum是付费服务,并且没有预装apt-get等大量的插件,因此选择ubuntu系统,对于刚入门的新手来说更友好。
虚拟环境配置好后(VM WARE),进入,依次安装git(
点击左上角的图标,点击terminal,打开命令行窗口。
输入sudo apt-get install git,下载git安装包
输入git config --global user.name "Your Name"git config --global user.email "youremail@domain.com"设置你的git的用户名和邮箱
设置完成后,输入git config -list,显示信息如下:
user.name=Your Name
user.email=youremail@domain.com
在命令行中输入git,要是有正确返回,则git安装完成。)
Anaconda2的安装(
Anaconda2对应的就是Python2.x的版本,Anaconda3对应的就是Python3.x的版本。Python2.x版本经常会遇到字符编码的各种问题,Python3.x的默认编码方式是UTF-8,很少出现字符编码的各种问题。
从官网上直接下载Anaconda2 适合linux的安装包,复制粘贴到/home/bigdata/Downloads下,建议直接在Ubuntu的火狐浏览器下直接下载,这样直接从网上将Anaconda2、pycharm下载到相应的目录。pycharm下载后是tar.gz格式,可以右键点击extract here进行解压到当前目录。同时,在/home/bigdata/Downloads下新建data、tmp两个文件夹,存放数据分析的数据和模型结果。
此时,由于下载的Anaconda2是一个.sh文件,Ubuntu系统对于.sh文件不能很好的兼容,所以不能直接点击打开,必须使用命令行打开。
输入cd /home/bigdata/Downloads跳转到Anaconda2的目录
输入bash Anaconda2-4.1.1-Linux-x86_64.sh,启动安装程序,按照提示进行操作
完成后,/home/bigdata文件夹会有一个anaconda2的文件夹。
添加环境变量,使系统能够使用Anaconda里的工具命令。
输入sudo gedit /etc/environment,输入登录密码,这里的密码是不可见的。得到
在PATH路径中添加anaconda的bin包路径,注意要添加到“”中,并且用:隔开。
点击save保存。然后退出
打开命令行,输入python,如果出现下图,则Anaconda安装成功。
但这时安装好的Anaconda2里的python2.7.12仍然不是系统默认的Python工具
输入sudo rm /usr/bin/python删除原系统默认的python工具
输入sudo ln -s /home/bigdata/anaconda2/bin/python2.7 /usr/bin/python建立新连接
输入source /etc/environment让操作生效。
输入python,得到下列信息,则python和anaconda彻底安装成功。)
当安装完Anaconda以后,记得要添加环境变量,比如我安装路径为:F:\Anaconda3 ;那么安装完成后 就要做接下来的操作:
右键我的电脑---属性---高级系统设置----高级选项里面有一个环境变量,点击环境变量------系统变量里面 找path------双击path,添加路径,路径间用;隔开。
需要添加的路径有三个(以我的为例子):F:\Anaconda3; F:\Anaconda3\Scripts; F:\Anaconda3\Library\bin
机器学习相关开源模块安装(
安装Anaconda后,可以使用pip或conda工具进行下载开源Python模块,但是必须保持网络连接状态。由于深度神经网络和一些机器学习的模块很新,所以必须两个命令都用到。
输入:
conda install theano
conda install keras
pip install tensorflow
pip install sklearn
安装提示信息安装,完成后,输入python进入python命令行工具,分别输入import keras和import sklearn,如果没有错误信息,则模块安装完成。)
完了之后,再cmd中直接输入python,如果没有异常报错,那就说明anaconda装好了,Python可以用了。
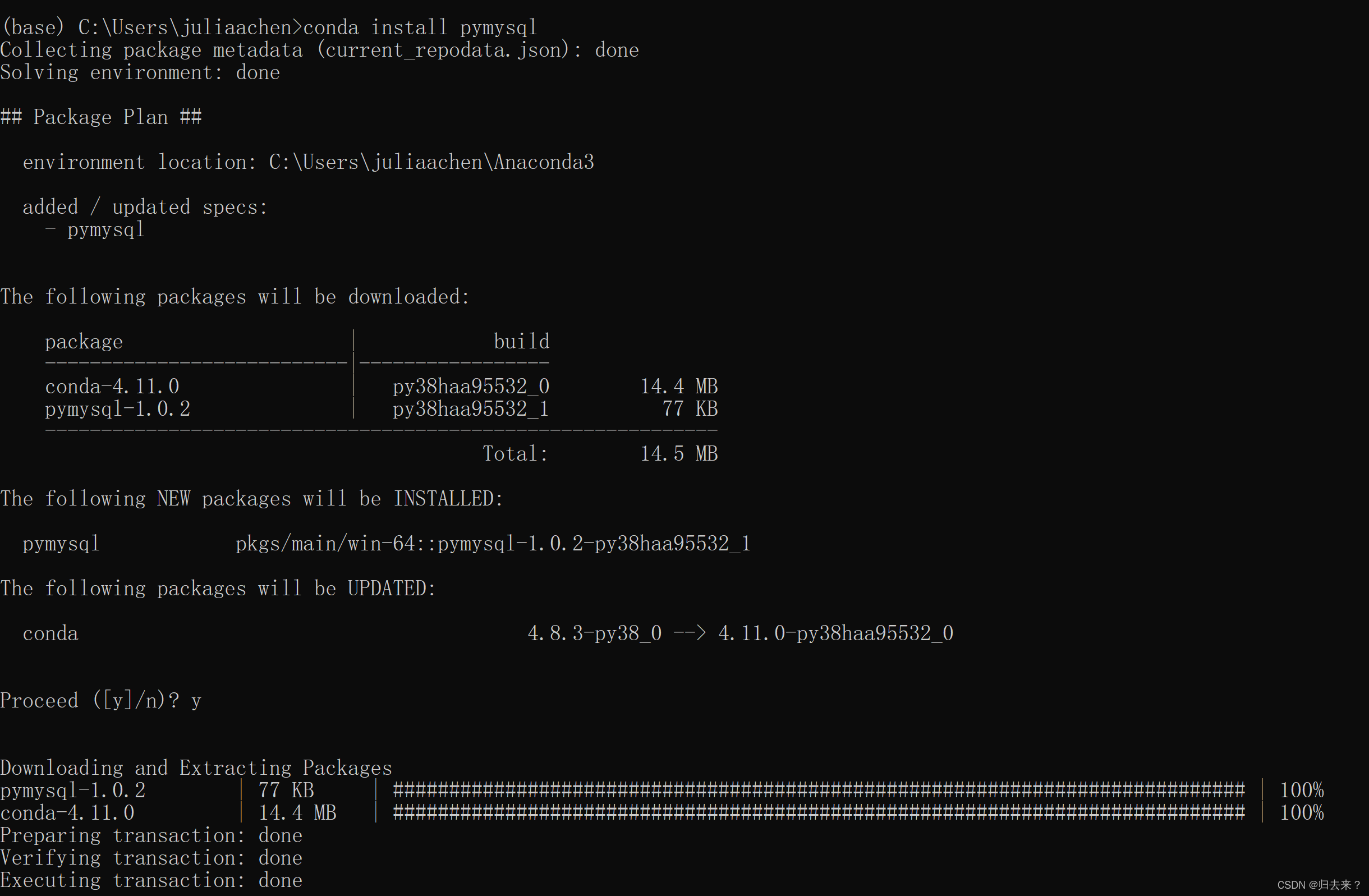
annaconda环境下安装pymysql:
使用pycharm(
打开命令行输入cd /home/bigdata/Downloads/pycharm-community-2016.2.2/bin
输入 bash pycharm.sh运行pycharm
点击左上角的FIle-->settings--->version control----->github,输入自己的github账号和密码,点击测试
点击Test后,第一次会让你设置本地github的登录密码,这个密码必须记住,因为是不是系统在你提交代码或者从github上clone时需要填写这个密码来验证。
在选择git这个选项,设置你已经安装好的git工具的路径,一般为/usr/bin/git.
点击Test,出现下图则github和git都配置成功,可以使用了。)
从github中导入项目
从菜单栏中点击VCS,选择checkout from version control,再选择github。
然后就可以选择你想要的项目导入到本地了。
从目前的文档看,TensorFlow支持CNN、RNN和LSTM算法,这都是目前在Image,Speech和NLP最流行的深度神经网络模型。
2、python集成开发环境的使用
这里重点学习Spyder,因为它是anaconda自带的,很好的集成了SciPy、NumPy和Matplotlib这样的公共Python数据科学库。
1)Spyder的配置
基本的配置都在 tool->perference 里面
在Graphic勾选上 Automatical load Pylab and NumPy modules 这样可以在ipython界面可以直接敲plot() 作图!
在Startup设置启动执行的脚本,写入要导入的包
import numpy as np,import scipy as sp,import pylab as pl,import pandans as pd
1. Editor窗口:即左边的窗口。可以用来写大段的代码,之后像MATLAB一样,用上面菜单栏的绿色按钮运行。
2. python console/history log/ipython console窗口:即右下角的窗口。
python console/ipython console是控制台,分别相当于python和ipython的命令行窗口,可以直接在窗口里输入代码,敲回车就能执行上一行。python和ipython的区别可参考http://blog.sina.com.cn/s/blog_6fb8aa0d0101r5o1.html
简而言之就是ipython在python的基础上添加了若干功能。
history log相当于历史记录,记录之前在命令行输入过的代码。
3. variable explorer/file explorer/help
分别显示现有的变量、文件,和帮助。
此外,Spyder还有附加技能若干:
1. 先按住Ctrl键,再单击某一变量,光标会跳至那个变量定义的地方。
2. 其实是ipython的功能:再ipython console里输入某个命令,再按tab键,可以自动补全
3. 其实也是ipython的功能。输入变量名+? 会显示变量的说明。
Editor(编辑器)用于编写代码,Console(控制台)可以评估代码并且在任何时候都可以看到运行结果,Variable Explorer(变量管理器)可以查看代码中定义的变量。
2)Spyder的调试
点击spyder工具栏上的Debug file按钮,或者使用快捷键Ctrl+F5开始调试。
出现了ipdb就代表调试开始。
Ctrl+F10是单行执行的意思,每按一次执行一行。
Ctrl+F5 以Debug模式运行文件
在debug之前记得用%reset 指令清空一下ipython工作空间中的变量,以免影响debug中变量值的查看
无论你是否打断点,都会在第一行语句执行之前中断一次
!(python语句)可以在pdb提示符下执行python语句,可以用来查看变量值或者给变量临时指定值
c命令或者Ctrl+F12可以让程序执行到下一个断点
q命令退出调试
Ctrl+F10 单行执行
双击行首设置断点,按住Ctrl+Shift 双击行首可以设置条件断点
全面的使用教程见:Spyder——科学的Python开发环境_yusongcan的博客-CSDN博客_python spyder
3)一个案例
新建一个PY文件:FILE—>new file—>save as —>hello.py
写代码:
def hello():
"""Print "Hello world!" and return None """
print("Hello World!")
hello()
执行代码:run—>run 或者按F5
执行成功后,在右下角可以看到:
In [1]:
In [1]:runfile('E:/python_item/hello.py', wdir='E:/python_item')
Hello World!
In [2]:
选择Console > Open an IPython Console,启用IPython Console窗口,在右下角,有很强大的功能:
上面执行完hello.py后,就可以在这个窗口里调用hello()这个函数了,如下:
直接在右下角输入hello(),就可以执行出结果Hello World!
还可以在右下角窗口查看所有已定义的对象:dir()
再用help()来了解已建立的对象,如help(hello)
Help查询出来的信息,一部分通过检查对象获得,另一部分通过定义函数时写的文档字符串(docstring),如上面hello()里被三个单引号( ’ ’ ’ )或者三个双引号(“ ” ” )封装起来。
在spyder右上方的搜索框里也可以实现help查询,输入hello回车,或者光标放在hello()上,按快捷键CTRL+i(在MAC中按下CMD+i)。
如果另外定义一个同名的hello()函数,但是函数体不同,输出Hello new world!,按RUN或者F5后,新函数会覆盖旧函数的功能。
清除命名空间:%reset—>y(需要确认) 或者%reset –f(不需要确认)
设置PEP8规则检测警告:遵循一种编写风格
Preferences > Editor > Code Introspection/Analysis,然后勾选Style analysis(PEP8)。(python3有些微区别)
在右下角显示绘图的命令行:%matplotlib inline
通过Preferences > IPython Console > Graphics > Activate Support转换到命令行中绘图
如果看不到图表,可以用show()命令调出来。
3、spyder中一些快捷键的使用
F5执行当前文件。
Tab键自动补全命令、函数名、变量名、Console(Python和IPython)和Editor中的方法名。这个特点也很有用,将来你可能会频繁地使用。现在你就可以尝试一下这一功能。假设你定义了一个变量:
mylongvariablename = 42
假设我们需要写代码计算mylongvariablename + 100,我们只需要输入 my 然后按Tab键。如果这个变量名是唯一的,在光标位置会自动补齐变量名,然后再继续输入 + 100。如果以字母my开头的变量名不是唯一的,按下Tab键之后会列出所有以my开头的变量名以供选择,之后可以使用上下键选择,也可以输入更多的字母匹配。
Ctrl+Enter执行当前cell(在菜单中Run > Run Cell)。Cell是以#%%开头的两行之间的代码。
Shift+Enter执行当前cell并将光标移到下一个cell(菜单中选择Run > Run cell and advance)。
Cells可实现将大的文件或代码段以小单元执行。
Alt+把当前行向上移一行。如果很多行被选中,它们将被一起移动。 Alt+则是相对应的将某(些)行向下移。
Ctrl+鼠标左键 在一个函数/方法名上使用Ctrl+鼠标左键,打开一个新的editor窗口显示这个函数的定义。
Ctrl + +(Cmd + +在MacOS),将增大Editor窗口的字体,Ctrl + -则相反。在IPython窗口中也适用。
Help或者python console窗口中的字体则通过Preferences > Help设置。
Variable Explorer则没办法改变。
Ctrl + s(Cmd + s在MacOS上)保存当前Editor窗的文件。这还会在编辑器的左栏中强制更新各种警告三角形(否则它们默认2到3秒更新一次)。
Ctrl + s(Cmd + s在MacOS上)在IPython console窗将会把当前IPython会话以HTML文件保存,包括任何显示在命令行的参数。这样可以快速记录在会话中完成了什么。
(但是不能将这个HTML 文件再次加载到会话中,如果你需要这样的功能,请查看 IPython Notebook。)
Ctrl + i(Cmd + i在MacOS上),当光标在一个对象上时使用,将在help窗口显示这个对象的文档。
Ctrl + F10逐行执行代码,run current line
Ctrl + F11看某一函数具体怎么执行的,step into function or …
Ctrl + shift+F11从函数中跳出,执行下一行,run until current…
Ctrl + F12设置断点,并执行到该断点,continue execution until next breakpoint
你同样可以在console命令窗中使用如下命令控制调试进程:
n 移动到下一行;
s 进入当前语句,如果是一个函数则进入这个函数;
r 执行完当前函数的所有语句并从该函数返回;
p 打印变量的值,例如p x将打印变量x的值。
%debug:出现异常后,输入该指令开始调试模式
Exit 离开调试模式,或者Debug > Debugging Control > Exit。
4、Python语法及一些常用的算法包
python3语法笔记_aiyo92的专栏-CSDN博客 这里作者将python与java作了对比,记录了一些要点。
Python基本手册_aibotlab的博客-CSDN博客_python手册 归纳的格式很方便看
你所不知道的Python奇技淫巧 - Data&Truth - 博客园 Python的一些技巧
如何拿到半数面试公司Offer——我的Python求职之路 - Data&Truth - 博客园 从面试技巧中学习Python常用要点
笔记:
1)python的数据类型中,列表和元组近似,但是元组不能修改,都像数组一样被调用[],下标从0开始,且不算头下标,如[1:3],取的是下标为2和3的两个元素,也就是第3个和第4个元素。列表用[],元组用()。
从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
加号 + 是列表连接运算符,星号 * 是重复操作。
2)列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
3)数据类型的转换,你只需要将数据类型作为函数名即可。
4)列表(list)是一个可变的对象序列,在python里一般不区分数组和列表,列表除了能实现数组的基本功能外,还允许插入元素和删除元素,可以认为列表是高级的数组。
list中的元素是任意类型的, 可以是int、 str, 还可以是list, 甚至是dict等。
可以通过索引下标访问各项数据元素。索引即元组在数组或者列表里的位置,切片即根据索引位置提取列表或数组里的数据元素。索引从左往右从0开始,从右往左从-1开始。
序列的切片,一定要左边的数字小于右边的数字,否则返回的是空,也就是只能从左往右切片。
反转[::-1],将列表或者数组的元素反过来,得到新的列表或者数组,原来的数值并没有改变。
反转reversed():
5)append()和a[len(a):]=[x]追加是一个意思,都是在最后添加一个元素;extend()和a[len(a):]=L追加是一个意思,都是在最后添加一个列表:
>>> a=[1,2,3]
>>> b=[1,1,1]
>>> c="asd"
>>> a.append(b)
>>> a
[1, 2, 3, [1, 1, 1]]
>>> a.extend(b)
>>> a
[1, 2, 3, [1, 1, 1], 1, 1, 1]
>>> a.extend(c)
>>> a
[1, 2, 3, [1, 1, 1], 1, 1, 1, 'a', 's', 'd']
>>> a.append(c)
>>> a
[1, 2, 3, [1, 1, 1], 1, 1, 1, 'a', 's', 'd', 'asd']
extend的对象是一个list,如果是str,则Python会先把它按照字符为单位转化为list再追加到已知list。append的对象数据类型无要求。
6)pop和remove都是删除列表中的元素,不同的是pop是通过索引来删除
>>> a=[1,2,3,4,5]
>>> a.remove(2)
>>> a
[1, 3, 4, 5]
>>> a.remove(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: list.remove(x): x not in list
>>> a=[1,2,3,4,5]
>>> a.pop(2)
3
>>> a
[1, 2, 4, 5]
>>> a.pop()
5
>>> a
[1, 2, 4]
7)insert(i,x)函数,在a[i]前插入x,如果遇到i已经超过了最大索引值,会自动将所要插入的元素放到列表的尾部,即追加。如果插入的位置i为负时,则在倒是第| i |个位置前插入值。
8)sort是对列表进行排序。默认是从小到大排序,当reverse=True时,为从大到小排序。
史上最全关于sorted函数的10条总结_Python之禅-CSDN博客
9)在str.split()函数中,有两个参数,第一个就是分割符,用于拆分字符串的分隔符。默认表示根据任何空格进行拆分, 并从结果中丢弃空字符串。第二个是分割块数。默认是最大分隔块数。
>>> str="helllo,world"
>>> str.split(",")
['helllo', 'world']
>>> str.split("l",1)
['he', 'llo,world']
>>> str.split("l",4)
['he', '', '', 'o,wor', 'd']
#使用默认值进行分割
>>> s = "I am, writing\npython\tbook on line"
>>> s.split()
['I', 'am,', 'writing', 'python', 'book', 'on', 'line']
10)split()是将string转化为list,那么join就是将string转化为string。join可以说是split的逆运算。
>>> str
['using', 'sep', 'as', 'the', 'delimiter.']
>>> " ".join(str)
'using sep as the delimiter.'
>>> "-".join(str)
'using-sep-as-the-delimiter.'
11)在列表中,元素可以是任何类型,因此列表也可以由列表组成,这样就构成了二维列表,三维列表…
5、项目中常用函数及包
Pandas:
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
>>> from pandas import Series, DataFrame
>>> import pandas as pd
pd.isnull(series) 判断是否为空 pd.notnull(series) 判断是否不为空
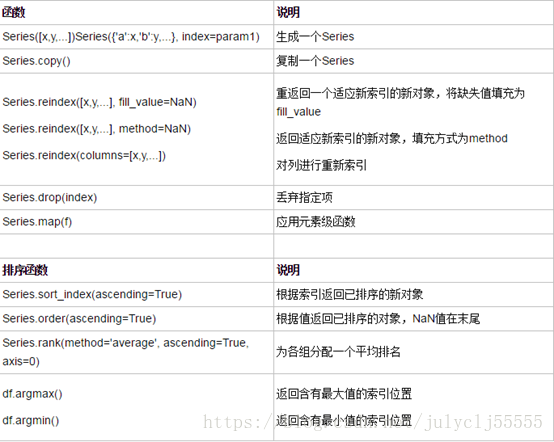
Series可以运用ndarray或字典的几乎所有索引操作和函数,融合了字典和ndarray的优点。
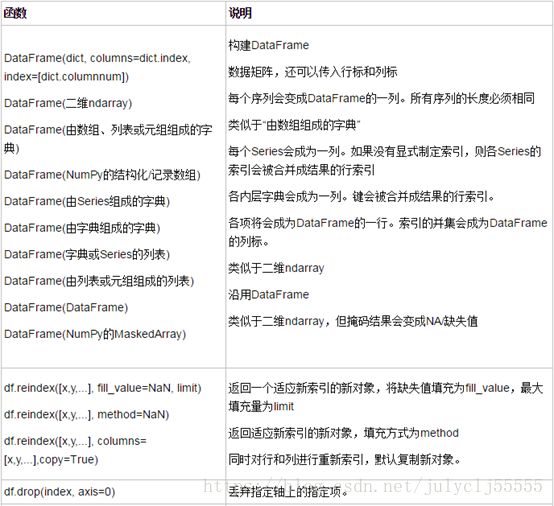
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。

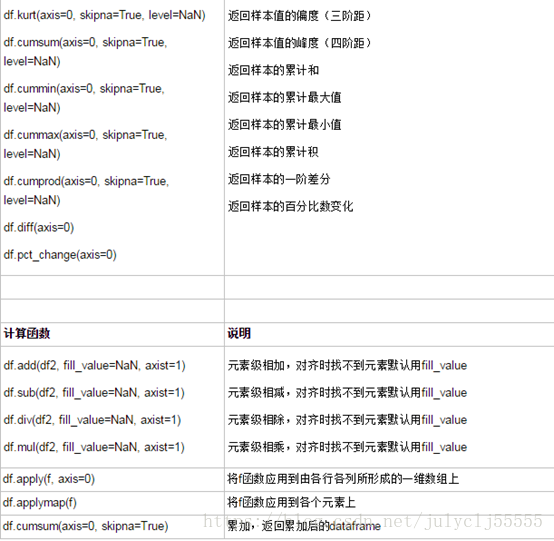
os和sys:
os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口;
sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。
os 常用方法
os.remove() 删除文件
os.rename() 重命名文件
os.walk() 生成目录树下的所有文件名
os.chdir() 改变目录
os.mkdir/makedirs 创建目录/多层目录
os.rmdir/removedirs 删除目录/多层目录
os.listdir() 列出指定目录的文件
os.getcwd() 取得当前工作目录
os.chmod() 改变目录权限
os.path.basename() 去掉目录路径,返回文件名
os.path.dirname() 去掉文件名,返回目录路径
os.path.join() 将分离的各部分组合成一个路径名
os.path.split() 返回( dirname(), basename())元组
os.path.splitext() 返回 (filename, extension) 元组
os.path.getatime\ctime\mtime 分别返回最近访问、创建、修改时间
os.path.getsize() 返回文件大小
os.path.exists() 是否存在
os.path.isabs() 是否为绝对路径
os.path.isdir() 是否为目录
os.path.isfile() 是否为文件
sys 常用方法
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.modules.keys() 返回所有已经导入的模块列表
sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息
sys.exit(n) 退出程序,正常退出时exit(0)
sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.maxunicode 最大的Unicode值
sys.modules 返回系统导入的模块字段,key是模块名,value是模块
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout 标准输出
sys.stdin 标准输入
sys.stderr 错误输出
sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix 返回平台独立的python文件安装的位置
sys.byteorder 本地字节规则的指示器,big-endian平台的值是'big',little-endian平台的值是'little'
sys.copyright 记录python版权相关的东西
sys.api_version 解释器的C的API版本
time:
用于处理时间相关的功能,还有datetime,calendar
gmtime(),localtime()和strptime()以时间元祖(struct_time)的形式返回
NumPy:
NumPy 是一个 Python 包。 它代表 “Numeric Python”。 它是一个由多维数组对象和用于处理数组的例程集合组成的库。
使用NumPy,开发人员可以执行以下操作:
数组的算数和逻辑运算。
傅立叶变换和用于图形操作的例程。
与线性代数有关的操作。 NumPy 拥有线性代数和随机数生成的内置函数。
NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用。
NumPy 中定义的最重要的对象是称为 ndarray 的 N 维数组类型。 它描述相同类型的元素集合。 可以使用基于零的索引访问集合中的项目。
ndarray中的每个元素在内存中使用相同大小的块。 ndarray中的每个元素是数据类型对象的对象(称为 dtype)。
通过import numpy as np就可以使用numpy。
如果我们希望两个列表对应项相加,则我们需要这样做,使用Python列表这样的代码是冗余的,而使用numpy则大大减少了代码的冗余。
#使用Python列表
a = [1,2,3,4]
b = [4,5,6,7,8]
out = []
for i,j in zip(a,b):
out.append(i+j)
print(out)
#output
[ 5, 7, 9, 11]
#使用numpy
import numpy as np
a = np.array([1,2,3,4])
b = np.array([4,5,6,7])
print(a+b)
#output
array([ 5, 7, 9, 11])
在Python list中,list存放的是每一项数据的索引,通过这个索引找到相应的内存地址,才能知道这个数值是多少。这就像是你想开一个party,但是你手里只有给个人的地址,你需要进入他们的房间。但numpy不同的是把所有的元素都组织到一个屋子,也就是一个数据结构中,同一个缓存中。所以这些元素在内存中是相邻的。他们都有相同的类型,numpy就能对这些数字进行非常快速的计算。因为不用做类型检查,它不需要申请获取这些元素拥有所有对象。
numpy中常用的数据类型、函数:
1、array:数值,可以直接进行运算
2、shape:返回一个元组,列出每个维度的数组长度。
3、ndim:维度
4、dtype:查看数组元素的数据类型
强制数据类型:arr = np.array([1, 2.2, 3, 4.9],dtype = 'int32')
numpy数据类型转换需要调用方法astype(),不能直接修改dtype。调用astype返回数据类型修改后的数据,但是源数据的类型不会变。
arr = np.array([1 , 2.2, 3, 4.9])
a = arr.astype(int) -- arr的数据类型不会变,a是更改后的数据类型
5、reshape:重塑,不改变原数据的情况下,重新按指定形状生成数组
如果只是单纯的想要n列,对于行数并无要求,或者只是单纯的对行数有要求,对列并无要求,则可以使用负数来进行替代。这里的复数numpy理解为未指定的。
Itertools:
操作迭代对象的函数;
count()
cycle()
repeat()
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来,事实上也不可能在内存中创建无限多个元素。所以创建迭代对象后,需要联合for语句来生成。
如:
>>> ns = itertools.repeat('A', 10)
>>> for n in ns:
... print n
...
打印10次'A'
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:如
>>> natuals = itertools.count(1)
>>> ns = itertools.takewhile(lambda x: x <= 10, natuals)
>>> for n in ns:
... print n
...
打印出1到10
常用的几个迭代函数:
chain()可以把一组迭代对象串联起来,形成一个更大的迭代器:
groupby()把迭代器中相邻的重复元素挑出来放在一起:
imap()和map()的区别在于,imap()可以作用于无穷序列,并且,如果两个序列的长度不一致,以短的那个为准。
注意imap()返回一个迭代对象,而map()返回list。当你调用map()时,已经计算完毕:
__init__()
这个方法一般用于初始化一个类
但是 当实例化一个类的时候, __init__并不是第一个被调用的, 第一个被调用的是__new__
__str__()
这是一个内置方法, 只能返回字符串, 并且只能有一个参数self
self
定义类:class Student(object):
(Object)表示该类从哪个类继承下来的,Object类是所有类都会继承的类。
由于类起到模板的作用,因此,可以在创建实例的时候,把我们认为必须绑定的属性强制填写进去。这里就用到Python当中的一个内置方法__init__方法。
(1)、__init__方法的第一参数永远是self,表示创建的类实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
(2)、有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器会自己把实例变量传进去:
(3)、如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问。
(4)、如果外部代码要获取私有变量name\score怎么办?可以给类增加get_name和get_score这样的方法。
(5)、如果又要允许外部代码修改score怎么办?可以给Student类增加set_score方法。
(6)、在Python中,变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量。
(7)、以一个下划线开头的实例变量名,比如_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
pd.read_excel
pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,
arse_cols=None,date_parser=None,na_values=None,thousands=None,
convert_float=True,has_index_names=None,converters=None,dtype=None,
true_values=None,false_values=None,engine=None,squeeze=False,**kwds)
io :excel 路径;
sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
sheet[0].values,是一个多位数组;
同样可以根据表头名称或者表的位置读取该表的数据。
header :指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None;
skiprows:省略指定行数的数据。skip_footer:省略从尾部数的行数据。
index_col :指定列为索引列,也可以使用 u’string’
names:指定列的名字,传入一个list数据。
apply
当一个函数的参数存在于一个元组或者一个字典中时,用来间接的调用这个函数,并肩元组或者字典中的参数按照顺序传递给参数.
loc和iloc
iloc和loc的不同了:loc是根据dataframe的具体标签选取列,而iloc是根据标签所在的位置,从0开始计数。
os.chdir()
os.chdir() 方法用于改变当前工作目录到指定的路径。


















 4440
4440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











