










我们都知道,牛顿说过一句名言
If I have seen further, it is by standing on the shoulders of giants.
无可否认,牛顿取得了无与匹敌的成就,人类历史上最伟大的科学家之一,但同样无可否认的是,牛顿确实吸收了大量前人的研究成果,诸如哥白尼、伽利略和开普勒等人,正因如此,联合国为了纪念伽利略首次将望远镜用作天文观测四百周年,2009年的时候,通过了”国际天文年“的决议,并选中《巨人的肩膀》(Shoulders Of Giants)作为主题曲。我想这大概是告诉后人,“吃水不忘挖井人”,牛顿的成就固然伟大,他脚下的“巨人肩膀”伽利略也同样不能忘了。
也许,“巨人肩膀”无处不在,有些人善于发现,有些人选择性失明,而牛顿的伟大之处在于他能够发现,这是伟大其一,更为重要的是,他还能自己造了梯子爬上“巨人的肩膀”,并成为一个新的“巨人肩膀”,这是伟大其二。
而回到这篇文章的主题,作为平凡人的我们,暂且先把如何发现并造了梯子云云撇开不谈,让我们先来捋一捋现在NLP当中可能的“巨人肩膀”在哪里,以及有哪些已经造好的“梯子”可供攀登,余下的,就留给那些立志成为“巨人肩膀”的人文志士们吧。
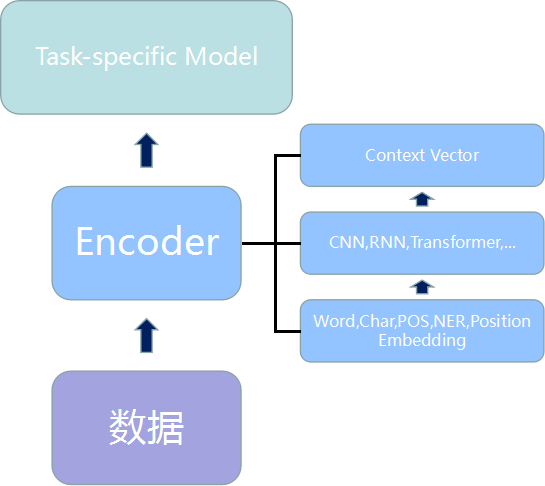
通常来说,NLP中监督任务的基本套路都可以用三个积木来进行归纳:
-
文本数据搜集和预处理
-
将文本进行编码和表征
-
设计模型解决具体任务

其中数据处理阶段自不用说,各个任务按照各自的逻辑去处理和得到相应的输入。而其中的第二阶段Encoder模块与第三阶段的Task-specific Model模块,通常来说,界限并不是特别清晰,二者之间互有渗透。而回顾过去基于深度学习的NLP任务可以发现,几乎绝大多数都比较符合这三层概念。比如很多生成任务的Seq2Seq框架中不外乎都有一个Encoder和一个Decoder,对应到这里的话Decoder更像是一个Task-specific Model,然后相应的将Encoder做一些细微的调整,比如引入Attention机制等等,对于一些文本分类任务的结构,则Encoder模块与Task-specific Model模块的区分更为明显和清晰,Encoder负责提取文本的特征,最后接上一些全连接层和Softmax层便可以当做Task-specific Model模块,如此便完成了一个文本分类任务。
既然很多的NLP任务都可以用这三个模块来进行归纳的话,并且其中数据层和Task-specific Model模块层可能根据具体任务的不同需要做一些相应的设计,而Encoder层便可以作为一个相对比较通用的模块来使用。那么自然会有一个想法,能不能类似于图像领域中的ImageNet上预训练的各种模型,来做一个NLP中预训练好的Encoder模块,然后我拿来直接利用就好了?应该说,这个想法并不难想到,NLP人也花了一些时间去思考NLP中究竟该如何设计一些更通用的可以迁移利用的东西,而不是所有的任务都要“from scratch”。因为如何尽量利用已有的知识、经验和工具,避免重复造轮子,想尽一切办法“站在巨人的肩膀上”快速发展,我想大概也是最朴素的“发展是硬道理”的体现。
为了更好的厘清这个思路,我们先来看看人类和CV(Computer Vision,计算机图像)曾经都是如何“站在巨人的肩膀上”的。
一. 人类的巨人肩膀
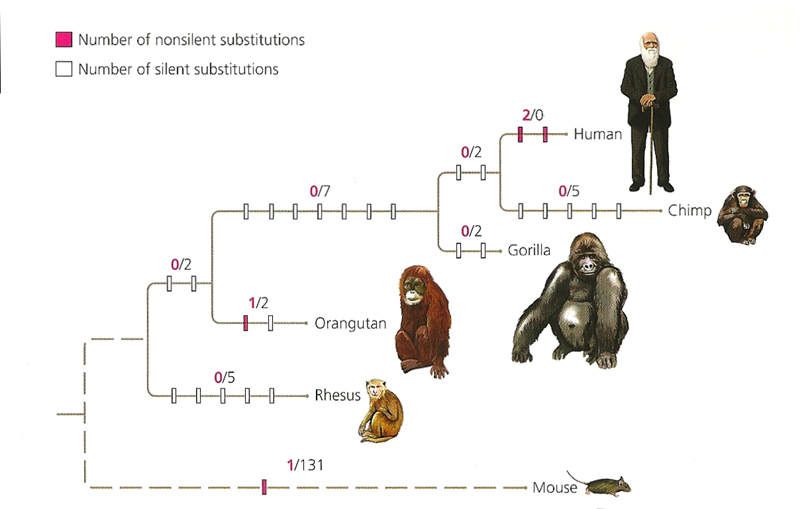
大约在20万年前,人类祖先FOXP2基因的2处(相对于其他原始猿类,如下图)极其微小却又至为关键的突变,让人类祖先逐渐拥有了语言能力,从此人类逐渐走上了一条不同于其他所有动物的文明演化之路。

而人类语言以及随后产生的文字也是人类区别于其他动物的一个至关重要的特征,它使得人类协同合作的能力变得极为强大,且让代际间经验与文化的传承效率大大提升。知名博主Tim Urban——连大佬Elon Musk都是他的铁杆粉丝——在2017年4月发表的巨长博文中(其实也是为了商业互吹Musk的Neuralink),Tim分析了为什么语言能够加速人类文明的发展,并最终从几十万年前智能生命竞赛跑道上所有一切潜在对手中大比分强势胜出。在这个过程中,语言起了非常关键的作用。在语言产生前,人类社会发展非常缓慢,表现为代际间的传承效率非常低下,而自从语言诞生以后,人类社会的发展速度得到极大的提升,这主要体现在父辈的生存技能和经验能够通过快速有效的方式传承给子辈,不仅如此,在同辈之间通过语言的沟通和交流,宝贵的经验也能够通过语言这种高效的媒介迅速传播到原始部落的每一个角落。于是,人类的每一代都能够得以在他们的父辈打下的江山上,一日千里,终成这颗蓝色星球上的无二霸主。

Knowledge-growth-graph-1b.png

Knowledge-growth-graph-2-1.png
不过,我觉得Urban想说却并没有说出来的是,即便在人类语言诞生之前,人类祖先也可以通过可能已经先于语言而诞生的学习与认知能力,做到以“代”为单位来进行传承与进化,只不过不同于基因进化,这是一种地球生命全新的进化方式,在效率上已经比其他生物的进化效率高的多得多。地球上自生命诞生以来一直被奉为圭臬的基因进化法则,往往都是以一个物种为单位,上一代花了生命代价学习到的生存技能需要不断的通过非常低效的“优胜劣汰,适者生存”的丛林法则,写进到该物种生物的基因中才算完事,而这往往需要几万年乃至几百万年才能完成。而在这个过程中,比其他物种强得多的学习能力是人类制胜的关键。
上面两个事实,前者说明了语言是加速文明进化的润滑剂,而后者说明了强大的学习能力是人类走出一条有人类特色的发展之路,从而脱离基因进化窠臼的最为重要的因素。
也就是说,对于人类而言,他们的父辈,同辈,以及一切同类,乃至大自然万事万物都是他们的“巨人肩膀”;而语言和学习能力则是人类能够站上“巨人肩膀”的“梯子”。
回到本文的主题,对于人类的钢铁“儿子”AI来说,CV和NLP是当前AI最火爆的两个领域之二,一个要解决钢铁“儿子”的视觉功能,一个要解决钢铁“儿子”的语言或认知能力,那么什么又是这个钢铁“儿子”的“巨人肩膀”和“梯子”呢?我们先来看看CV中的情况。
二. CV的巨人肩膀
ImageNet是2009年由李飞飞团队邓嘉等人提出,并迅速发展成为CV领域最知名的比赛ILSVRC,从2010年举办第一届,到2017年李飞飞宣布最后一届,前后总共举办8年,这八年间先后在这个比赛中涌现了一大批推动AI领域尤其是CV领域大发展的算法和模型。特别值得一提的是2012年Hinton团队提出了AlexNet,超过当时第二名效果41%,一下子引爆了AI领域,因此2012年也被称为“深度学习元年”。


随之而来,大家发现如果用已经在ImageNet中训练好的模型,并用这些模型中的参数来初始化新任务中的模型,可以显著的提升新任务下的效果。这种站在“巨人肩膀”上的方法已经被成功运用到很多CV任务中,诸如物体检测和语义分割等,不仅如此,更为重要的是,这种充分使用预训练模型的方法可以非常便利的迁移到一些获取标注数据较为困难的新场景中,从而极大的改善模型对标注数据数量的要求,并降低标注数据的成本。因此,利用大规模数据集预训练模型进行迁移学习的方法被认为是CV中的标配,以至于2018年的早些时候,大神何凯明所在的FAIR团队利用Instgram中数十亿张带有用户标签的图片进行预训练,尔后将其在ImageNet的比赛任务中进行fine-tune,取得了最好的成绩(见引用5)。只不过,由于预训练的数据过于庞大,该工作动用了336块GPU预训练了22天,不得不说实在都是土豪们才玩得动的游戏,这一点和下文要介绍的NLP中的预训练步骤何其相似。
不过为何这种预训练的模式能够有效?这背后有什么更深刻的内涵吗?为此,Google Brain团队将2014年的ImageNet冠军GoogleNet的中间层进行了可视化,可以发现模型的较低层学习到的主要是物体的边缘,往高层后逐步就变成了成型的物体了。一般来说,物体的边缘和纹路都是一些比较通用的视觉特征,因此将这一部分对应的模型参数用来初始化task-specific模型中的参数,意味着模型就不需要再从头开始学习这些特征,从而大大提升了训练的效率和性能。

总结起来就是,CV中的“巨人肩膀”是ImageNet以及由之而来Google等公司或团队在大规模数据集上预训练得到的模型,而“梯子”便是transfer learning之下的fine-tuning。
三. 寻找NLP的巨人肩膀
和CV领域中深度学习的惊艳表现相比,对于NLP任务来讲,深度学习的应用一直没有带来让人眼前特别一亮的表现。ImageNet中的图片分类任务,深度学习早已超越人类的分类准确率,而这一目标对于NLP中的深度学习来说,似乎成了不太可能完成的任务,尤其是在那些需要深层语义理解的任务当中,更是如此。但即便如此,困难从来未曾阻止人类想要教给他“儿子”理解“长辈”的话并开口说“人话”的雄心,忧心忡忡的人类家长恨不得也给AI来一次FOXP2基因突变——正像20万年前上帝的一次神来之笔给人类带来了语言能力一样。
今年(2018年)九月份,DeepMind主办的Deep Learning Indaba 2018 大会在南非举行,ULMFit(下文会做介绍)的作者之一Sebastian Ruder在大会上做了一个很精彩的名为《Frontiers of Natural Language Processing》的报告(引用8),前后分为两个部分:第一部分梳理近些年NLP的发展;第二部分探讨了当前NLP遇到的一些困难。在参考这个报告的同时,并回到本文最开头,这里将主要着重于NLP中最为重要的Encoder模块,并抛去具体的模型之争(诸如CNN,RNN和Transformer等等),想要努力梳理出一条NLP任务中如何更有效站上“巨人肩膀”的一些模式出来。
本质上,自然语言理解NLU的核心问题其实就是如何从语言文字的表象符号中抽取出来蕴含在文字背后的真实意义,并将其用计算机能够读懂的方式表征出来——当然这通常对应的是数学语言,表征是如此重要,以至于2012年的时候Yoshua Bengio自己作为第一作者发表了一篇表征学习的综述(引用9),并随后在2013年和深度学习三大巨头的另一位巨头Yann LeCun牵头创办ICLR,这一会议至今才过去5年时间,如今已是AI领域最负盛名的顶级会议之一。可以说,探究NLP或NLU的历史,也可以说同样也是探究文本如何更有效表征的历史。而这一过程,可以根据word2vec的出现和使用,大致分为前word2vec时代和word2vec时代两个阶段。我们先来看看前word2vec时代都发生了哪些事情。
1. 梯子出现之前
犹如生命的诞生之初,混沌而原始。在word2vec诞生之前,NLP中并没有一个统一的方法去表示一段文本,各位前辈和大师们发明了许多的方法:从one-hot表示一个词到用bag-of-words来表示一段文本,从k-shingles把一段文本切分成一些文字片段到汉语中用各种序列标注方法将文本按语义进行分割,从tf-idf中用频率的手段来表征词语的重要性到text-rank中借鉴了page-rank的方法来表征词语的权重,从基于SVD纯数学分解词文档矩阵的LSA,到pLSA中用概率手段来表征文档形成过程并将词文档矩阵的求解结果赋予概率含义,再到LDA中引入两个共轭分布从而完美引入先验......
1.1 语言模型
而以上这些都是相对比较传统的方法,在介绍基于深度学习的方法之前,先来看看语言模型。实际上,语言模型的本质是对一段自然语言的文本进行预测概率的大小,即如果文本用 
 转存失败重新上传取消 来表示,那么语言模型就是要求
转存失败重新上传取消 来表示,那么语言模型就是要求  转存失败重新上传取消 的大小,如果按照大数定律中频率对于概率无限逼近的思想,求这个概率大小,自然要用这个文本在所有人类历史上产生过的所有文本集合中,先求这个文本的频率 转存失败重新上传取消,尔后便可以通过如下公式来求得
转存失败重新上传取消 的大小,如果按照大数定律中频率对于概率无限逼近的思想,求这个概率大小,自然要用这个文本在所有人类历史上产生过的所有文本集合中,先求这个文本的频率 转存失败重新上传取消,尔后便可以通过如下公式来求得

这个公式足够简单,但问题是全人类所有历史的语料这种统计显然无法实现,因此为了将这个不可能的统计任务变得可能,首先有人将文本不当做一个整体,而是把它拆散成一个个的词,通过每个词之间的概率关系,从而求得整个文本的概率大小。假定句子长度为 转存失败重新上传取消,词用
转存失败重新上传取消,词用 转存失败重新上传取消表示,即
转存失败重新上传取消表示,即

然而,这个式子的计算依然过于复杂,我们一般都会引入马尔科夫假设:假定一个句子中的词只与它前面的 转存失败重新上传取消个词相关,特别地,当
转存失败重新上传取消个词相关,特别地,当 转存失败重新上传取消的时候,句子的概率计算公式最为简洁:
转存失败重新上传取消的时候,句子的概率计算公式最为简洁:

并且把词频的统计用来估计这个语言模型中的条件概率,如下

这样一来,语言模型的计算终于变得可行。然而,这种基于统计的语言模型却存在很多问题:
第一,很多情况下 转存失败重新上传取消的计算会遇到特别多零值,尤其是在 转存失败重新上传取消 取值比较大的情况下,这种数据稀疏导致的计算为0的现象变得特别严重。所以统计语言模型中一个很重要的方向便是设计各种平滑方法来处理这种情况。
转存失败重新上传取消的计算会遇到特别多零值,尤其是在 转存失败重新上传取消 取值比较大的情况下,这种数据稀疏导致的计算为0的现象变得特别严重。所以统计语言模型中一个很重要的方向便是设计各种平滑方法来处理这种情况。
第二, 另一个更为严重的问题是,基于统计的语言模型无法把转存失败重新上传取消取得很大,一般来说在3-gram比较常见,再大的话,计算复杂度会指数上升。这个问题的存在导致统计语言模型无法建模语言中上下文较长的依赖关系。
第三,统计语言模型无法表征词语之间的相似性。
1.2 NNLM
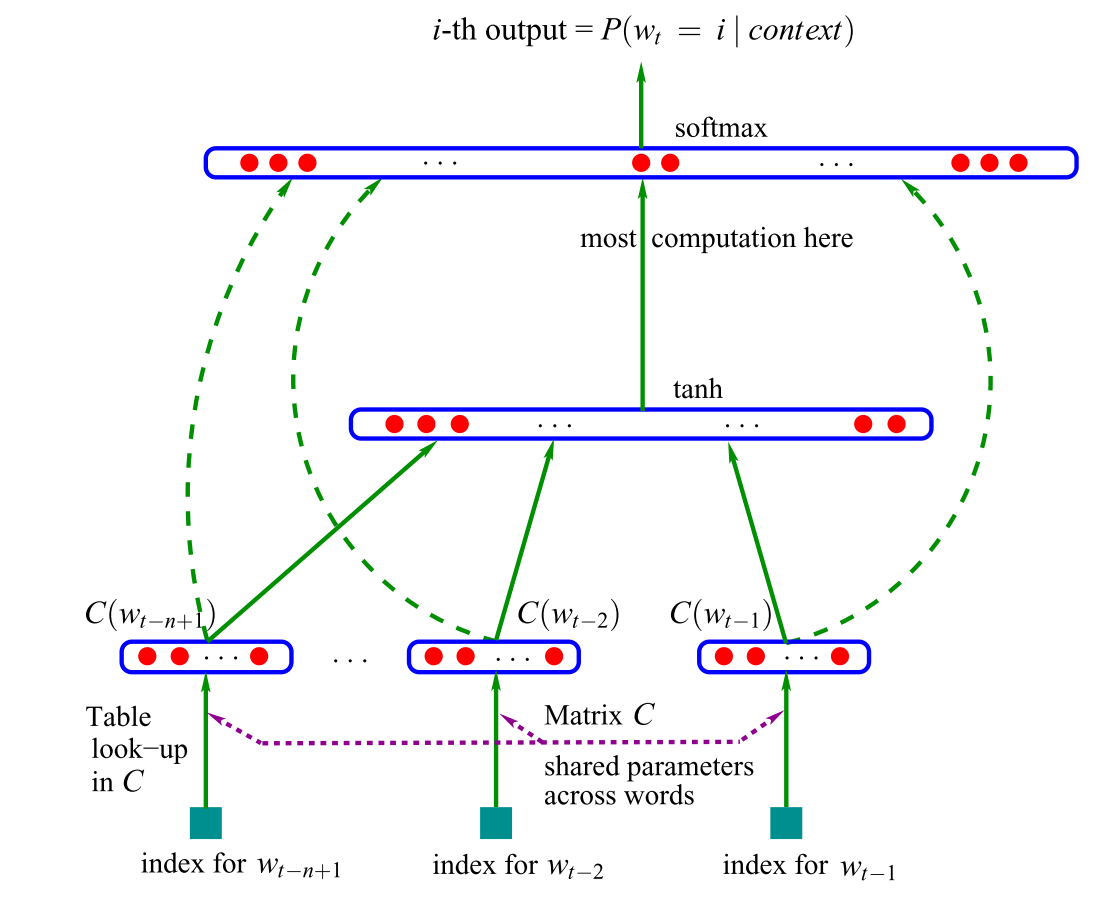
这些缺点的存在,迫使2003年Bengio在他的经典论文《A Neural Probabilistic Language Model》中,首次将深度学习的思想融入到语言模型中,并发现将训练得到的NNLM(Neural Net Language Model, 神经网络语言模型)模型的第一层参数当做词的分布式表征时,能够很好的获取词语之间的相似度。

撇去正则化项,NNLM的极大目标函数对数似然函数,其本质上是个N-Gram的语言模型,如下所示


其中,归一化之前的概率大小(也就是logits)为


x实际上就是将每个词映射为m维的向量,然后将这 转存失败重新上传取消个词的向量concat起来,组合成一个
转存失败重新上传取消个词的向量concat起来,组合成一个  转存失败重新上传取消 维的向量。这里可以将NNLM的网络结构拆分为三个部分:
转存失败重新上传取消 维的向量。这里可以将NNLM的网络结构拆分为三个部分:
第一部分,从词到词向量的映射,通过C矩阵完成映射,参数个数为  转存失败重新上传取消;
转存失败重新上传取消;
第二部分,从x到隐藏层的映射,通过矩阵H,这里的参数个数为  转存失败重新上传取消;
转存失败重新上传取消;
第三部分,从隐藏层到输出层的映射,通过矩阵U,参数个数为 转存失败重新上传取消
转存失败重新上传取消
第四部分,从x到输出层的映射,通过矩阵W,参数个数为 转存失败重新上传取消;
转存失败重新上传取消;
因此,如果算上偏置项的参数个数(其中输出层为 转存失败重新上传取消,输入层到隐藏层为
转存失败重新上传取消,输入层到隐藏层为 转存失败重新上传取消)的话,NNLM的参数个数为:
转存失败重新上传取消)的话,NNLM的参数个数为:

可见NNLM的参数个数是所取窗口大小n的线性函数,这便可以让NNLM能够对更长的依赖关系进行建模。不过NNLM的最主要贡献是非常有创见性的将模型的第一层特征映射矩阵当做词的分布式表示,从而可以将一个词表征为一个向量形式,这直接启发了后来的word2vec的工作。
这许多的方法和模型正如动荡的春秋战国,诸子百家群星闪耀,然而却也谁都未能有绝对的实力统一当时的学术界。即便到了秦始皇,虽武力空前强大,踏平六国,也有车同轨书同文的壮举,却依然未能把春秋以降的五彩缤纷的思想学术界统一起来,直到历史再历一百年,汉武帝终于完成了这个空前绝后的大手笔,“罢黜百家独尊儒术”,这也直接成为了华夏文化的核心基础。不禁要问,如果把NNLM当做文化统一前的“书同文”苗头,那NLP中的“独尊儒术”在哪里?
2. 历史突破——梯子来了
自NNLM于2003年被提出后,后面又出现了很多类似和改进的工作,诸如LBL, C&W和RNNLM模型等等,这些方法主要从两个方面去优化NNLM的思想,其一是NNLM只用了左边的转存失败重新上传取消个词,如何利用更多的上下文信息便成为了很重要的一个优化思路(如Mikolov等人提出的RNNLM);其二是NNLM的一个非常大的缺点是输出层计算量太大,如何减小计算量使得大规模语料上的训练变得可行,这也是工程应用上至关重要的优化方向(如Mnih和Hinton提出的LBL以及后续的一系列模型)。
为了更好理解NNLM之后以及word2vec诞生前的情况,我们先来看看现有的几个主要模型都有哪些优缺点。
NNLM虽然将N-Gram的阶n提高到了5,相比原来的统计语言模型是一个很大的进步,但是为了获取更好的长程依赖关系,5显然是不够的。再者,因为NNLM只对词的左侧文本进行建模,所以得到的词向量并不是语境的充分表征。还有一个问题就更严重了,NNLM的训练依然还是太慢,在论文中,Bengio说他们用了40块CPU,在含有1400万个词,只保留词频相对较高的词之后词典大小为17964个词,只训练了5个epoch,但是耗时超过3周。按这么来算,如果只用一块CPU,可能需要2年多,这还是在仅有1400万个词的语料上。如此耗时的训练过程,显然严重限制了NNLM的应用。
2007年Mnih和Hinton提出的LBL以及后续的一系列相关模型,省去了NNLM中的激活函数,直接把模型变成了一个线性变换,尤其是后来将Hierarchical Softmax引入到LBL后,训练效率进一步增强,但是表达能力不如NNLM这种神经网络的结构;2008年Collobert和Weston
提出的C&W模型不再利用语言模型的结构,而是将目标文本片段整体当做输入,然后预测这个片段是真实文本的概率,所以它的工作主要是改变了目标输出,由于输出只是一个概率大小,不再是词典大小,因此训练效率大大提升,但由于使用了这种比较“别致”的目标输出,使得它的词向量表征能力有限;2010年Mikolov(对,还是同一个Mikolov)提出的RNNLM主要是为了解决长程依赖关系,时间复杂度问题依然存在。

wordembedding_computing_complexity.png
而这一切,似乎都在预示着一个新时代的来临。
2.1 CBOW和Skip-gram
2013年,Tomas Mikolov连放几篇划时代的论文,其中最为重要的是两篇,《Efficient estimation of word representations in vector space》首次提出了CBOW和Skip-gram模型,进一步的在《Distributed Representations of Words and Phrases and their Compositionality》中,又介绍了几种优化训练的方法,包括Hierarchical Softmax(当然,这个方法早在2003年,Bengio就在他提出NNLM论文中的Future Work部分提到了这种方法,并于2005年把它系统化发表了一篇论文), Negative Sampling和Subsampling技术。放出两篇论文后,当时仍在谷歌工作的Mikolov又马不停蹄的放出了大杀器——word2vec工具,并在其中开源了他的方法。顺便提一下的是,很多人以为word2vec是一种模型和方法,其实word2vec只是一个工具,背后的模型是CBOW或者Skip-gram,并且使用了Hierarchical Softmax或者Negative Sampling这些训练的优化方法。所以准确说来,word2vec并不是一个模型或算法,只不过Mikolov恰好在当时把他开源的工具包起名叫做word2vec而已。不过为了叙述简单,在下文我将用word2vec来指代上面提到Mikolov两篇论文中的一整个相关的优化思想。
word2vec对于前人的优化,主要是两方面的工作:模型的简化和训练技巧的优化。我们先来看看模型的简化方面,也就是耳熟能详的CBOW和Skip-gram。
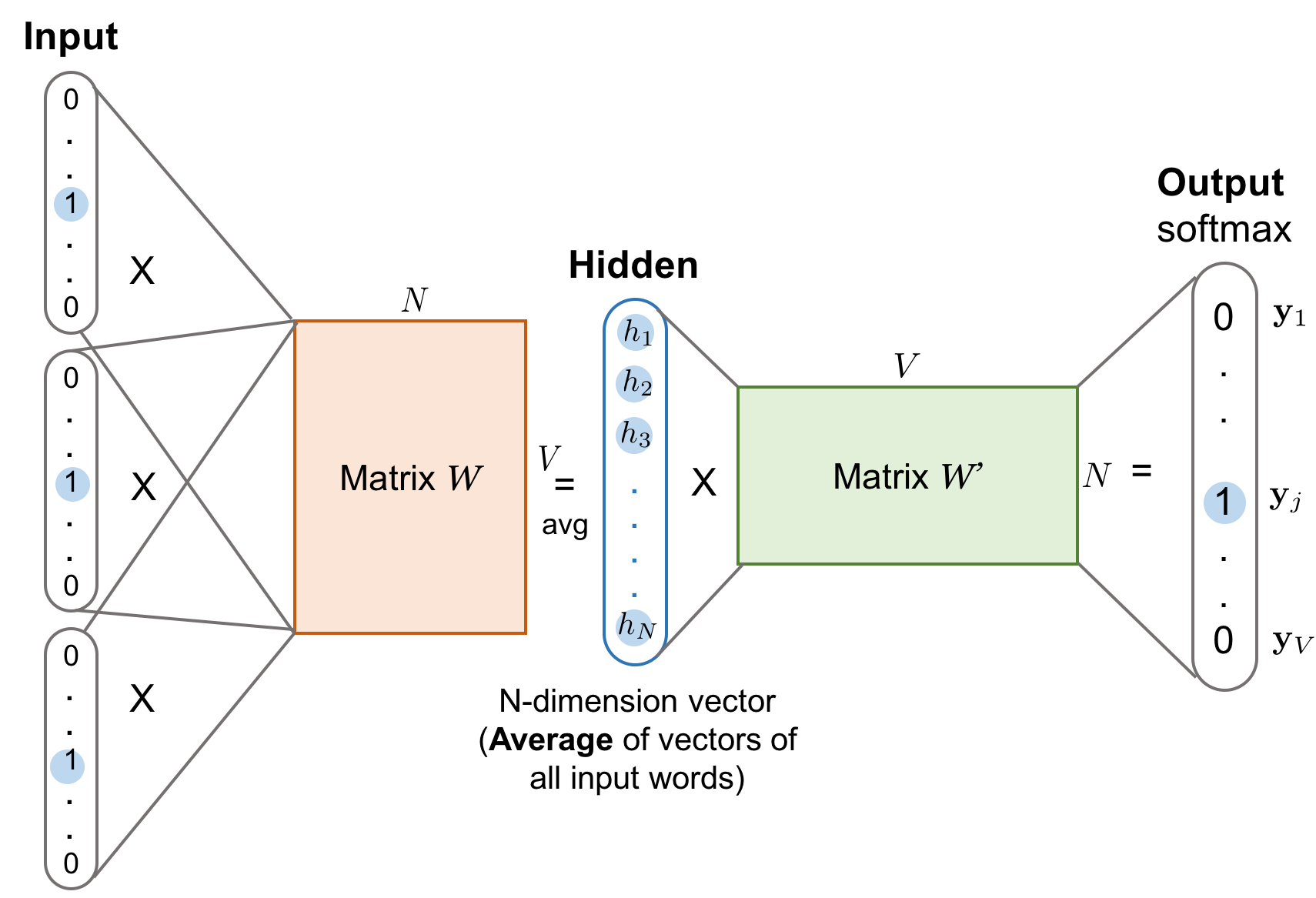
对于CBOW而言,我们可以从它的名字上一窥究竟,它的全称是Continuous Bag-of-Words,也就是连续的词袋模型,为什么取这个名字,先来看看它的目标函数。


首先,CBOW没有隐藏层,本质上只有两层结构,输入层将目标词语境 转存失败重新上传取消中的每一个词向量简单求和(当然,也可以求平均)后得到语境向量,然后直接与目标词的输出向量求点积,目标函数也就是要让这个与目标词向量的点积取得最大值,对应的与非目标词的点积尽量取得最小值。从这可以看出,CBOW的第一个特点是取消了NNLM中的隐藏层,直接将输入层和输出层相连;第二个特点便是在求语境context向量时候,语境内的词序已经丢弃(这个是名字中Continuous的来源);第三,因为最终的目标函数仍然是语言模型的目标函数,所以需要顺序遍历语料中的每一个词(这个是名字中Bag-of-Words的来源)。因此有了这些特点(尤其是第二点和第三点),Mikolov才把这个简单的模型取名叫做CBOW,简单却有效的典范。
转存失败重新上传取消中的每一个词向量简单求和(当然,也可以求平均)后得到语境向量,然后直接与目标词的输出向量求点积,目标函数也就是要让这个与目标词向量的点积取得最大值,对应的与非目标词的点积尽量取得最小值。从这可以看出,CBOW的第一个特点是取消了NNLM中的隐藏层,直接将输入层和输出层相连;第二个特点便是在求语境context向量时候,语境内的词序已经丢弃(这个是名字中Continuous的来源);第三,因为最终的目标函数仍然是语言模型的目标函数,所以需要顺序遍历语料中的每一个词(这个是名字中Bag-of-Words的来源)。因此有了这些特点(尤其是第二点和第三点),Mikolov才把这个简单的模型取名叫做CBOW,简单却有效的典范。

需要注意的是这里每个词对应到两个词向量,在上面的公式中都有体现,其中 转存失败重新上传取消是词的输入向量,而
转存失败重新上传取消是词的输入向量,而 转存失败重新上传取消则是词的输出向量,或者更准确的来讲,前者是CBOW输入层中跟词
转存失败重新上传取消则是词的输出向量,或者更准确的来讲,前者是CBOW输入层中跟词 转存失败重新上传取消所在位置相连的所有边的权值(其实这就是词向量)组合成的向量,而是输出层中与词转存失败重新上传取消所在位置相连的所有边的权值组合成的向量,所以把这一向量叫做输出向量。
转存失败重新上传取消所在位置相连的所有边的权值(其实这就是词向量)组合成的向量,而是输出层中与词转存失败重新上传取消所在位置相连的所有边的权值组合成的向量,所以把这一向量叫做输出向量。
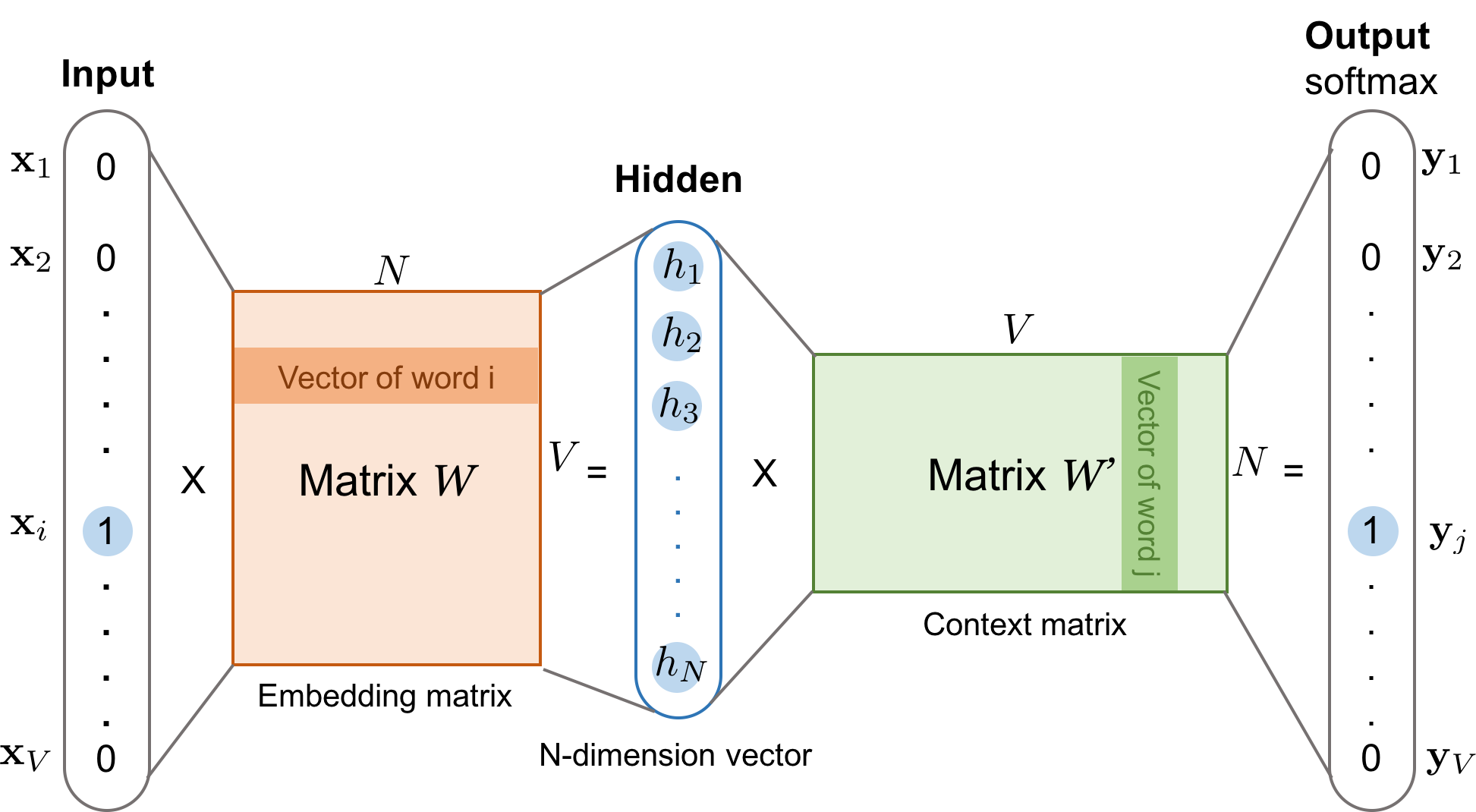
同样地,和CBOW对应,Skip-gram的模型基本思想和CBOW非常类似,只是换了一个方向:CBOW是让目标词的输出向量转存失败重新上传取消拟合语境的向量转存失败重新上传取消;而Skip-gram则是让语境中每个词的输出向量尽量拟合当前输入词的向量转存失败重新上传取消,和CBOW的方向相反,因此它的目标函数如下:


可以看出目标函数中有两个求和符号,最里面的求和符号的意义便是让当前的输入词分别和该词对应语境中的每一个词都尽量接近,从而便可以表现为该词与其上下文尽量接近。

和CBOW类似,Skip-gram本质上也只有两层:输入层和输出层,输入层负责将输入词映射为一个词向量,输出层负责将其经过线性映射计算得到每个词的概率大小。再细心一点的话,其实无论CBOW还是Skip-gram,本质上都是两个全连接层的相连,中间没有 任何其他的层。因此,这两个模型的参数个数都是 转存失败重新上传取消,其中
转存失败重新上传取消,其中 转存失败重新上传取消分别是词向量的维度和词典的大小,相比上文中我们计算得到NNLM的参数个数
转存失败重新上传取消分别是词向量的维度和词典的大小,相比上文中我们计算得到NNLM的参数个数 转存失败重新上传取消已经大大减小,且与上下文所取词的个数无关了,也就是终于避免了N-gram中随着阶数N增大而使得计算复杂度急剧上升的问题。
转存失败重新上传取消已经大大减小,且与上下文所取词的个数无关了,也就是终于避免了N-gram中随着阶数N增大而使得计算复杂度急剧上升的问题。
然而,Mikolov大神说了,这些公式是“impractical”的,他的言下之意是计算复杂度依然和词典大小有关,而这通常都意味着非常非常大,以下是他的原话
..., and W is the number of words in the vocabulary. This formulation is impractical because the cost of computing ∇ log p(wO|wI ) is proportional to W, which is often large (105–107 terms).
不得不说,大神就是大神,将模型已经简化到了只剩两个全连接层(再脱就没了),依然不满足,还“得寸进尺”地打起了词典的“小算盘”,那么Mikolov的“小算盘”是什么呢?
他在论文中首先提到了Hierachical Softmax,认为这是对full softmax的一种优化手段,而Hierachical Softmax的基本思想就是首先将词典中的每个词按照词频大小构建出一棵Huffman树,保证词频较大的词处于相对比较浅的层,词频较低的词相应的处于Huffman树较深层的叶子节点,每一个词都处于这棵Huffman树上的某个叶子节点;第二,将原本的一个转存失败重新上传取消分类问题变成了 转存失败重新上传取消次的二分类问题,做法简单说来就是,原先要计算
转存失败重新上传取消次的二分类问题,做法简单说来就是,原先要计算 转存失败重新上传取消的时候,因为使用的是普通的softmax,势必要求词典中的每一个词的概率大小,为了减少这一步的计算量,在Hierachical Softmax中,同样是计算当前词转存失败重新上传取消在其上下文中的概率大小,只需要把它变成在Huffman树中的路径预测问题就可以了,因为当前词转存失败重新上传取消在Huffman树中对应到一条路径,这条路径由这棵二叉树中从根节点开始,经过一系列中间的父节点,最终到达当前这个词的叶子节点而组成,那么在每一个父节点上,都对应的是一个二分类问题(本质上就是一个LR分类器),而Huffman树的构造过程保证了树的深度为转存失败重新上传取消,所以也就只需要做转存失败重新上传取消次二分类便可以求得转存失败重新上传取消的大小,这相比原来转存失败重新上传取消次的计算量,已经大大减小了。
转存失败重新上传取消的时候,因为使用的是普通的softmax,势必要求词典中的每一个词的概率大小,为了减少这一步的计算量,在Hierachical Softmax中,同样是计算当前词转存失败重新上传取消在其上下文中的概率大小,只需要把它变成在Huffman树中的路径预测问题就可以了,因为当前词转存失败重新上传取消在Huffman树中对应到一条路径,这条路径由这棵二叉树中从根节点开始,经过一系列中间的父节点,最终到达当前这个词的叶子节点而组成,那么在每一个父节点上,都对应的是一个二分类问题(本质上就是一个LR分类器),而Huffman树的构造过程保证了树的深度为转存失败重新上传取消,所以也就只需要做转存失败重新上传取消次二分类便可以求得转存失败重新上传取消的大小,这相比原来转存失败重新上传取消次的计算量,已经大大减小了。
接着,Mikolov又提出了负采样的思想,而这一思想也是受了C&W模型中构造负样本方法启发,同时参考了Noise Contrastive Estimation (NCE)的思想,用CBOW的框架简单来讲就是,负采样每遍历到一个目标词,为了使得目标词的概率转存失败重新上传取消最大,根据softmax函数的概率公式,也就是让分子中的 转存失败重新上传取消最大,而分母中其他非目标词的
转存失败重新上传取消最大,而分母中其他非目标词的 转存失败重新上传取消最小,普通softmax的计算量太大就是因为它把词典中所有其他非目标词都当做负例了,而负采样的思想特别简单,就是每次按照一定概率随机采样一些词当做负例,从而就只需要计算这些负采样出来的负例了,那么概率公式便相应变为
转存失败重新上传取消最小,普通softmax的计算量太大就是因为它把词典中所有其他非目标词都当做负例了,而负采样的思想特别简单,就是每次按照一定概率随机采样一些词当做负例,从而就只需要计算这些负采样出来的负例了,那么概率公式便相应变为

仔细和普通softmax进行比较便会发现,将原来的转存失败重新上传取消分类问题变成了 转存失败重新上传取消分类问题,这便把词典大小对时间复杂度的影响变成了一个常数项,而改动又非常的微小,不可谓不巧妙。
转存失败重新上传取消分类问题,这便把词典大小对时间复杂度的影响变成了一个常数项,而改动又非常的微小,不可谓不巧妙。
除此之外,Mikolov还提到了一些其他技巧,比如对于那些超高频率的词,尤其是停用词,可以使用Subsampling的方法进行处理,不过这已经不是word2vec最主要的内容了。
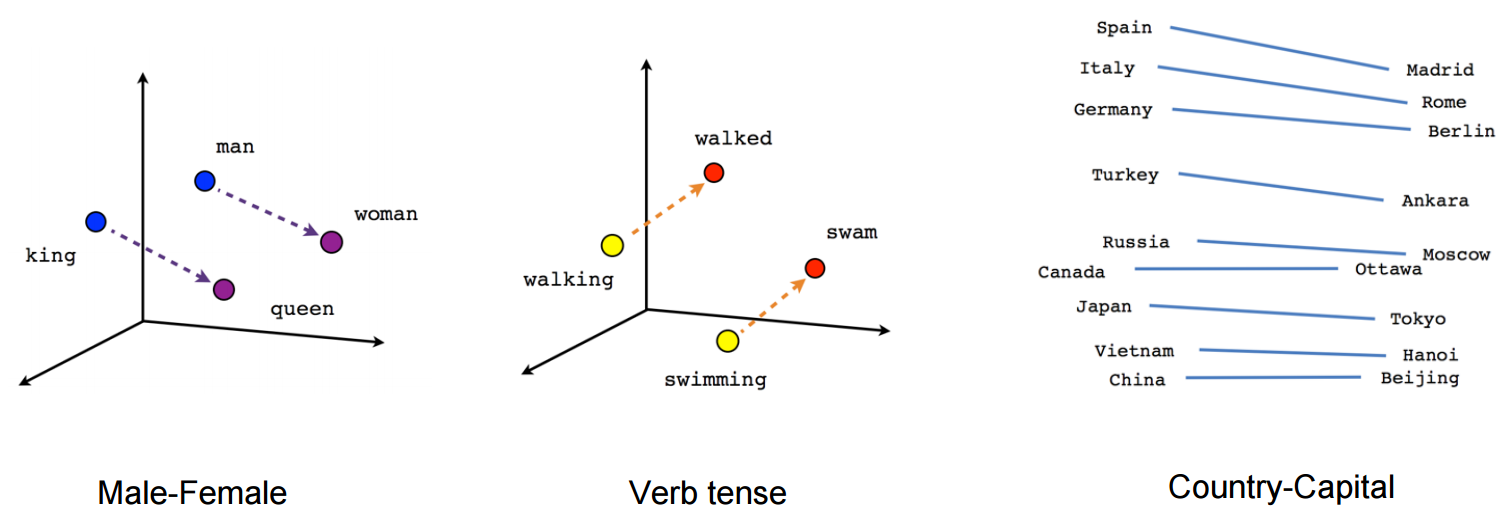
自此,经过模型和训练技巧的双重优化,终于使得大规模语料上的训练成为了现实,更重要的是,得到的这些词向量能够在语义上有非常好的表现,能将语义关系通过向量空间关系表征出来。

word2vec的出现,极大的促进了NLP的发展,尤其是促进了深度学习在NLP中的应用(不过有意思的是,word2vec算法本身其实并不是一个深度模型,它只有两层全连接),利用预训练好的词向量来初始化网络结构的第一层几乎已经成了标配,尤其是在只有少量监督数据的情况下,如果不拿预训练的embedding初始化第一层,几乎可以被认为是在蛮干。在此之后,一大批word embedding方法大量涌现,比较知名的有GloVe和fastText等等,它们各自侧重不同的角度,并且从不同的方向都得到了还不错的embedding表征。
2.2 GloVe
先来看看GloVe的损失函数,

其中 转存失败重新上传取消是两个词
转存失败重新上传取消是两个词 转存失败重新上传取消和
转存失败重新上传取消和 转存失败重新上传取消在某个窗口大小中的共现频率(不过GloVe对其做了一些改进,共现频率相应有一个衰减系数,使得距离越远的词对共现频率越小一些),
转存失败重新上传取消在某个窗口大小中的共现频率(不过GloVe对其做了一些改进,共现频率相应有一个衰减系数,使得距离越远的词对共现频率越小一些), 转存失败重新上传取消是一个权重系数,主要目的是共现越多的pair对于目标函数贡献应该越大,但是又不能无限制增大,所以对共现频率过于大的pair限定最大值,以防训练的时候被这些频率过大的pair主导了整个目标函数,剩下的就是算法的核心部分了,两个
转存失败重新上传取消是一个权重系数,主要目的是共现越多的pair对于目标函数贡献应该越大,但是又不能无限制增大,所以对共现频率过于大的pair限定最大值,以防训练的时候被这些频率过大的pair主导了整个目标函数,剩下的就是算法的核心部分了,两个 转存失败重新上传取消值是两个偏置项,撇去不谈,那么剩下的
转存失败重新上传取消值是两个偏置项,撇去不谈,那么剩下的 转存失败重新上传取消其实就是一个普通的均方误差函数,
转存失败重新上传取消其实就是一个普通的均方误差函数, 转存失败重新上传取消是当前词的向量,
转存失败重新上传取消是当前词的向量, 转存失败重新上传取消对应的是与其在同一个窗口中出现的共现词的词向量,两者的向量点乘要去尽量拟合它们共现频率的对数值。从直观上理解,如果两个词共现频率越高,那么其对数值当然也越高,因而算法要求二者词向量的点乘也越大,而二个词向量的点乘越大,其实包含了两层含义:第一,要求各自词向量的模越大,通常来说,除去频率非常高的词(比如停用词),对于有明确语义的词来说,它们的词向量模长会随着词频增大而增大,因此两个词共现频率越大,要求各自词向量模长越大是有直觉意义的,比如“魑魅魍魉”假如能被拆分成两个词,那么“魑魅”和“魍魉”这两个词的共现频率相比““魑魅”和其他词的共现频率要大得多,对应到“魑魅”的词向量,便会倾向于在某个词向量维度上持续更新,进而使得它的模长也会比较偏大;第二,要求这两个词向量的夹角越小,这也是符合直觉的,因为出现在同一个语境下频率越大,说明这两个词的语义越接近,因而词向量的夹角也偏向于越小。
转存失败重新上传取消对应的是与其在同一个窗口中出现的共现词的词向量,两者的向量点乘要去尽量拟合它们共现频率的对数值。从直观上理解,如果两个词共现频率越高,那么其对数值当然也越高,因而算法要求二者词向量的点乘也越大,而二个词向量的点乘越大,其实包含了两层含义:第一,要求各自词向量的模越大,通常来说,除去频率非常高的词(比如停用词),对于有明确语义的词来说,它们的词向量模长会随着词频增大而增大,因此两个词共现频率越大,要求各自词向量模长越大是有直觉意义的,比如“魑魅魍魉”假如能被拆分成两个词,那么“魑魅”和“魍魉”这两个词的共现频率相比““魑魅”和其他词的共现频率要大得多,对应到“魑魅”的词向量,便会倾向于在某个词向量维度上持续更新,进而使得它的模长也会比较偏大;第二,要求这两个词向量的夹角越小,这也是符合直觉的,因为出现在同一个语境下频率越大,说明这两个词的语义越接近,因而词向量的夹角也偏向于越小。

glove.png
此外,可以从GloVe使用的损失函数中发现,它的训练主要是两个步骤:统计共现矩阵和训练获取词向量,这个过程其实是没有我们通常理解当中的模型的,更遑论神经网络,它整个的算法框架都是基于矩阵分解的做法来获取词向量的,本质上和诸如LSA这种基于SVD的矩阵分解方法没有什么不同,只不过SVD分解太过于耗时,运算量巨大,相同点是LSA也是输入共现矩阵,不过一般主要以词-文档共现矩阵为主,另外,LSA中的共现矩阵没有做特殊处理,而GloVe考虑到了对距离较远的词对做相应的惩罚等等。然而,相比word2vec,GloVe却更加充分的利用了词的共现信息,word2vec中则是直接粗暴的让两个向量的点乘相比其他词的点乘最大,至少在表面上看来似乎是没有用到词的共现信息,不像GloVe这里明确的就是拟合词对的共现频率。
不过更有意思的还是,GloVe和word2vec似乎有种更为内在的联系,再来看看他们的目标函数有什么不一样,这是Skip-gram的目标函数(这里在原来的基础上加上了对于语料的遍历N)

而这个目标函数是按照语料的顺序去遍历,如果先把语料当中的相关词进行合并,然后按照词典序进行遍历,便可以证明Skip-gram实际上和GloVe的优化目标一致,有兴趣的可以参考引用11中的证明细节,这里不再赘述。
2.3 fastText
word2vec和GloVe都不需要人工标记的监督数据,只需要语言内部存在的监督信号即可以完成训练。而与此相对应的,fastText则是利用带有监督标记的文本分类数据完成训练,本质上没有什么特殊的,模型框架就是CBOW,只不过与普通的CBOW有两点不一样,分别是输入数据和预测目标的不同,在输入数据上,CBOW输入的是一段区间中除去目标词之外的所有其他词的向量加和或平均,而fastText为了利用更多的语序信息,将bag-of-words变成了bag-of-features,也就是下图中的输入转存失败重新上传取消不再仅仅是一个词,还可以加上bigram或者是trigram的信息等等;第二个不同在于,CBOW预测目标是语境中的一个词,而fastText预测目标是当前这段输入文本的类别,正因为需要这个文本类别,因此才说fastText是一个监督模型。而相同点在于,fastText的网络结构和CBOW基本一致,同时在输出层的分类上也使用了Hierachical Softmax技巧来加速训练。

这里的转存失败重新上传取消便是语料当中第n篇文档的第i个词以及加上N-gram的特征信息。从这个损失函数便可以知道fastText同样只有两个全连接层,分别是A和B,其中A便是最终可以获取的词向量信息。

fasttext.PNG
fastText最大的特点在于快,论文中对这一点也做了详细的实验验证,在一些分类数据集上,fastText通常都可以把CNN结构的模型要耗时几小时甚至几天的时间,急剧减少到只需要消耗几秒钟,不可谓不“fast”.
不过说个八卦,为什么fastText结构和CBOW如此相似(感兴趣的读者想要继续深挖的话,还可以看看2015年ACL上的一篇论文《Deep Unordered Composition Rivals Syntactic Methods for Text Classification》,结构又是何其相似,并且比fastText的论文探讨的更为深入一些,但是fastText是2016年的文章,剩下的大家自己去想好了),这里面大概一个特别重要的原因就是fastText的作者之一便是3年前CBOW的提出者Mikolov本人,只不过昔日的Mikolov还在谷歌,如今3年时间一晃而过,早已是Facebook的人了。
2.4 爬上第一级梯子的革命意义
那为什么word2vec的出现极大的促进了NLP领域的发展?
通常以为,word2vec一类的方法会给每一个词赋予一个向量的表征,不过似乎从来没有人想过这个办法为什么行之有效?难道是皇帝的新衣?按理来说,包括NNLM在内,这些方法的主要出发点都是将一个词表示成词向量,并将其语义通过上下文来表征。其实,这背后是有理论基础的,1954年Harris提出分布假说(distributional hypothesis),这一假说认为:上下文相似的词,其语义也相似,1957年Firth对分布假说进行了进一步阐述和明确:词的语义由其上下文决定(a word is characterized by the company it keeps),30年后,深度学习的祖师爷Hinton也于1986年尝试过词的分布式表示。
而word2vec的贡献远不止是给每一个词赋予一个分布式的表征,私以为,它带来了一种全新的NLP模型建立方法,在这之前,大多数NLP任务都要在如何挖掘更多文本语义特征上花费大量时间,甚至这一部分工作占去了整个任务工作量的绝大部分,而以word2vec为代表的distributed representation方法大量涌现后(尤其是因为大规模语料上的预训练词向量成为现实,并且被证明确实行之有效之后),算法人员发现利用word2vec在预训练上学习到的词向量,初始化他们自己模型的第一层,会带来极大效果的提升,以至于这五年以来,几乎一个业内的默认做法便是要用了无论word2vec还是GloVe预训练的词向量,作为模型的第一层,如果不这么做,大约只有两个原因:
-
你很土豪,有钱标注大量监督数据;
-
你在蛮干。
而这一个思想,绝不是如它表象所显示的一样,似乎和过去做文本特征没什么太大区别,是的,表象确实是这样,无非是把一个词用了一堆数字来表征而已,这和离散化的特征有什么本质区别吗?有,因为它开启了一种全新的NLP模型训练方式——迁移学习。基本思想便是利用一切可以利用的现成知识,达到快速学习的目的,这和人类的进化历程何其相似。
虽然咿咿呀呀囫囵吞枣似的刚开始能够说得三两个词,然而这是“NLP的一小步,人类AI的一大步”。正如人类语言产生之初,一旦某个原始人类的喉部发出的某个音节,经无比智慧和刨根问底考证的史学家研究证实了它具有某个明确的指代意义(无论它指代什么,即便是人类的排泄物),这便无比庄严的宣示着一个全新物种的诞生,我想迁移学习在NLP中的这一小步,大概与此同担当。















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}