







数据预处理
主要分为 归一化、中心化、标准化
注意区别 正则化
- 归一化: 主要是 Min-Max scaling
- 把数据变成 [0,1] 之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
- 把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
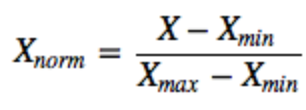
-
标准化:
在机器学习中,我们可能要处理不同种类的资料,例如,音讯和图片上的像素值,这些资料可能是高维度的,资料标准化后会使每个特征中的数值平均变为0(将每个特征的值都减掉原始资料中该特征的平均)、标准差变为1,这个方法被广泛的使用在许多机器学习算法中(例如:支持向量机、逻辑回归和类神经网络)。 -
中心化:
平均值为0,对标准差无要求,这个一般没啥用,很少见到单独使用这个; -
归一化和标准化的区别:
- 归一化是将样本的特征值转换到同一量纲下,把数据映射到[0,1]区间内,仅由变量的极值决定(min-max)。
- 标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布,和整体样本分布相关,每个样本点都能对标准化产生影响。
- 它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
两种都可以 直接用来做 数据预处理,但是min-max归一化对异常值比较敏感,一般使用 标准化 比较多;
-
标准化和中心化的区别:标准化是原始分数减去平均数然后除以标准差,中心化是原始分数减去平均数。 所以一般流程为先中心化再标准化。
-
无量纲:我的理解就是通过某种方法能去掉实际过程中的单位,从而简化计算。
2 为什么要归一化/标准化?
网络模型学习的是数据分布,如果不对数据进行归一化,对于不同的特征属性其取值空间可能差异很大,
- 无量纲化 避免数值引起问题(梯度爆炸、消失),当特征属性中存在多项不同量纲、数量级的特性时,各项属性之间的水平相差较大,不能正确学习各个属性的比例权重;在CNN中做标准化可以避免梯度爆炸问题;
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
- 加速算法收敛,提高算法收敛性能

什么时候用归一化?什么时候用标准化?
- 如果对输出结果范围有要求,用归一化。
- 如果数据较为稳定,不存在极端的最大最小值,用归一化。
- 如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
Btach Normalization
首先介绍Btach Normalization,BN算法的强大之处在于:
- 可以选择较大的初始学习率,提高训练速度。以前需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少合适,现在可以采用初始很大的学习率,然后学习率衰减速度也很大,因为这个算法收敛很快。
- 不用理会过拟合中dropout、l2正则项参数的选择问题,采用BN后,可以移除这两项的参数,或者可以选择更小的l2正则约束参数,因为BN具有提高网络泛化能力的特性
- 不需使用局部响应归一化层(Alexnet用到的方法),因为BN本身就是一个归一化网络层
- 可以把训练数据彻底打乱(防止每批训练的时候,某一个样本经常被挑选到,文献说可以提高1%的精度)
神经网络学习的本质就是学习数据分布,一旦测试集与训练集的数据分布不同,那么网络的泛化能力会大大下降;另外一方面,Batch也是一样的道理,如果每批次的数据分布不统一,那么网络每次更新都要适应不同的数据分布,其收敛速度会很慢;
我们知道网络一旦train起来,那么参数就要发生更新,除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”。Paper所提出的算法,就是要解决在训练过程中,中间层数据分布发生改变的情况,于是就有了Batch Normalization,这个牛逼算法的诞生。
BN概述
就像激活函数层、卷积层、全连接层、池化层一样,BN也是网络的一层。该算法本质是: 在网络的每一层输入的时候,插入了一个归一化层,也就是先做一个归一化处理,然后再进 入网络的下一层。但是文献的归一化层不像想象的那么简单,它是一个可学习、有参数的网络 层。既然说到数据预处理,就先来复习一下最强的预处理方法:白化。
BN算法是如何加快训练和收敛速度的呢?
BN算法在实际使用的时候会把特征给强制性的归到均值为0,方差为1的数学模型下。深度 网络在训练的过程中,如果每层的数据分布都不一样的话,将会导致网络非常难收敛和训练, 而如果能把每层的数据转换到均值为0,方差为1的状态下,
一方面,数据的分布是相同的,训练会比较容易收敛,另一方面,均值为0,方差为1的状态下,在梯度计算时会产生比较大 的梯度值,可以加快参数的训练,更直观的来说,是把数据从饱和区直接拉到非饱和区。更进一步,这也可以很好的控制梯度爆炸和梯度消失现象,因为这两种现象都和梯度有关。 BN最大的优点为允许网络使用较大的学习率进行训练,提升网络的收敛速度;
具体实现

Batch Normalization:
1.BN的计算就是把每个通道的NHW单独拿出来归一化处理
2.针对每个channel我们都有一组γ,β,所以可学习的参数为2*C
3.当batch size越小,BN的表现效果也越不好,因为根据几个样本计算所得到的均值、方差不能代表全局

Layer Normalizaiton:
1.LN的计算就是把每个CHW单独拿出来归一化处理,不受batchsize 的影响
2.常用在RNN网络,但如果输入的特征区别很大,那么就不建议使用它做归一化处理

Instance Normalization
1.IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响
2.常用在风格化迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理

Group Normalizatio
1.GN的计算就是把先把通道C分成G组,然后把每个gHW单独拿出来归一化处理,最后把G组归一化之后的数据合并成CHW
2.GN介于LN和IN之间,当然可以说LN和IN就是GN的特列,比如G的大小为1或者为C

Switchable Normalization
1.将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法
2.集万千宠爱于一身,但训练复杂
# mini_batch 批次内计算, 统计 (BHW) 均值, 保留C通道
def _BN():
data = np.random.rand(100, 30, 64, 64) * 1000
mean = np.mean(data,axis=(0,2,3),keepdims=True)
val = np.std(data,axis=(0,2,3),keepdims=True)
numpy_bn = (data - mean) / (val + 1e-8)
bn_ = nn.BatchNorm2d(num_features=30, eps=1e-8, affine=False, track_running_stats=False)
x2 = torch.from_numpy(data)
offical_bn = bn_(x2)
print('diff:{}'.format((offical_bn.numpy() - numpy_bn).sum()))
# 单样本内计算, 根据 (CHW) 计算均值和方差
def _LN():
data = np.random.rand(100, 30, 64, 64) * 1000
mean = np.mean(data,axis=(1,2,3),keepdims=True)
val = np.std(data,axis=(1,2,3),keepdims=True)
numpy_ln = (data - mean) / (val)
ln_ = nn.LayerNorm(normalized_shape=[30,64,64], eps=0, elementwise_affine=False)
x2 = torch.from_numpy(data)
offical_ln = ln_(x2)
print('diff:{}'.format((offical_ln.numpy() - numpy_ln).sum()))
# 单个样本内部进行,不依赖 batch, 根据 (HW)维度求 均值和方差
# feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格,
# 因此可以先把图像在 channel 层面归一化,
def _IN():
data = np.random.rand(100, 30, 64, 64) * 1000
mean = np.mean(data,axis=(2,3),keepdims=True)
val = np.std(data,axis=(2,3),keepdims=True)
numpy_in = (data - mean) / (val + 1e-05)
in_ = nn.InstanceNorm2d(num_features=30,eps=1e-05,affine=False)
x2 = torch.from_numpy(data)
offical_in = in_(x2)
print('diff:{}'.format((offical_in.numpy() - numpy_in).sum()))
# 小batch很难 根据几个样本的数据量,来近似总体的均值和标准差
# 基于 LN 和 IN 的折中, GN 将 channel 均分成 G 组, 对每一组(C/G,H,W) 统计其均值和方差
def _GN():
data = np.random.rand(100, 30, 64, 64) * 1000
data_ = data.reshape(100, 10, -1)
mean = np.mean(data_,axis=-1,keepdims=True)
val = np.std(data_,axis=-1,keepdims=True)
numpy_gn = (data_ - mean) / val
numpy_gn = numpy_gn.reshape(100,30,64,64)
numpy_gn = numpy_gn.reshape(100, 30, 64, 64)
gn_ = nn.GroupNorm(num_groups=10, num_channels=30, eps=0, affine=False)
offical_gn = gn_(torch.from_numpy(data))
print('diff:{}'.format((offical_gn.numpy() - numpy_gn).sum()))
实现参考自 BN、IN、GN、LN实现















 7315
7315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









