







optim 的基本使用
for do:
1. 计算loss
2. 清空梯度
3. 反传梯度
4. 更新参数
optim的完整流程
cifiron = nn.MSELoss()
optimiter = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9)
for i in range(iters):
out = net(inputs)
loss = cifiron(out,label)
optimiter.zero_grad() # 清空之前保留的梯度信息
loss.backward() # 将mini_batch 的loss 信息反传回去
optimiter.step() # 根据 optim参数 和 梯度 更新参数 w.data -= w.grad*lr
网络参数 默认使用统一的 优化器参数
-
如下设置 网络全局参数 使用统一的优化器参数
optimiter = torch.optim.Adam(net.parameters(),lr=0.01,momentum=0.9) -
如下设置将optimizer的可更新参数分为不同的三组,每组使用不同的策略
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': first_params, 'lr': 0.01*args.learning_rate},
{'params': second_params, 'weight_decay': args.weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
)
我们追溯一下构造Optim的过程
为了更好的看整个过程,去掉了很多 条件判断 语句,如 >0 <0
# 首先是 子类Adam 的构造函数
class Adam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,
weight_decay=0, amsgrad=False):
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, amsgrad=amsgrad)
'''
构造了 参数params,可以有两种传入格式,分别对应
1. 全局参数 net.parameters()
2. 不同参数组 [{'params': other_params},
{'params': first_params, 'lr': 0.1*lr}]
和 <全局> 的默认参数字典defaults
'''
# 然后调用 父类Optimizer 的构造函数
super(Adam, self).__init__(params, defaults)
# 看一下 Optim类的构造函数 只有两个输入 params 和 defaults
class Optimizer(object):
def __init__(self, params, defaults):
torch._C._log_api_usage_once("python.optimizer")
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = [] # 自身构造的参数组,每个组使用一套参数
param_groups = list(params)
if len(param_groups) == 0:
raise ValueError("optimizer got an empty parameter list")
# 如果传入的net.parameters(),将其转换为 字典
if not isinstance(param_groups[0], dict):
param_groups = [{'params': param_groups}]
for param_group in param_groups:
#add_param_group 这个函数,主要是处理一下每个参数组其它属性参数(lr,eps)
self.add_param_group(param_group)
def add_param_group(self, param_group):
# 如果当前 参数组中 不存在默认参数的设置,则使用全局参数属性进行覆盖
'''
[{'params': other_params},
{'params': first_params, 'lr': 0.1*lr}]
如第一个参数组 只提供了参数列表,没有其它的参数属性,则使用全局属性覆盖,第二个参数组 则设置了自身的lr为全局 (0.1*lr)
'''
for name, default in self.defaults.items():
if default is required and name not in param_group:
raise ValueError("parameter group didn't specify a value of required optimization parameter " +
name)
else:
param_group.setdefault(name, default)
# 判断 是否有一个参数 出现在不同的参数组中,否则会报错
param_set = set()
for group in self.param_groups:
param_set.update(set(group['params']))
if not param_set.isdisjoint(set(param_group['params'])):
raise ValueError("some parameters appear in more than one parameter group")
# 然后 更新自身的参数组中
self.param_groups.append(param_group)
网络更新的过程(Step)
具体实现
- 我们拿SGD举例,首先看一下,optim.step 更新函数的具体操作
- 可见,
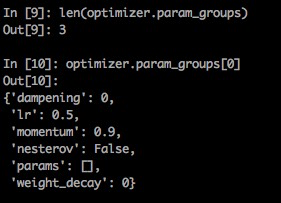
for group in self.param_groups,optim中存在一个param_groups的东西,其实它就是我们传进去的param_list,比如我们上面传进去一个长度为3的param_list,那么len(optimizer.param_groups)==3, 而每一个group又是一个dict, 其中包含了 每组参数所需的必要参数optimizer.param_groups:长度2的list,optimizer.param_groups[0]:长度6的字典 - 然后取回每组 所需更新的参数
for p in group['params'],根据设置 计算其 正则化 及 动量累积,然后更新参数w.data -= w.grad*lr
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
# 本组参数更新所必需的 参数设置
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']: # 本组所有需要更新的参数 params
if p.grad is None: # 如果没有梯度 则直接下一步
continue
d_p = p.grad.data
# 正则化 及 动量累积 操作
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
# 当前组 学习参数 更新 w.data -= w.grad*lr
p.data.add_(-group['lr'], d_p)
return loss
如何获取指定参数
- 可以使用
model.named_parameters()取回所有参数,然后设定自己的筛选规则,将参数分组 - 取回分组参数的id
map(id, weight_params_list) - 取回剩余分特殊处置参数的id
other_params = list(filter(lambda p: id(p) not in params_id, all_params))
all_params = model.parameters()
weight_params = []
quant_params = []
# 根据自己的筛选规则 将所有网络参数进行分组
for pname, p in model.named_parameters():
if any([pname.endswith(k) for k in ['cw', 'dw', 'cx', 'dx', 'lamb']]):
quant_params += [p]
elif ('conv' or 'fc' in pname and 'weight' in pname):
weight_params += [p]
# 取回分组参数的id
params_id = list(map(id, weight_params)) + list(map(id, quant_params))
# 取回剩余分特殊处置参数的id
other_params = list(filter(lambda p: id(p) not in params_id, all_params))
# 构建不同学习参数的优化器
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': quant_params, 'lr': 0.1*args.learning_rate},
{'params': weight_params, 'weight_decay': args.weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
)
获取指定层的参数id
# # 以层为单位,为不同层指定不同的学习率
# ## 提取指定层对象
special_layers = t.nn.ModuleList([net.classifiter[0], net.classifiter[3]])
# ## 获取指定层参数id
special_layers_params = list(map(id, special_layers.parameters()))
print(special_layers_params)
# ## 获取非指定层的参数id
base_params = filter(lambda p: id(p) not in special_layers_params, net.parameters())
optimizer = t.optim.SGD([{'params': base_params},
{'params': special_layers.parameters(), 'lr': 0.01}], lr=0.001)
这里使用python手动实现了整个优化过程,可以更清晰的看到整个网络学习的过程
python(numpy) 实现神经网络训练 (卷积 全连接 池化)















 6308
6308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









