










 利用神经网络识别手绘化学结构,通过合成数据集增强训练效果,实现在真实世界数据上的高效识别。
利用神经网络识别手绘化学结构,通过合成数据集增强训练效果,实现在真实世界数据上的高效识别。

GitHub - mtzgroup/ChemPixCH: Recognising hand-drawn molecules with neural networks
一、问题提出
徒手绘制化学骨架结构是化学界学生和研究人员的常规任务,同时,用手绘制化学结构远比用鼠标绘制要简单得多。
手绘化学结构识别在许多方面与手写识别的任务相似。书写风格的巨大变化、低图像质量、缺乏标签和草书使手写文本识别成为一项具有挑战性的任务。
二、Methods
1、architecture
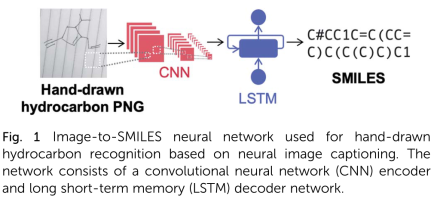
评估:完全正确预测的分子比例,即预测的SMILES逐字匹配目标SMILES。通过替换从测试集中采样的200个数据点的1000个集合的准确性,并计算包含基于重新采样集的95%可能性的统计平均值的范围,计算误差条。
2、Datasets
从GDB-13和GDB11数据库中提取包含500 000个SMILES字符串(环小于8个碳原子)。只包括数字“1”,这意味着不考虑具有多个连环的分子。使用RDKit进行SMILES规范化(致10%数据删除),以提供一致的目标输出。图片由rdkit转化(SVG→png)。
训练/验证集(90%)、测试集(10%)。进一步分割训练/验证集为训练集(90%)和验证集(10%),图片都被Resize到256*256px(OpenCV)
手绘碳氢化合物的真实照片共有613张。测试集200张,剩下413张图像要么完全用作验证集,要么根据实验的不同分为验证(200张图像)和训练(213张图像)数据集。
三、实验
1、Results and discussion
先使用RDKit生成的干净图像和smiles标签训练。神经网络的识别精度随数据集的大小而增加。一个包含5万张RDKit图像的数据集可以达到超过90%(测试集)精度,而包含50万张可以达到98%精度。
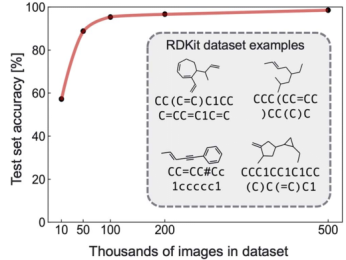
尽管RDKit合成5万张图像的数据集有90%精度,但实际上可能需要更多的手绘分子image来达到同样的精度。绘图风格、背景和图像质量的变化带来问题,存在(i)化学结构相关的噪声,如不同的线宽、长度、角度和失真,(ii)背景,如不同的纹理、照明、颜色和周围的文本,以及(iii)照片,如模糊、像素计数和图像格式。
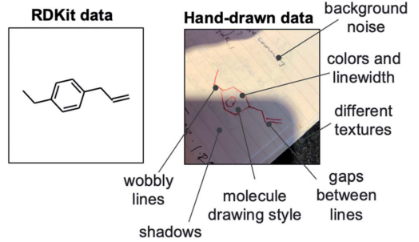
现实世界手绘分子的大型标记数据集并不存在,也不容易生成。因此,与RDKit图像的情况不同,仅仅通过几十万个手绘结构的训练是不可能达到较高的识别精度的,生成合成数据可能比花费过多的时间和资源收集大量真实世界的数据更有效。开发了一个数据收集web应用程序,以获取手工绘制的化学结构的小数据集。为了捕捉在现实世界数据中普遍存在的绘画风格、照片质量和背景类型中的大量噪声。100多名独立用户生成了5800多张手绘化学结构照片,其中613张是碳氢化合物。
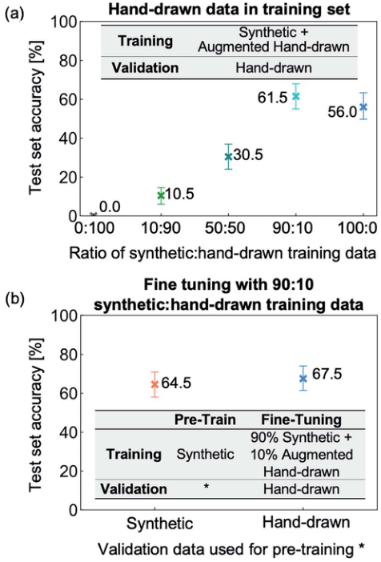
因此采用合成大量数据集(数据增强:添加背景,扭曲线条和模糊图像等) + 少量真实数据集:
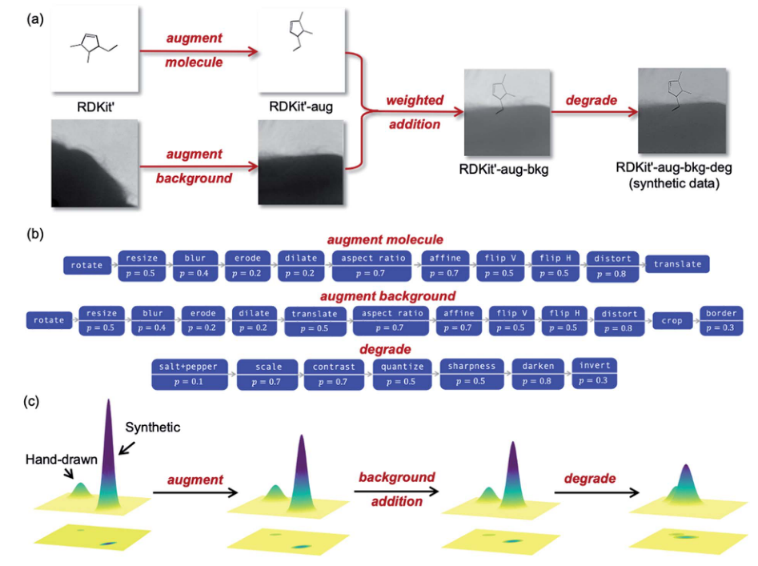
(c):随着数据经过 augmentation, background addition和degrade等步骤,合成分布逐渐接近手绘数据分布
通过使用手绘验证集进行预训练,达到67.5%的准确率,而从零开始训练的准确率为61.5%(说明手绘验证集还是带来了增益)
多个模型集成的准确率:
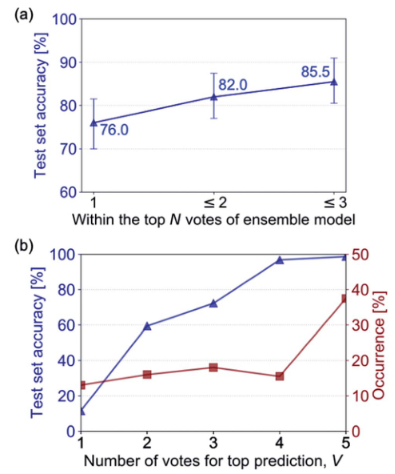
(a)集合模型(多个训练模型)的最高N个,与参考SMILES标签进行比较。(b)当预测有一定的一致投票数时,V(蓝色)和top预测有一定的一致投票数出现的百分比(红色)。随着排名靠前的预测V数的增加,识别精度增加
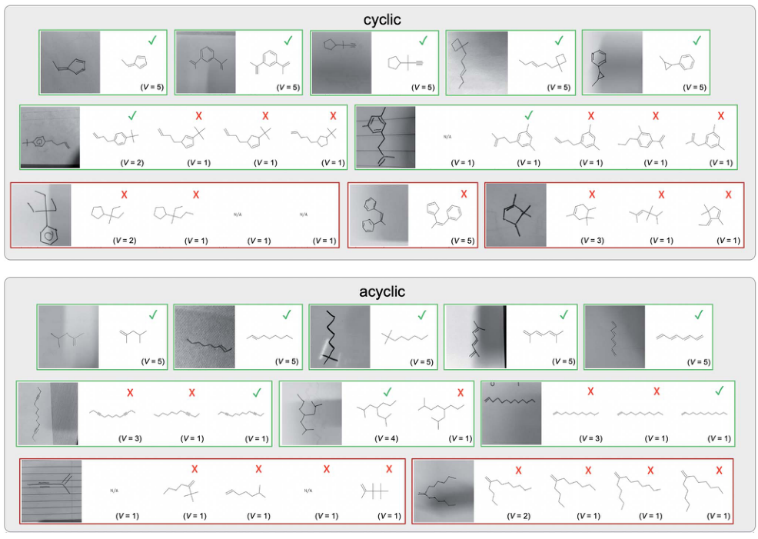
预测的不确定性很高,它会显示前三个预测;然后用户可以从三个分子中选择正确的分子。这些数据可以被持续收集并反馈到神经网络中,随着收集到更多的数据,迭代地重新训练并提高其性能。集成模型识别正确的分子,在超过70%的情况下有89%的可信度,在超过50%的情况下有接近100%的可信度
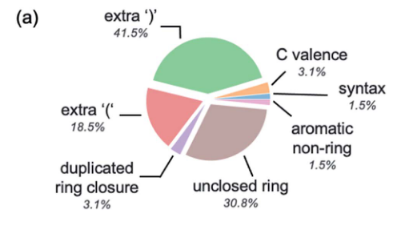
出现误差的原因(主要是规则限制):
附加(rdkit生成类似手绘的分子image代码):
https://github.com/mtzgroup/ChemPixCH/tree/main/data/hand-drawn/hand-drawn-training/training-sets
很有意思。采用生成的方式模拟手写。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









