










原文标题:Multi-View Graph Neural Networks for Molecular Property Prediction
论文地址:https://ml4molecules.github.io/papers2020/ML4Molecules_2020_paper_5.pdf
一、问题提出
如何在单一模型中恰当地集成节点信息和边信息是首要的挑战问题。
可解释性对于药物的发现是非常重要的。理解底层模型如何工作还将帮助人们找出确定某些属性的关键组件。
二、模型
1、前置知识
分子c用graph 表示,Gc = (V,E),V为p个节点集合(即分子中原子个数),E为q条边的集合(即分子中键的条数),满足(vi,vj)∈E,Nv表示图中节点V的邻域集。将节点v的特征表示为xv∈Rdn,将边(v, k)的特征表示为evk∈Rde,其中dn和de分别表示节点和边的特征维数。节点特征和边特征是初始化学相关特征,如原子质量和键类型。将属性y表示为预测任务的目标,对于分类任务,它是二进制值,对于回归任务,它是实值,这取决于属性类型。因此属性预测任务为:
任务定义为:给定一个分子c和它的graph Gc,分子性质预测的目标是根据Gc映射出的图形表示ξc来预测分子的性质yc
补充材料:
节点/边特征提取包括两个部分:1)通过迭代聚合相邻节点/边缘特征构建节点/边缘信息;2)分子级特征,是RDKit为捕获全局分子信息而生成的附加的分子级特征。
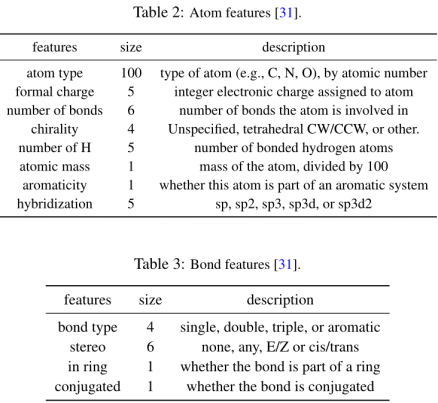
RDKit特性与节点/边embedding连接在一起,通过最终的fc来进行预测。
2、Multi-View Graph Neural Network (MVGNN)
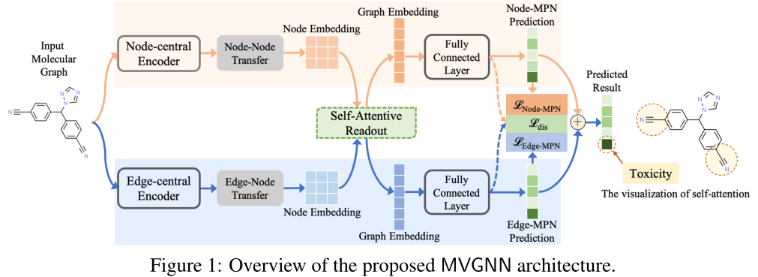
包含节点中心编码器(Node-central Encoder)和边中心编码器(Edge-central Encoder)两个并行阶段,分别负责根据图拓扑和节点/边特征,生成节点/边embedding矩阵。使用message passing neural network【Neural message passing for quantum chemistry(ICML2017)】作为backbone,分别设计两个Encoder。接下来,MVGNN采用self-attentive aggregation的方法学习每个embedding的不同权重,生成Graph Embedding。此外,在节点中心编码器(Node-central Encoder)和边中心编码器(Edge-central Encoder)之间共享self-attentive aggregation,以加强节点信息和边信息的学习。self-attentive aggregation,MVGNN将两个graph embedding+两个独立的FC层,根据具体的预测任务拟合损失函数。
为了稳定这种双体系结构的训练过程,使用了一个Disagreement loss来强制两个独立的FC层有彼此相似的输出。
1)Node-central and Edge-central Encoders
消息传递神经网络(MPNN)可以被看作是graph中信息扩散的模拟。特别地,它聚合并传递相应邻居节点的特征信息来生成新的embedding。以MPNN为backbone。
节点中心编码器(Node-central Encoder):

其中Node-MPN初始输入为:
![]()
在l + 1步时,Node-MPN通过聚合相邻节点u∈Nn和自身先前的状态来更新节点v的状态,并将相应的边特征evu作为附加特征生成节点v的新状态。
经历L步扩散。利用Node-Node Transfer,具有不同的权重矩阵Wnout∈Rdout×(de+dhid),得到最终的节点embedding:
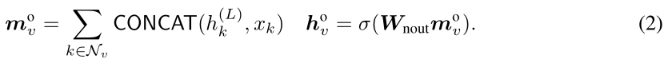
这个Transfer可以引入更多的参数和非线性来增强Node-MPN的描述能力。Hn = [ho1,···,hop]∈Rdout×p为Node-MPN的输出embedding,其中dout为输出embedding的维数。
边中心编码器(Edge-central Encoder):
节点可以看作是connections,边可以看作是entities。因此,可以在L(G)上模拟Node-MPN执行通过边的消息。即给定一条边(v, w),边中心编码器中基于边的MPN (Edge-based MPNN (Edge-MPN) )的表达式为:
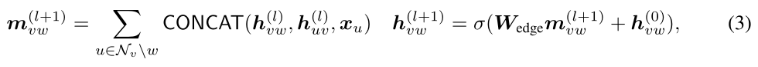
其中Edge-MPN初始输入为:
![]()
消息传递和状态更新阶段与Node-MPN类似。Edge-MPN也包含L个步骤,并在节点上多传递one more round 消息,将edge-wise embedding转化为node-wise(通过Edge-Node Transfer):
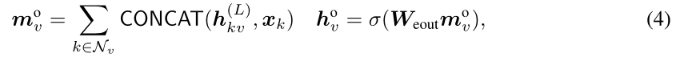
Edge-MPN的最终输出表示为He = [ho1,···,hop]∈R dout×p。
3、The Self-attentive Readout for Graph-level Embedding
为了得到固定长度的graph表示,需readout transformation,以消除node size variance and permutation variance。引入的self-attention来学习节点的重要性,并将节点embedding编码为一个大小不变的graph embedding向量,即给定节点中心编码器Hn∈Rdout×p的输出,定义node上的Self-attentive Readout:
![]()
W1和W2是两个权重矩阵,在两个子模型之间共享,以实现多视图训练过程中特征信息的binding and communicating。根据得到的自注意S,生成涉及图embedding ξ值的大小不变量和节点重要性。(可通过全连接层+tanh激活函数+全连接层 + 点积 + Flatten层)
4、The Loss of MVGNN
将节点中心和边中心编码器ξn和ξe得到的graph embedding输入到两个全连接中,分别获得两种编码器的预测。Loss:
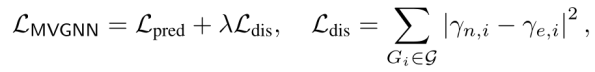
Lpred为两条路径embedding的预测监督损失,Ldis为偏差损失,λ是一个超参数。
三、Experiments & Results
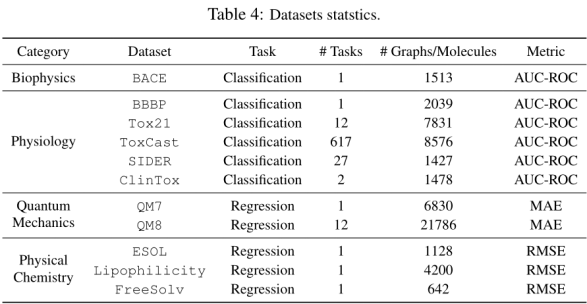
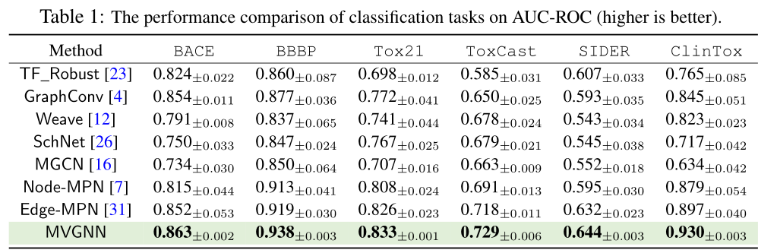
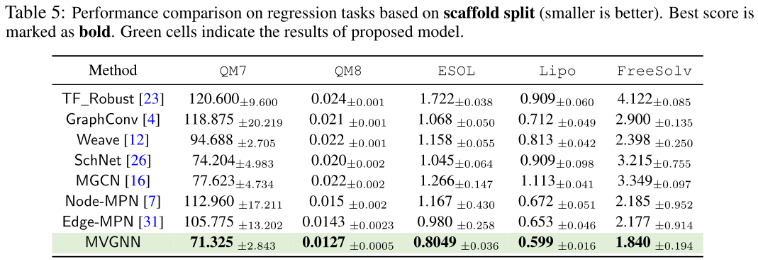
11个基准数据集的7个baseline进行比较。6/11为分类任务。其余为回归任务,所有分类任务由AUC-ROC评估。分类任务应用AUC-ROC评估,回归任务应用MAE和RMSE评估。按骨架划分数据集,8:1:1
1、Performance Evaluation
分类:
回归:
2、Visualization of the Interpretability Results
将来自ClinTox数据集的特定分子与每个原子相关的已知注意可视化,并以毒性为标签
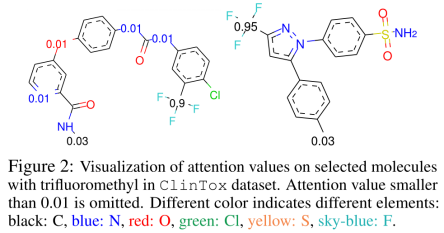
如上:1)大多数负责构建分子拓扑结构的碳原子(C)没有得到重视。2)MVGNN还促进官能团的学习,对分子毒性有印象,例如,毒性官能团三氟甲基因毒性而闻名,这在上图中显示了极高的关注度。
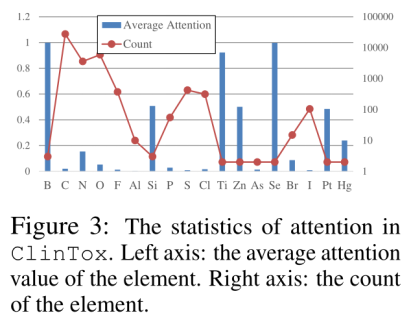
上图提供整个ClinTox数据集的attention值的综合统计数据。展示每个单一元素的平均注意值,以及它们的总出现次数。值得注意的是:1)频率高的原子不受高度重视,如C。2)频率低但重视值高的原子一般是重元素。例如,汞因其毒性而广为人知。对于原子应考虑不同的权重。















 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









