







在深度学习任务中,我们常常会为模型定义一个损失函数,损失函数表征的是预测值和实际值之间的差距,再通过一定的优化算法减小这个差距
然后绝大多数情况下,我们的损失函数十分复杂,不像我们解数学题能得到一个确定,唯一的解析解。而是通过数学的方法去逼近一个解,也称数值解
局部最小值和全局最小值
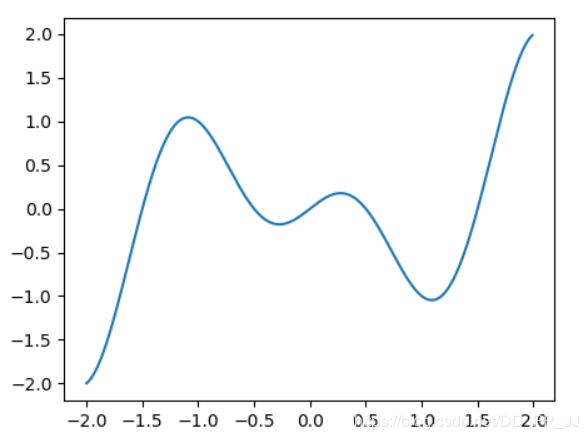
假设我们的损失函数是
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(-2, 2, 0.01)
print(x)
f = x*np.cos(np.pi*x)
plt.plot(x, f)
plt.show()
我只画出了区间(-2, 2)的函数图像,通过观察图像,我们发现该函数有两个波谷,分别是局部最小值和全局最小值。
到达局部最小值的时候,由损失函数求得的梯度接近于0,我们很难再跳出这个局部最小值,进而优化到全局最小值,即x=1处,这也是损失函数其中的挑战
鞍点
假设我们的损失函数为
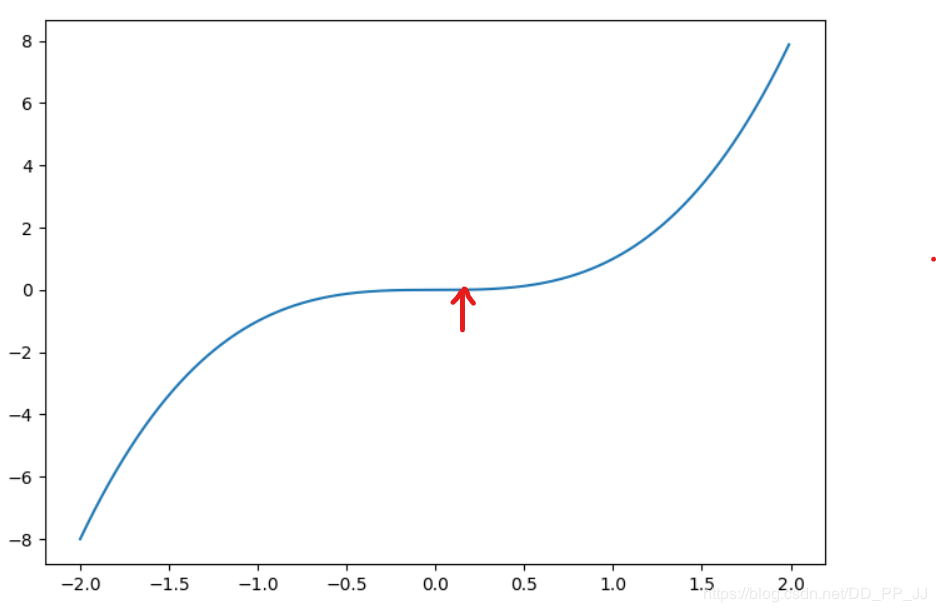
文章所标的点,即是鞍点(saddle point),形状像马鞍处。
它的特点也是两边的梯度趋近于0,但并不是真正的最小值点
在深度学习优化过程中,这两种情况很常见,我们需要尽可能地通过数学方式去逼近最优
梯度下降为什么有效
这里需要用到高数里面的泰勒展开公式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









