







爬虫概述
1. 爬虫简介
1.1 什么是爬虫
通过编写程序,模拟浏览器上网,抓取网络上整个页面或特定数据
1.2 爬虫的合法性
- 法律上不被禁止
- 具有违法风险
- 干扰了被访问网站的正常运行
- 抓去了受法律保护的数据或信息
综上,我们要时常优化自己的爬虫程序,避免干扰到正常网站的运行,并且在爬取到数据时,发现涉及用户隐私和商业机密等敏感内容时,一定要终止爬取和传播。
1.3 反爬
-
反爬机制
门户网站,可以制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取
UA检测💎💎💎:门户网站会检测对应载体的身份标识,若标识为某一浏览器,则正常,若不是基于浏览器,则表示不正常,则服务器可能会拒绝请求。
-
反反爬策略
爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站的反爬机制,从而获取门户网站相关数据。
UA伪装💎💎💎:使我们的爬虫程序伪装程一款浏览器
-
robots.txt 协议
君子协议,规定网页中哪些数据可以爬取,哪些数据不可以爬取。(防君子,不防小人)
1.4 爬虫的分类
-
通用式爬虫
抓取系统重要组成部分,抓取一整张页面
-
聚焦爬虫
建立在通用爬虫的基础上,抓取页面特定数据
-
增量式爬虫
监测网站中数据更新情况,仅抓取最新数据
2. web请求全过程剖析
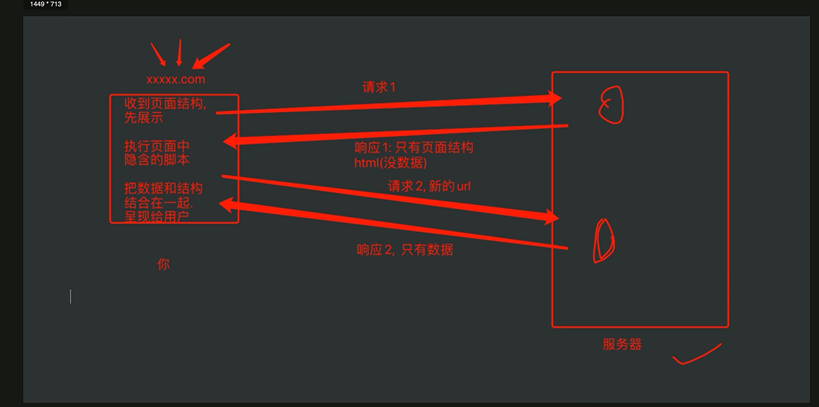
3. HTTP协议
服务器和客户端之间机型数据交互的一种遵循形式。
HTTP协议把一条消息分为三部分:
- 请求
- 请求行 -> 请求方式(get/post)请求 url 地址,协议
- 请求头 -> 放一些服务器要使用的附加信息
- user-Agent:请求载体身份标识
- connection: 请求完毕后是否断开连接
- 请求体 -> 一般放一些请求参数
- 响应
- 状态行 -> 协议,状态码
- 响应头 -> 放一些用户端要使用的一些附加信息
- content-Type:响应数据类型
- 响应体 -> 服务器返回的真正客户端要用的内容(HTML,json)等
4. HTTPS 协议
加密方式:
- 对称密钥加密
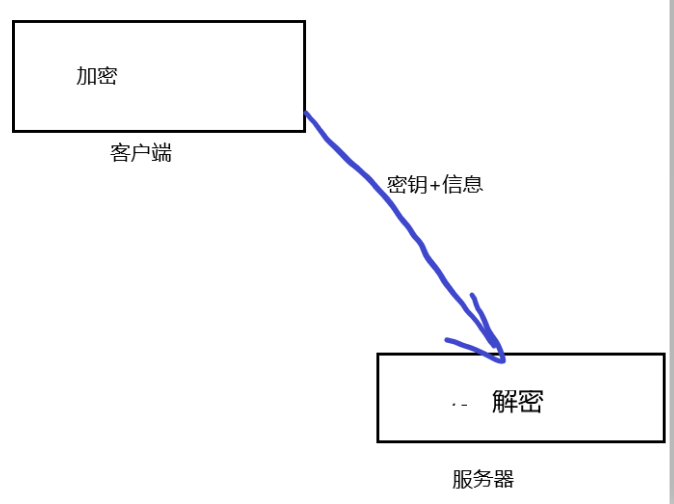
- 非对称密钥加密:服务器发送公钥给客户端,然后客户端加密,最后服务器解密
- 证书密钥加密💎💎💎 :通过证书认证机构对公钥签名,防伪
)]
- 非对称密钥加密:服务器发送公钥给客户端,然后客户端加密,最后服务器解密
- 证书密钥加密💎💎💎 :通过证书认证机构对公钥签名,防伪















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









