






大家好,我是书生·浦语大模型实战营第二期的助教yanbo,接下来跟大家分享我的第一次作业笔记:
一、大模型成为发展通用人工智能的重要途径
专用模型(围棋、语音识别、人脸识别)-->通用大模型(一个模型对应多种任务、多种模态)
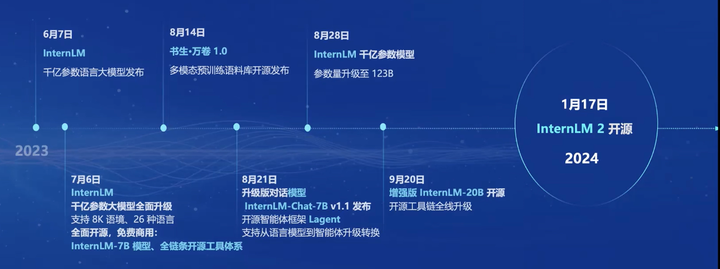
书生·浦语大模型开源历程
InternLM2(7B、20B):高质量和具有很强可塑性的模型基座,是模型进行深度领域适配的高质量起点
新版本都做了什么?
回归语言建模的本质--给定context去预测token,具体在数据清洗、高质量语料和新数据补全提升模型性能三个方面有所体现,同时整体的下游任务性能在不断增强。
新一代数据清洗过滤技术:
1.多维度数据价值评估
2.高质量语料驱动的数据富集
3.有针对的数据补齐
模型能力亮点:长上下文理解、对话与创作、数学能力等,例如通过模型进行行程规划和情感对话。
二、从模型到应用

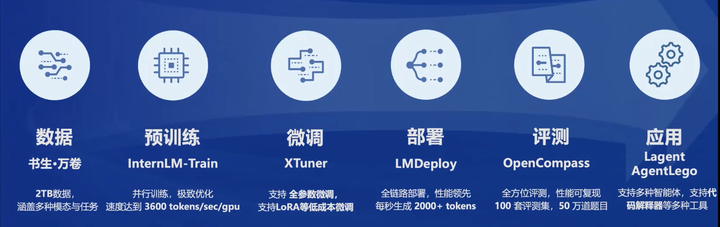
基本实现了全覆盖
paper:https://arxiv.org/pdf/2403.17297.pdf
第一次直播链接:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
(后续会更paper解读)















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









