









L1正则化与L2正则化
正则化之所以能够降低过拟合的原因在于,正则化是结构风险最小化(模型结构最简单,经验风险最小化就是训练误差小)的一种策略实现。 给loss function加上正则化项,能使得新得到的优化目标函数h = f+normal,需要在f和normal中做一个权衡(trade-off),如果还像原来只优化f的情况下,那可能得到一组解比较复杂,使得正则项normal比较大,那么h就不是最优的,因此可以看出加正则项能让解更加简单,符合奥卡姆剃刀理论(如无必要,勿增实体),同时也比较符合在偏差和方差(方差表示模型的复杂度)分析中,通过降低模型复杂度,得到更小的泛化误差,降低过拟合程度。
L1正则化和L2正则化: L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多)。L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。
那么接下来我们思考一个问题。假设我们知道L1正则的稀疏性要比L2正则的稀疏性好,那么我们为什么要对这种稀疏性趋之若鹜呢?
我们对稀疏规则趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,大部分特征 x_i 都是和最终的输出 y_i 没有关系或者不提供任何信息的。在最小化目标函数的时候考虑 x_i 这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的特征权重反而会被考虑,从而干扰了对正确 y_i 的预测。L1 正则化的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些无用的特征,也就是把这些特征对应的权重置为 0。
那么L2正则存在的意义是什么呢?
L2正则存在的意义就是加速权重衰减的速度,也就是加大了对权重的惩罚。
下面来讲一下两种正则化的理论知识和直观理解。


下面讲一下l1 和l2 正则化的来源的推导。
基于最大后验概率估计的理解。
我们的目的就是通过对w合理的取值然后最小化后验概率函数。


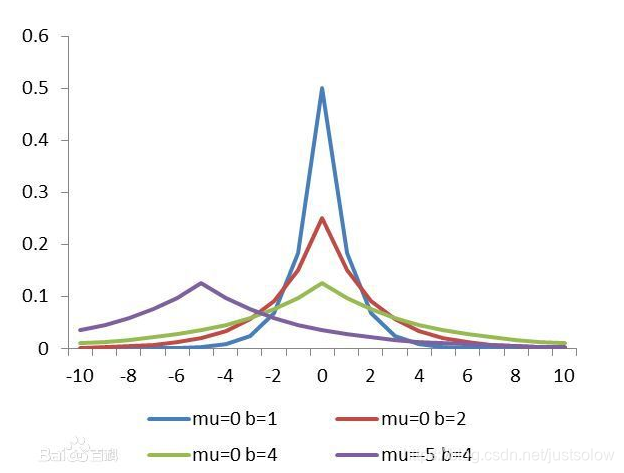
拉普拉斯分布
高斯分布
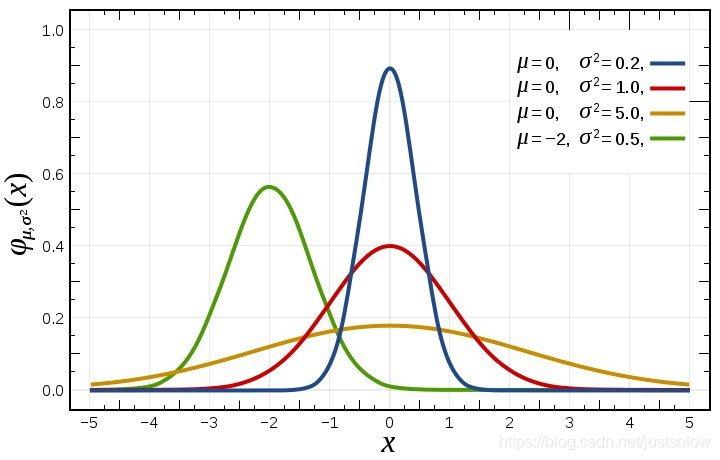
所以从上面的两张图可以看得出来,拉普拉斯分布(l1)会直接取到0,而高斯分布(l2)则会更加接近零。














 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









