







这是一道 困难 题
来自:
https://leetcode.cn/problems/substring-with-concatenation-of-all-words/
题目
给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
例如,如果 words = [“ab”,“cd”,“ef”], 那么 "abcdef", "abefcd","cdabef", "cdefab","efabcd", 和 "efcdab" 都是串联子串。 "acdbef" 不是串联子串,因为他不是任何 words 排列的连接。
返回所有串联字串在 s 中的开始索引。你可以以 任意顺序 返回答案。
示例 1:
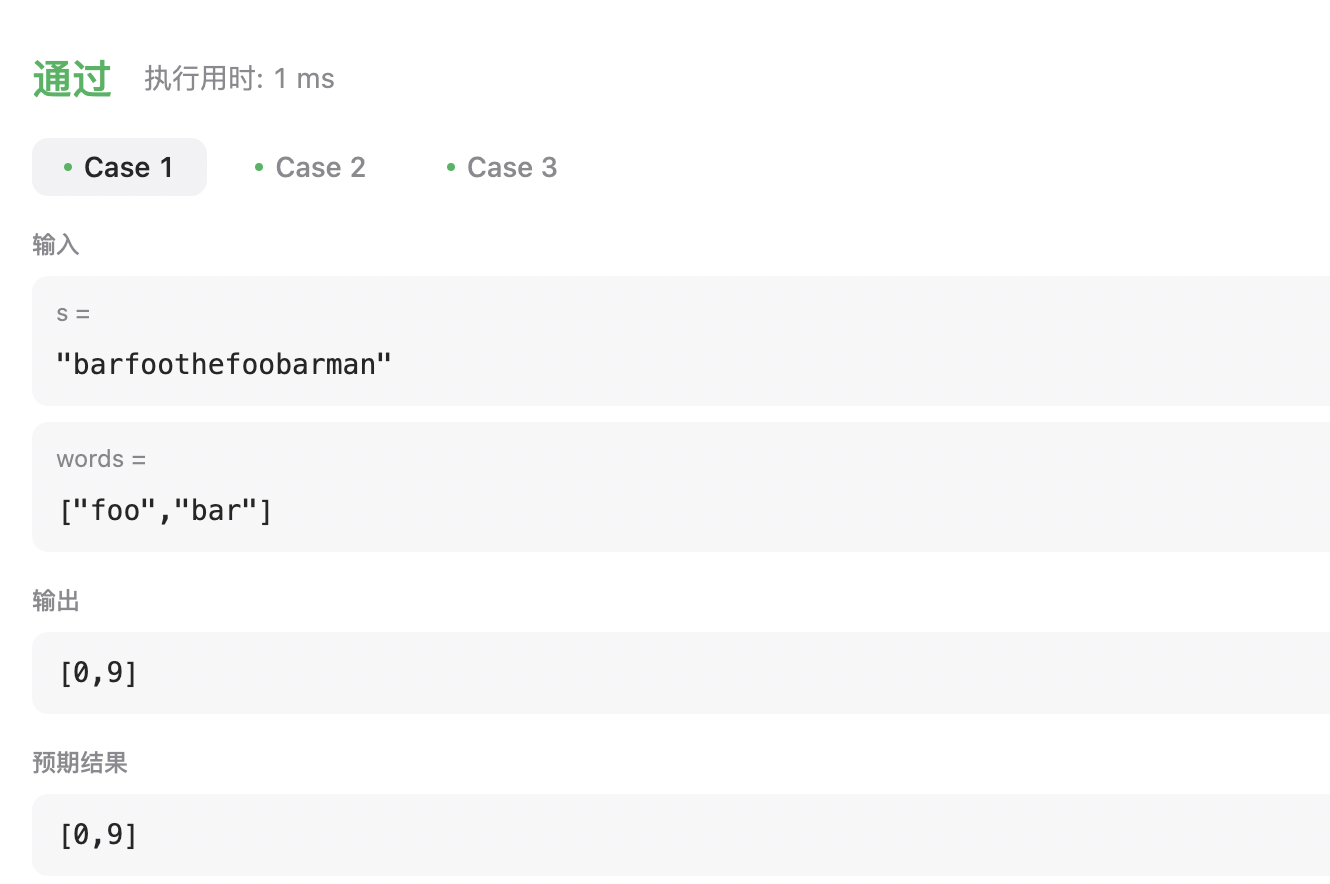
输入:s = "barfoothefoobarman", words = ["foo","bar"]
输出:[0,9]
解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。
子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。
输出顺序无关紧要。返回 [9,0] 也是可以的。
示例 2:
输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
输出:[]
解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。 所以我们返回一个空数组。
示例 3:
输入:s = "barfoofoobarthefoobarman", words = ["bar","foo","the"]
输出:[6,9,12]
解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。
子串 "foobarthe" 开始位置是 6。它是 words 中以 ["foo","bar","the"] 顺序排列的连接。
子串 "barthefoo" 开始位置是 9。它是 words 中以 ["bar","the","foo"] 顺序排列的连接。
子串 "thefoobar" 开始位置是 12。它是 words 中以 ["the","foo","bar"] 顺序排列的连接。
提示:
- 1 < = s . l e n g t h < = 1 0 4 1 <= s.length <= 10^4 1<=s.length<=104
- 1 < = w o r d s . l e n g t h < = 5000 1 <= words.length <= 5000 1<=words.length<=5000
- 1 < = w o r d s [ i ] . l e n g t h < = 30 1 <= words[i].length <= 30 1<=words[i].length<=30
- w o r d s [ i ] words[i] words[i] 和 s s s 由小写英文字母组成
暴力递归解法
- 递归计算出字符串数组
words的所有的串联子串。 - 假如
words中的每个单词长度为k,子串长度为 n = k ∗ w o r d s . l e n g t h n = k * words.length n=k∗words.length。根据下标遍历字符串s, 每次截取n个字符,如果截取的字符串包含于第一步计算出的子串列表,则将当前下标计入答案。
详细见代码实现,很容易理解。
Java 代码实现
class Solution {
// 每个单词的长度
private int k = 0;
// 串联子串长度
private int n = 0;
// 记录所有串联子串
private Set<String> subStrs = new HashSet<>();
// 记录已经访问过的位置
private Set<Integer> visited = new HashSet<>();
// 记录字符串拼接
private StringBuilder sb = new StringBuilder();
public List<Integer> findSubstring(String s, String[] words) {
k = words[0].length();
n = words.length * k;
// 1. 先找出所有的串联子串
recursion(words);
// 2. 用串联子串和字符串s匹配,获取下标
List<Integer> ans = new ArrayList<>();
for(int i = 0; i <= s.length() - n; i++){
String subStr = s.substring(i, i + n);
if(subStrs.contains(subStr)){
ans.add(i);
}
}
return ans;
}
// 递归
private void recursion(String[] words){
int m = visited.size();
if(m == words.length){
subStrs.add(sb.toString());
return;
}
for(int i = 0; i < words.length; i++){
if(visited.contains(i)){
continue;
}
visited.add(i);
sb.append(words[i]);
recursion(words);
visited.remove(i);
sb.delete(sb.length() - k, sb.length());
}
}
}
暴力解法在数据量小的情况下是可以的。
数据量大了就会超时。

哈希表解法
其实我们可以不用计算出 words 数组的所有子串,因为题目给定 串联子串 是以 任意顺序 排列连接起来的。
既然和顺序没有有关系,那么可以断定:如果一个字符串中的每个单词出现的次数和 words 数组中每个单词出现的次数相同,那么这个字符串一定是 words 数组的众多串联子串中的一个。
所以我们的思路为:
- 对
words数组中的单词计数。 - 假如串联子串的长度为
n。我们可以遍历给定字符串s,每n个字符截取一个子串subStr,然后对subStr中的单词计数。 - 如果
subStr的单词计数和words数组的单词计数一样,那么subStr就是一个串联子串,记录其起始位置。
关于单词计数,可以使用 哈希表 这个数据结果,key 为单词本身,value 为这个单词出现的次数。
Java 代码实现
class Solution {
// 单词计数
private Map<String, Integer> wordsCount = new HashMap<String, Integer>();
public List<Integer> findSubstring(String s, String[] words) {
// 单词计数
for(int i = 0; i < words.length; i++){
int val = wordsCount.getOrDefault(words[i], 0);
wordsCount.put(words[i], val + 1);
}
// 一个单词的长度
int k = words[0].length();
// 总字符串长度
int n = k * words.length;
List<Integer> ans = new ArrayList<>();
// 滑动窗口中的子串单词计数
Map<String, Integer> tempCount = new HashMap<>();
for(int i = 0; i <= s.length() - n; i++){
String subStr = s.substring(i, i + n);
if(invalid(subStr, tempCount, k)){
ans.add(i);
}
// 用完了就清空,以便重复使用
tempCount.clear();
}
return ans;
}
private boolean invalid(String str, Map<String, Integer> tempCount, int k) {
for(int i = 0; i <= str.length() - k; i = i + k){
String word = str.substring(i, i + k);
tempCount.put(word, tempCount.getOrDefault(word, 0) + 1);
}
return equalsMap(tempCount, wordsCount);
}
// 判断两个计数的Map是否相等。
private boolean equalsMap(Map<String, Integer> a, Map<String, Integer> b){
if(a == null && b == null){
return true;
}else if(a == null && b != null){
return false;
}else if(a != null & b == null){
return false;
}
if(a.isEmpty() && b.isEmpty()){
return true;
}
if(a.size() != b.size()){
return false;
}
for(String key: a.keySet()){
if(!a.get(key).equals(b.get(key))){
return false;
}
}
return true;
}
}

滑动窗口 + 哈希表解法
上一个解法中每次对子串中的单词计数都是重新计算的,这里是一个优化点。
我们可以将 n 个字符长度的子串看作是一个滑动窗口,每次向后滑动一个单词( k 个字符),那么我们只需要将前面移出去的单词个数减一,后面移动到窗口内部的单词个数加一,中间的其他单词个数因为没有变所以就无需再重新计算了。
Java 代码实现
class Solution {
// 单词计数
private Map<String, Integer> wordsCount = new HashMap<String, Integer>();
public List<Integer> findSubstring(String s, String[] words) {
List<Integer> ans = new ArrayList<>();
// 一个单词的长度
int k = words[0].length();
// 单词个数
int c = words.length;
// 总字符串长度
int n = k * c;
if(s.length() < n){
return ans;
}
// 单词计数
for(int i = 0; i < c; i++){
int val = wordsCount.getOrDefault(words[i], 0);
wordsCount.put(words[i], val + 1);
}
// 滑动窗口中的子串单词计数
Map<String, Integer> tempCount = new HashMap<>();
for(int i = 0; i < k; i++){
tempCount.clear();
// 每次滑动一个单词,单词长度为k
int left = i, right = left + n;
if(right > s.length()){
break;
}
// 对窗口中的字符串单词计数
String subStr = s.substring(left, right);
for(int j = 0; j <= n - k; j = j + k){
String word = subStr.substring(j, j + k);
tempCount.put(word, tempCount.getOrDefault(word, 0) + 1);
}
if(equalsMap(wordsCount, tempCount)){
ans.add(left);
}
// 滑动窗口
while(right + k <= s.length()){
// 前面移出去一个单词
String rmWord = s.substring(left, left + k);
int val = tempCount.get(rmWord);
if(val == 1){
tempCount.remove(rmWord);
}else{
tempCount.put(rmWord, val - 1);
}
left = left + k;
// 后面移进去一个单词
String newWord = s.substring(right, right + k);
tempCount.put(newWord, tempCount.getOrDefault(newWord, 0) + 1);
right = right + k;
if(equalsMap(wordsCount, tempCount)){
ans.add(left);
}
}
}
return ans;
}
// 判断两个计数的Map是否相等。
private boolean equalsMap(Map<String, Integer> a, Map<String, Integer> b){
if(a == null && b == null){
return true;
}else if(a == null && b != null){
return false;
}else if(a != null & b == null){
return false;
}
if(a.isEmpty() && b.isEmpty()){
return true;
}
if(a.size() != b.size()){
return false;
}
for(String key: a.keySet()){
if(!a.get(key).equals(b.get(key))){
return false;
}
}
return true;
}
}

















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











