






代码关键词:需求响应 强化学习 动态定价
编程语言:python平台
主题:16、基于强化学习(Q-learning算法)的需求响应动态定价研究
代码内容:
代码提出了一种考虑服务提供商(SP)利润和客户(CUs)成本的分层电力市场能源管理动态定价DR算法。
用强化学习(RL)描述了动态定价问题为离散有限马尔可夫决策过程(MDP)的递阶决策框架,并采用Q学习来求解该决策问题。
在在线学习过程中,利用RL,SP可以自适应地确定零售电价,其中考虑了用户负荷需求曲线的不确定性和批发电价的灵活性。
仿真结果表明,本文提出的DR算法能够提高SP的盈利能力,降低CUs的能源成本,平衡电力市场的能源供需,提高电力系统的可靠性,是SP和CUs双赢的策略
复现lunwen题目:A Dynamic pricing demand response algorithm for smart grid: Reinforcement learning approach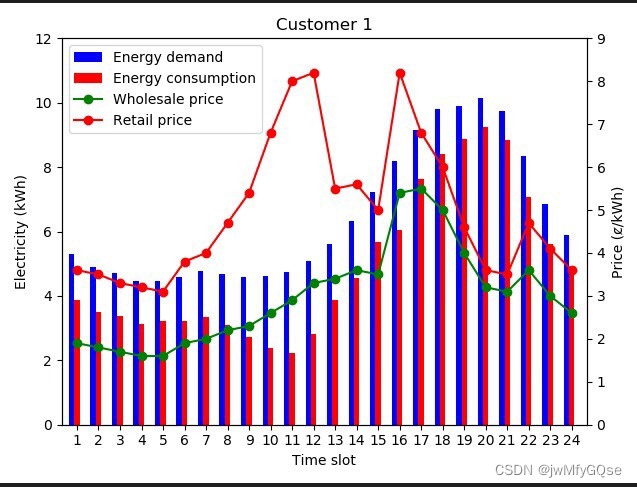

基于强化学习(Q-learning算法)的需求响应动态定价研究 —— 以分层电力市场能源管理为例
随着智能电网技术的不断发展,电力市场呈现出分层竞争、灵活性和智能化等诸多特点,其中动态定价已成为电力市场监管的热点问题。然而,在分层电力市场中实现动态定价并不是一件容易的事情。因为在不同层次的电力市场参与者(供应商、分销商、能源管理者和终端用户)之间存在复杂的关系,不同层次的参与者之间往往存在利益冲突,如何平衡供需关系并实现供应商和客户的双赢是一个亟待解决的问题。
本文提出了一种基于强化学习的需求响应动态定价DR算法,该算法通过考虑服务提供商(SP)利润和客户成本,实现了动态定价策略的优化。在此过程中,我们采用了Q-learning算法来求解该决策问题,以自适应地确定零售电价,并考虑了用户负荷需求曲线的不确定性和批发电价的灵活性。算法设计为离散有限马尔可夫决策过程(MDP)的递阶决策框架,利用强化学习(RL)描述了动态定价问题。
实验结果表明,本文提出的DR算法能够提高SP的盈利能力,降低CUs的能源成本,平衡电力市场的能源供需,提高电力系统的可靠性,确保SP和CUs双赢的策略。同时,我们还通过仿真实验验证了DR算法的有效性和性能。
在实现需求响应动态定价的过程中,我们的算法主要包括以下几个方面的内容:
- 电力市场模型的建立
本文建立了一个分层电力市场模型,包括整个电力系统的参与者、成本、收益和市场机制等方面的内容。电力系统中的参与者包括供应商、分销商、能源管理者和终端用户等,按照其参与电力市场的层次划分为基础层、中间层和顶层。此外,该模型还考虑了物理约束、电力质量和市场机制等因素,建立了一个完整的电力市场模型。
- Q-learning算法及递阶决策框架
本文利用Q-learning算法描述了动态定价问题为离散有限马尔可夫决策过程(MDP)的递阶决策框架。Q-learning算法是一种基于价值函数的单智能体强化学习方法,其能够通过不断地采用最优策略来更新价值函数和策略。在递阶决策框架下,本文将动态定价问题分解成多个决策阶段,每个决策阶段对应一个Q-learning过程。
- DR算法的实现
本文提出了一种基于需求响应原理的DR算法,其主要思路是在用户需求不变的情况下,通过调节电价来实现能源的平衡供需。为了实现DR策略的优化,我们通过强化学习算法来确定合适的零售电价。在在线学习的过程中,我们考虑了用户负荷需求曲线的不确定性和批发电价的灵活性,通过模拟仿真得到了Q-learning算法的最优策略。
实验结果表明,本文提出的DR算法在实现动态定价方面具有较好的效果。该算法能够提高SP的盈利能力、降低CUs的能源成本、平衡电力市场的能源供需以及提高电力系统的可靠性。因此,本文提出的基于强化学习(Q-learning算法)的需求响应动态定价DR算法在实现电力市场的动态定价方面具有广泛的应用前景。
相关代码,程序地址:http://lanzouw.top/692877864074.html


















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









