







查找
查找:根据某个给定值在序列中查找,找到一个关键字等于给定值的数据元素或记录。
| 查找 | 期望时间复杂度 | 最坏时间复杂度 |
|---|---|---|
| 顺序 | ||
| 二分 | ||
| 差值 | ||
| 斐波那契 | ||
| 分块 | ||
| 哈希 |
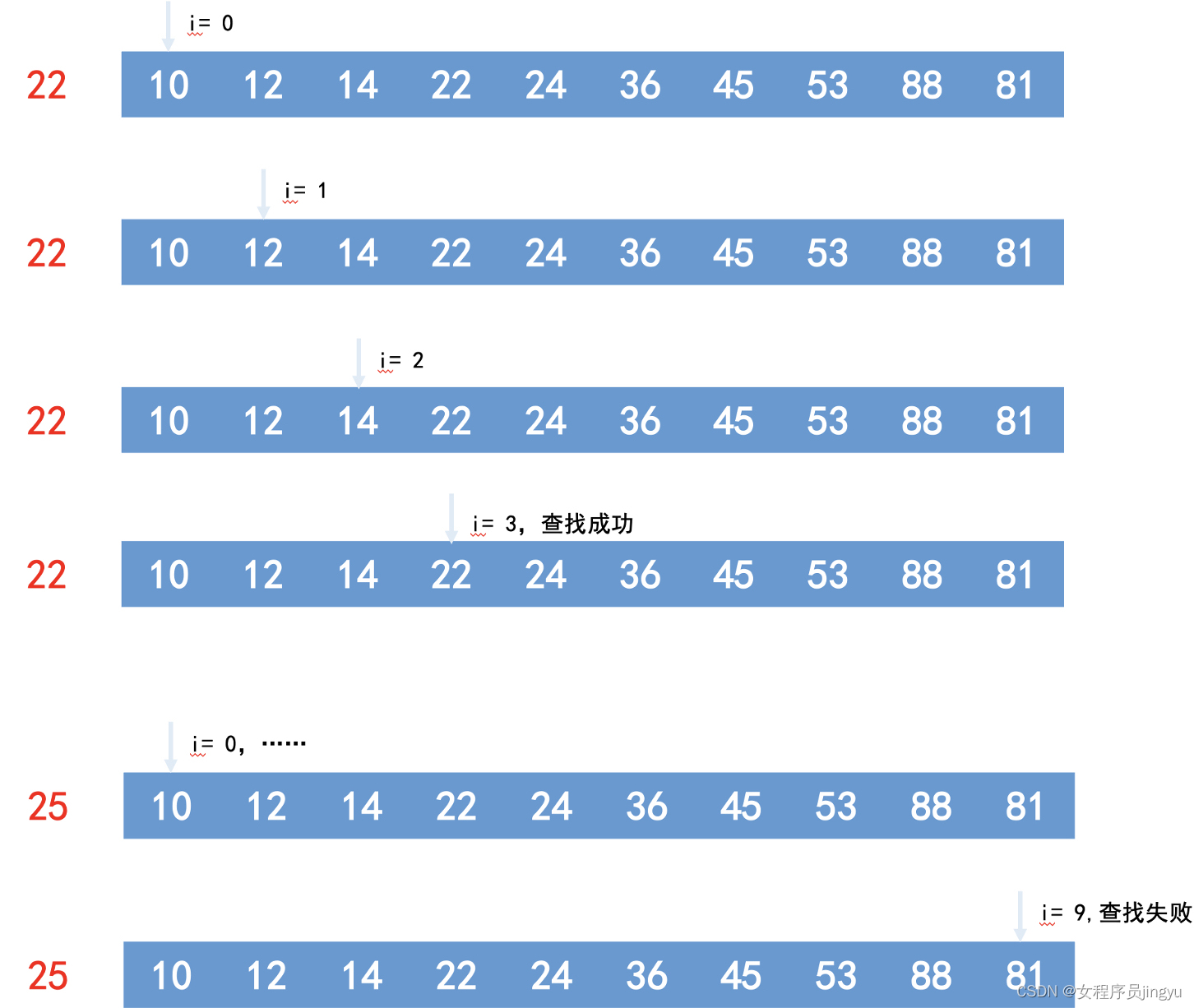
顺序查找
算法描述
- 无序列表,给定元素k,从线性表一端开始顺序扫描;
- 依次对比扫描到的关键字和给定元素k,如果相等则查找成功;
- 如果扫描到结尾无相等,则查找失败。
算法图解
算法伪代码--c++
#include <iostream>
using namespace std;
template<typename T>
int sequentialQuery(std::vector<T>& arr, int len, int target) {
if (low == high) {
if (arr[low] == target) {
return low;
} else {
return -1;
}
}
for (int i = 0; i < len; i++) {
if (arr[i] == target) {
return i;
}
}
}
二分查找
算法描述
- 有序列表长度为len,给定值k,最左边元素索引为low,最右边元素索引为high;
- mid = (low + high) / 2,k先和mid位关键字比较;
- 如果相等查找成功;
- 如果k大于mid位关键字,则在{mid + 1, high}继续查找;
- 如果k小于mid位关键字,则在{low, mid - 1}继续查找。
算法图解

算法伪代码--c++
#include <iostream>
using namespace std;
template<typename T>
int binaryQuery(std::vector<T>& arr, int len, int target) {
int low = 0;
int high = len - 1;
if (low == high) {
if (arr[low] == target) {
return low;
} else {
return -1;
}
}
while (low <= high) {
int mid = (low + high) / 2;
if (target == array[mid]) {
return mid;
}
if (target > array[mid]) {
low = mid + 1;
}
if (target < array[mid]) {
high = mid - 1;
}
}
return -1;
}插值查找
算法描述
- 有序列表arr,长度为len,给定值k,最左边元素索引为low,最右边元素索引为high;
,k先和mid位关键字比较;
- 如果相等查找成功;
- 如果k > arr[mid],则在{mid + 1, high}继续查找;
- 如果k < arr[mid],则在{low, mid - 1}继续查找。
算法图解

算法伪代码--c++
#include <iostream>
using namespace std;
template<typename T>
int interpolationQuery(std::vector<T>& arr, int len, int target) {
int low = 0;
int high = len - 1;
if (low == high) {
if (arr[low] == target) {
return low;
} else {
return -1;
}
}
while (low <= high) {
int mid = (high - low) * (key - arr[low]) / (arr[high] - arr[low]);
if (target == arr[low + mid]) {
return mid;
}
if (target > arr[low + mid]) {
low = mid + 1;
}
if (target < arr[low + mid]) {
high = mid - 1;
}
}
return -1;
}斐波那契查找
先验知识
- 黄金分割:将一个整体一分为二,较小部分 / 较大部分 = 较大部分 / 整体 = 0.618 / 1。
- 斐波那契序列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89……. ;即从第3个数开始,后一个数是前两个数的和,即F[k] = F[k - 1] + F[k - 2] ;随着序列递增,前后两个数的比值越来越接近0.618。
算法描述
- 有序列表arr,长度为F[k] ,给定值k,k与F[k - 1] 位置(mid = low + F[k - 1] - 1)元素比较;
- 如果k == arr[mid],返回mid;
-
如果k > arr[mid],low = mid + 1,k-=2,返回mid。备注:k -= 2即在[mid + 1, high]内元素个数为n - F[k - 1] = F[k] - 1 - F[k - 1] = F[k] - F[k - 1] - 1 = F[k - 2] - 1个;
-
如果k < arr[mid],high = mid - 1,k -= 1。备注:k -= 1即在[low, mid - 1]内,元素个数为F[k - 1] - 1个。
算法图解

算法伪代码--c++
#include <iostream>
using namespace std;
template<typename T>
int fibQuery(std::vector<T>& arr, int len, int target) {
int low = 0;
int high = len - 1;
if (low == high) {
if (arr[low] == target) {
return low;
} else {
return -1;
}
}
// 构造斐波那契数列拷贝给arr
std::vector<T> f = std:vector<T>(len, 0);
f[0] = 1;
f[1] = 2;
for (int i = 2; i < len; ++i) {
f[i] = f[i - 1] + f[i - 2];
}
for (int i = 0; i < len; ++i) {
arr[i] = f[i];
}
// 查找
int low = 0;
int high = len - 1;
while (low <= high) {
int mid = low + arr[len - 1] - 1;
if (target == arr[mid]) {
return mid;
} else if (target > arr[mid]) {
low = mid + 1;
len = len - 2;
} else {
high = mid - 1;
len = len - 1;
}
}
return -1;
}树表查找
二叉树算法描述
- 每个结点最多有两个子结点;
- 若任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若任意结点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意结点的左、右子树也分别为二叉查找树;
- 二叉树中序遍历则为有序列表。
- 第i层上最多有2i-1 个节点;深度为k,那么最多有2k-1个节点;n个节点的完全二叉树的深度为[log2n]+1
二叉树遍历
-
前序遍历: 根->左子树->右子树
-
中序遍历: 左子树->根->右子树
-
后序遍历; 左子树->右子树->根
二叉树算法图解

二叉树算法伪代码--c++
#include <time.h>
#include <iostream>
#include <queue>
#include <string>
#include<algorithm>
using namespace std;
template <class T>
class BSTNode {
public:
T key; // 关键字(键值)
BSTNode *left; // 左孩子
BSTNode *right; // 右孩子
BSTNode *parent;// 父结点
BSTNode(T value, BSTNode *p, BSTNode *l, BSTNode *r):
key(value),parent(),left(l),right(r) {}
};
template <class T>
class BSTree {
private:
BSTNode<T> *mRoot; // 根结点
public:
BSTree();
~BSTree();
// 前序遍历"二叉树"
void preOrder();
// 中序遍历"二叉树"
void inOrder();
// 后序遍历"二叉树"
void postOrder();
// (递归实现)查找"二叉树"中键值为key的节点
BSTNode<T>* search(T key);
// 查找最小结点:返回最小结点的键值。
T minimum();
void insert(T key);
void remove(T key);
void destroy();
void print();
private:
void preOrder(BSTNode<T>* tree) const;
void inOrder(BSTNode<T>* tree) const;
void postOrder(BSTNode<T>* tree) const;
BSTNode<T>* search(BSTNode<T>* x, T key) const;
BSTNode<T>* minimum(BSTNode<T>* tree);
void insert(BSTNode<T>* &tree, BSTNode<T>* z);
BSTNode<T>* remove(BSTNode<T>* &tree, BSTNode<T> *z);
void destroy(BSTNode<T>* &tree);
void print(BSTNode<T>* tree, T key, int direction);
};
template <class T>
void BSTree<T>::preOrder(BSTNode<T>* tree) const {
if(tree != NULL) {
cout<< tree->key << " " ;
preOrder(tree->left);
preOrder(tree->right);
}
}
template <class T>
void BSTree<T>::preOrder() {
preOrder(mRoot);
}
template <class T>
void BSTree<T>::postOrder(BSTNode<T>* tree) const
{
if(tree != NULL)
{
postOrder(tree->left);
postOrder(tree->right);
cout<< tree->key << " " ;
}
}
template <class T>
void BSTree<T>::postOrder() {
postOrder(mRoot);
}
template <class T>
BSTNode<T>* BSTree<T>::search(BSTNode<T>* x, T key) const {
if (x==NULL || x->key==key)
return x;
if (key < x->key)
return search(x->left, key);
else
return search(x->right, key);
}
template <class T>
BSTNode<T>* BSTree<T>::search(T key) {
search(mRoot, key);
}
template <class T>
BSTNode<T>* BSTree<T>::maximum(BSTNode<T>* tree) {
if (tree == NULL)
return NULL;
while(tree->right != NULL)
tree = tree->right;
return tree;
}
template <class T>
T BSTree<T>::maximum() {
BSTNode<T> *p = maximum(mRoot);
if (p != NULL)
return p->key;
return (T)NULL;
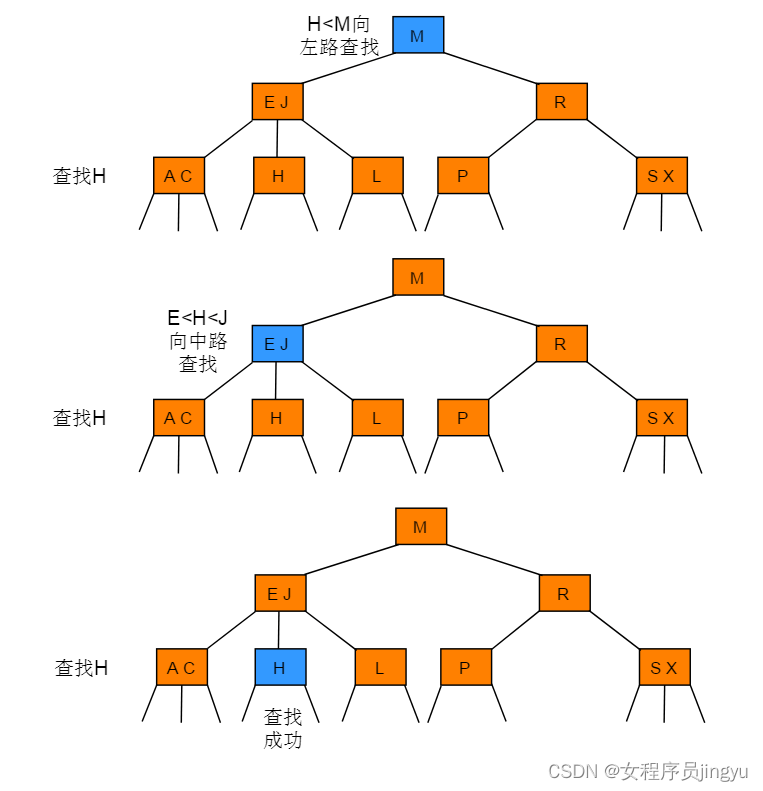
}2-3查找树算法描述
- 要么为空
- 2-node:保存1个key及对应value,保存2个子结点,子结点也是2-3节点;左子结点所有值都比key小,右结点所有值比key大。
- 3-node:保存2个key及对应value,保存3个子结点,子结点也是2-3结点。左子结点所有值均比两个key中的最小key小;中间结点的key值在两个跟结点key值之间;右结点所有值比两个key中的最大的key大。
- 中序遍历则为有序列表。
2-3查找树算法图解
2-3查找树算法伪代码--c++
#include <time.h>
#include <iostream>
#include <queue>
#include <string>
#include<algorithm>
using namespace std;
class TerNode<E extends Comparable<E>> {
static final int capacity = 2;
List<E> items;
List<TerNode<E>> branches;
TerNode<E> parent;
factory TerNode(List<E> elements) {
if (elements.length > capacity) throw StateError('too many elements.');
return TerNode._internal(elements);
}
TerNode._internal(List<E> elements)
: items = [],
branches = [] {
items.addAll(elements);
}
int get size => items.length;
bool get isOverflow => size > capacity;
bool get isLeaf => branches.isEmpty;
bool get isNotLeaf => !isLeaf;
bool contains(E value) => items.contains(value);
int find(E value) => items.indexOf(value);
String toString() => items.toString();
}
class TernaryTree<E extends Comparable<E>> {
TerNode<E> _root;
int _elementsCount;
factory TernaryTree.of(Iterable<Comparable<E>> elements) {
var tree = TernaryTree<E>();
for (var e in elements) tree.insert(e);
return tree;
}
TernaryTree() : _elementsCount = 0;
}
TerNode<E> find(E value) {
var c = root;
while (c != null) {
var i = 0;
while (i < c.size && c.items[i].compareTo(value) < 0) i++;
if (i < c.size && c.items[i] == value) break;
c = c.isNotLeaf ? c.branches[i] : null;
}
return c;
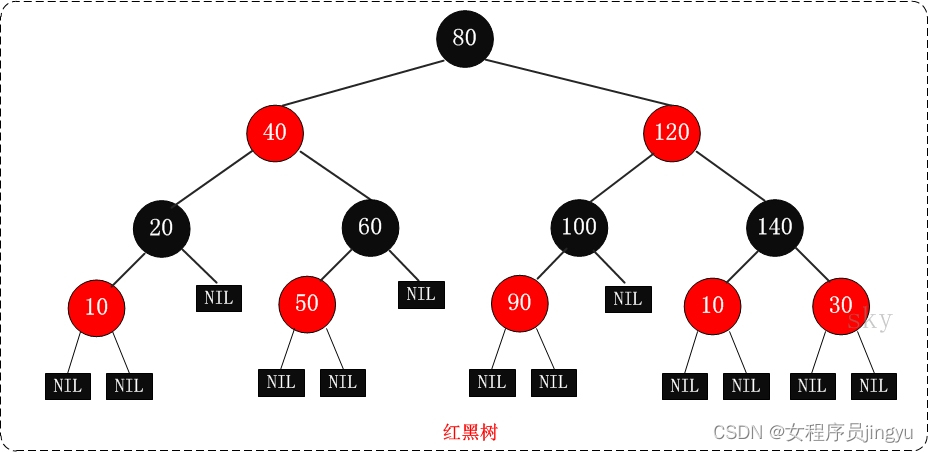
}红黑树算法描述
- 根结点是黑色;
- 其余结点要么黑色,要么红色;
- 每个叶子结点是黑色。 注意:这里是为空的叶子结点;
- 如果一个结点是红色,则它的子结点必须是黑色;
- 从1个结点到该结点的子孙结点的所有路径上,包含相同数目的黑结点。
红黑树算法图解
红黑树算法伪代码--c++
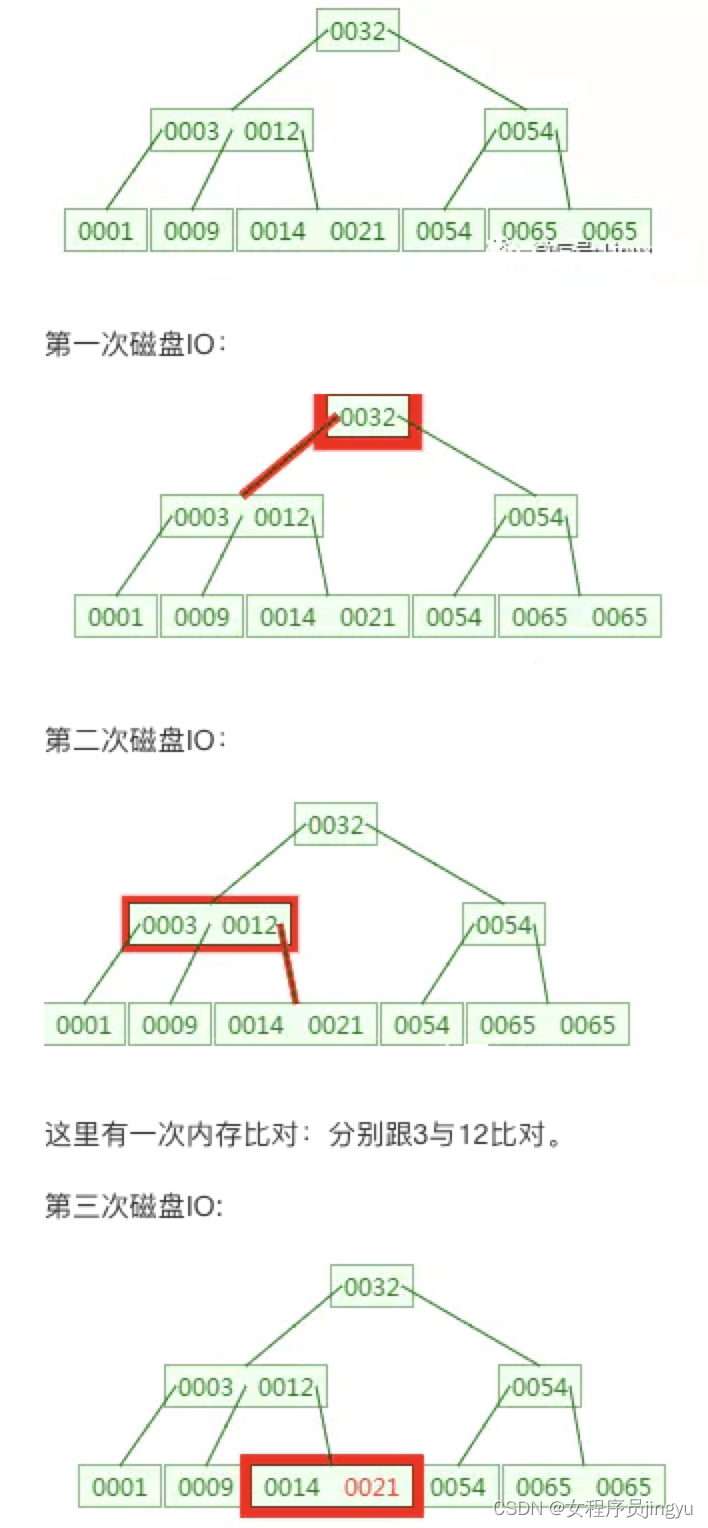
B树B+树算法描述
-
m阶B树:每个结点最多有m个分支,即每个结点最多m - 1个关键字;
-
根结点最少有1个关键字,其他结点最少ceil(m / 2) 个关键字;
-
每个结点内,n为关键字个数,Ki为关键字,Pi为父结点,其指向关键字满足[Ki, Ki + 1]。
-
m阶B树:每个结点最多有m个分支,即每个结点最多m个关键字;
-
非叶子结点只有当行信息,无实际值,其他结点最少ceil(m / 2) 个关键字;
-
每个结点内,n为关键字个数,Ki为关键字,Pi为父结点,其指向关键字满足(Ki, Ki + 1]或[Ki, Ki + 1);
-
关键字都在叶子结点,叶子结点增加链指针,所有叶子结点链起来。
B树算法图解
![]()
B+树算法图解

B树B+树算法伪代码--c++
C/C++后台开发学习笔记(八)-B树、B+树(详细完整版) - 知乎
分块查找
算法描述
- 给定值k,选取各块中最大关键字构成索引表;
- 对索引表进行二分查找或顺序查找, 目的是确定k在哪一块
- 在已确定块中,顺序查找k。
算法图解

算法伪代码--c++
#include <iostream>
using namespace std;
class BlockInfo {
public:
int start;
int end;
int max_value;
}
template<typename T>
int blockQuery(BlockInfo* blocks, std::vector<T>& arr, int target, int blocks_num) {
int key_block = 0;
int flag = 0;
for (int i = 0; i < blocks_num; ++i) {
if (target <= blocks[i].max_value) {
key_block = i;
flag = 1;
break;
}
}
if (flag == 0) {
return -1;
}
flag = 0;
for (int i = blocks[key_block].start; i <= blocks[key_block].end; i++) {
if (arr[i] == target) {
flag = 1;
return i;
}
}
if (flag == 0) {
return -1;
}
}哈希查找
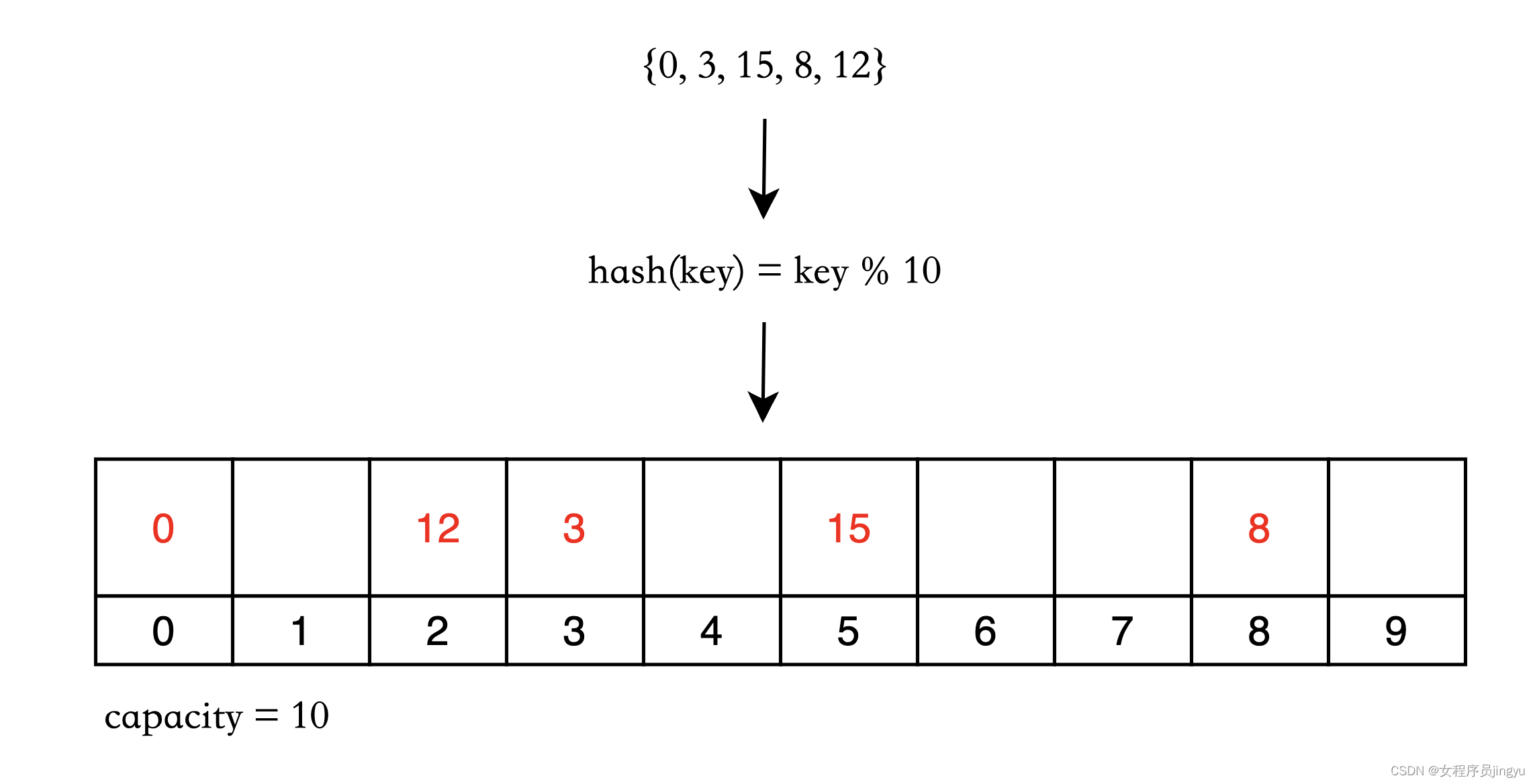
先验知识
哈希表:键值对存储的数据结构,可以根据关键字key直接访问value。
哈希函数:将关键字映射到列表位置的算法。
哈希算法:直接定址法H(key)= a * key + b;除留余数法H(key)= key % p(p为小于或等于列表长度的质数);数字分析法;平方取中法。
哈希冲突:线性探测;平方探测;拉链法。
算法描述
- 给定值k,给定哈希函数构造哈希表;
- 选择冲突处理法(拉链法、线性探测法等)解决地址冲突;
- 在哈希表的基础上执行哈希查找。
算法图解
算法伪代码--c++
#include <iostream>
using namespace std;
template<class K, class V>
struct HashData {
pair<K, V> _kv;
State _state = EMPTY;
};
template<class K, class V>
class HashTable {
public:
HashTable(size_t size) {};
private:
vector<HashData<K, V>> _table; // 哈希表
size_t _n = 0; // 负载因子
};
template<typename T>
HashData<K, V> * hashQuery(const K& key, HashTable<K, V>& hash_table) {
if (hash_table.size() == 0)
{
return nullptr;
}
HashData hash;
size_t size = hash_table.size();
size_t start = hash(key) % size; // 根据key值通过哈希函数得到下标值
size_t hash_id = start;
while (hash_table[hash_id]._state != EMPTY) {
if (hash_table[hash_id]._state != DELETE && hash_table[hash_id]._kv.first == key) {
return &hash_table[hash_id];
}
hash_id++;
hash_id %= size;
if (hash_id == start) {
break;
}
}
return nullptr;
}














 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









